Over the last 3 years, I’ve worked as a UX design intern at 2 independent advertising agencies and a famous product company based in Australia. As a passionate and young beginner, I learned how to be open to different perspectives—and how I actually didn’t know anything at all.
This list is a culmination of the important lessons I picked up along the way. I hope this helps you in your own path as a designer, as I continue to tread mine. Enjoy!
Design isn’t about how things look—it’s a plan, strategy, and an execution.
Appreciate the small details. Things like whitespace, padding, and consistent iconography go a long way.
Most UI redesigns are done without the context of business goals or user needs, goals, and motivations. They’re just there for eye candy.
Research methods are your best bet to an informed design.
Qualitative data provides context to quantitative data—these are partners in crime.
Presenting findings is part of the job.
The term “user experience” is ambiguous—people have different conceptions, definitions, and meanings for it. I think it’s about making products and services easier and delightful to use.
Articulating design decisions is important so your stakeholders can trust you.
Just create an MVP and test it out. You’ll learn along the way.
Bureaucracy brackets the growth of UX in traditional organizations.
Your portfolio should show your thought process more than the final “look” of the product.
Psychology is deeply intertwined with UX. Learning it will give you an edge.
UX designers need to come up with solutions that not only look good, but have a solid research foundation.
Your formal education won’t be able to keep up with the industry, so curate your own design education. (Though, it’s worth noting that thinking critically, negotiating, presenting ideas, and doing research are essential skills to be learned while you’re in school. These are skills important to a UX designer.)
Design systems make prototyping faster, but they’re hard to maintain.
Gestalt principles, Occam’s razor, and Fitts’s Law for UI design solve most UX problems.
The best companies in the world hire UX designers because they inevitably bring in more profit in return.
Hiring a UX designer is cost effective. What will happen to your time and resources when you find out people wouldn’t use your product? So hire a UX designer.
UX is more than just building apps or websites. It’s about representing the user in the whole design process.
Keep track of all the new tools and find the ones that help you do your job best.
Personas can inform design. Base them on real data.
Educating clients and stakeholders about UX is part of the job. Not doing so will cause you more headaches in the long run.
You appreciate how architects design physical spaces and how they care deeply for their users.
People have a wide range of emotions, motivations, and perceptions that can influence how they see your brand—ultimately affecting the product as well.
There are tons of UX resources out there. It’s easy to find them and learn the various methods and tools. The hard part is actually applying them to specific business situations and contexts.
If you’re the lone UX wolf at your organization, it’s your job to get others on board with design.
Go to more meetups. Meet more people. Listen and learn. Connect with people you look up to. That’s one of the best ways to learn.
Alexis Collado Alexis Collado has interned for award-winning companies such as Jump Digital Asia, Freelancer.com, and NuWorks Interactive Labs—usually being the first UX Design intern. He had been passionate about web design and user experience ever since high school, so he founded User Experience Society — the first student organization of aspiring UX and product designers in the Philippines. Alexis is relentless in seeking challenging opportunities that push his knowledge and talents to the limit. You can reach him at alexis.collado@uxsociety.ph.
Cal Newport is a busy man: He’s an associate professor of computer science at Georgetown University, the author of several successful books and also runs a widely-read blog.
But you won’t find Newport tweeting about his work or sharing it on Facebook.
Why not?
Because he believes it’s a waste of time. More specifically, he argues social media reduces anyone’s ability to produce something of value.
“The ability to concentrate without distraction on hard tasks is becoming increasingly valuable in an increasingly complicated economy. Social media weakens this skill because it’s engineered to be addictive. The more you use social media in the way it’s designed to be used–persistently throughout your waking hours–the more your brain learns to crave a quick hit of stimulus at the slightest hint of boredom.
Once this Pavlovian connection is solidified, it becomes hard to give difficult tasks the unbroken concentration they require, and your brain simply won’t tolerate such a long period without a fix. Indeed, part of my own rejection of social media comes from this fear that these services will diminish my ability to concentrate — the skill on which I make my living.
The idea of purposefully introducing into my life a service designed to fragment my attention is as scary to me as the idea of smoking would be to an endurance athlete, and it should be to you if you’re serious about creating things that matter.”
Newport acknowledges that this claim runs counter to our current understanding of social media’s role in the professional world. Many say maintaining your brand on Facebook, Twitter and Instagram is vital to gaining access to opportunities you might otherwise miss and helps you build the diverse contact network you need to get ahead.
But Newport argues this behavior is misguided. “Social media use is decidedly not rare or valuable,” he writes. “Any 16-year-old with a smartphone can invent a hashtag or repost a viral article. The idea that if you engage in enough of this low-value activity, it will somehow add up to something of high value in your career is the same dubious alchemy that forms the core of most snake oil and flimflam in business.”
What should you do instead?
Newport quotes Steve Martin, who often advised aspiring entertainers: “Be so good they can’t ignore you.”
“The foundation to achievement and fulfillment, almost without exception, requires that you hone a useful craft and then apply it to things that people care about, writes Newport. “If you do that, the rest will work itself out, regardless of the size of your Instagram following.”
My Experience
There’s a lot of truth to Newport’s opinion.
As one who’s active on Twitter and LinkedIn, I’ve found certain benefits–but those benefits are often outweighed by the negative. I’ve also seen firsthand the power of social media–but not from my own accounts. The more I’m focused on producing something of value–which I attempt through my writing–the more others share my work…and the more opportunities come to me.
Some argue that you need to take control of your brand, lest others do it for you. But that’s not true: The best brands are those we find to be authentic and transparent, not some type of fabricated image. If you focus on creating value, your message will spread.
And people will always come back to the source.
As a caveat to this advice, I’ve cultivated a number of mutually beneficial relationships that began on social media. For that reason, I don’t plan on quitting outright.
However, Newport’s essay has inspired me to reevaluate how I use social media–and to make sure I’m maximizing the use of my time.
Because when it comes to doing great work, every second counts.
from Inc.com http://www.inc.com/justin-bariso/a-successful-millennial-explains-the-number-one-reason-you-need-to-quit-social-m.html
This is the first part of ‘A Brief History of Neural Nets and Deep Learning’. Part 2 is here, and parts 3 and 4 are here and here. In this part, we shall cover the birth of neural nets with the Perceptron in 1958, the AI Winter of the 70s, and neural nets’ return to popularity with backpropagation in 1986.
Prologue: The Deep Learning Tsunami
“Deep Learning waves have lapped at the shores of computational linguistics for several years now, but 2015 seems like the year when the full force of the tsunami hit the major Natural Language Processing (NLP) conferences.” –Dr. Christopher D. Manning, Dec 2015
This may sound hyperbolic – to say the established methods of an entire field of research are quickly being superseded by a new discovery, as if hit by a research ‘tsunami’. But, this catastrophic language is appropriate for describing the meteoric rise of Deep Learning over the last several years – a rise characterized by drastic improvements over reigning approaches towards the hardest problems in AI, massive investments from industry giants such as Google, and exponential growth in research publications (and Machine Learning graduate students). Having taken several classes on Machine Learning, and even used it in undergraduate research, I could not help but wonder if this new ‘Deep Learning’ was anything fancy or just a scaled up version of the ‘artificial neural nets’ that were already developed by the late 80s. And let me tell you, the answer is quite a story – the story of not just neural nets, not just of a sequence of research breakthroughs that make Deep Learning somewhat more interesting than ‘big neural nets’ (that I will attempt to explain in a way that just about anyone can understand), but most of all of how several unyielding researchers made it through dark decades of banishment to finally redeem neural nets and achieve the dream of Deep Learning.
I am in no capacity an expert on this topic. In depth technical overviews with long lists of references written by those who actually made the field what it is include Yoshua Bengio’s "Learning Deep Architectures for AI", Jürgen Schmidhuber’s "Deep Learning in Neural Networks: An Overview" and LeCun et al.s’ "Deep learning". In particular, this is mostly a history of research in the US/Canada AI community, and even there will not mention many researchers; a particularly in depth history of the field that covers these omissions is Jürgen Schmidhuber’s "Deep Learning in Neural Networks: An Overview". I am also most certainly not a professional writer, and will cop to there being shorter and much less technical overviews written by professional writers such as Paul Voosen’s "The Believers", John Markoff’s "Scientists See Promise in Deep-Learning Programs" and Gary Marcus’s "Is “Deep Learning” a Revolution in Artificial Intelligence?". I also will stay away from getting too technical here, but there is a plethora of tutorials on the internet on all the major topics covered in brief by me.
Any corrections would be greatly appreciated, though I will note some ommisions are intentional since I want to try and keep this ‘brief’ and a good mix of simple technical explanations and storytelling.
Let’s start with a brief primer on what Machine Learning is. Take some points on a 2D graph, and draw a line that fits them as well as possible. What you have just done is generalized from a few example of pairs of input values (x) and output values (y) to a general function that can map any input value to an output value. This is known as linear regression, and it is a wonderful little 200 year old technique for extrapolating a general function from some set of input-output pairs. And here’s why having such a technique is wonderful: there is an incalculable number of functions that are hard to develop equations for directly, but are easy to collect examples of input and output pairs for in the real world – for instance, the function mapping an input of recorded audio of a spoken word to an output of what that spoken word is.
Linear regression is a bit too wimpy a technique to solve the problem of speech recognition, but what it does is essentially what supervised Machine Learning is all about: ‘learning’ a function given a training set of examples, where each example is a pair of an input and output from the function (we shall touch on the unsupervised flavor in a little while). In particular, machine learning methods should derive a function that can generalize well to inputs not in the training set, since then we can actually apply it to inputs for which we do not have an output. For instance, Google’s current speech recognition technology is powered by Machine Learning with a massive training set, but not nearly as big a training set as all the possible speech inputs you might task your phone with understanding.
This generalization principle is so important that there is almost always a test set of data (more examples of inputs and outputs) that is not part of the training set. The separate set can be used to evaluate the effectiveness of the machine learning technique by seeing how many of the examples the method correctly computes outputs for given the inputs. The nemesis of generalization is overfitting – learning a function that works really well for the training set but badly on the test set. Since machine learning researchers needed means to compare the effectiveness of their methods, over time there appeared standard datasets of training and testing sets that could be used to evaluate machine learning algorithms.
Okay okay, enough definitions. Point is – our line drawing exercise is a very simple example of supervised machine learning: the points are the training set (X is input and Y is output), the line is the approximated function, and we can use the line to find Y values for X values that don’t match any of the points we started with. Don’t worry, the rest of this history will not be nearly so dry as all this. Here we go.
The Folly of False Promises
Why have all this prologue with linear regression, since the topic here is ostensibly neural nets? Well, in fact linear regression bears some resemblance to the first idea conceived specifically as a method to make machines learn: Frank Rosenblatt’s Perceptron.
A diagram showing how the Perceptron works. (Source)
A psychologist, Rosenblatt conceived of the Percetron as a simplified mathematical model of how the neurons in our brains operate: it takes a set of binary inputs (nearby neurons), multiplies each input by a continuous valued weight (the synapse strength to each nearby neuron), and thresholds the sum of these weighted inputs to output a 1 if the sum is big enough and otherwise a 0 (in the same way neurons either fire or do not). Most of the inputs to a Perceptron are either some data or the output of another Perceptron, but an extra detail is that Perceptrons also have one special ‘bias’ input, which just has a value of 1 and basically ensures that more functions are computable with the same input by being able to offset the summed value. This model of the neuron built on the work of Warren McCulloch and Walter Pitts Mcculoch-Pitts, who showed that a neuron model that sums binary inputs and outputs a 1 if the sum exceeds a certain threshold value, and otherwise outputs a 0, can model the basic OR/AND/NOT functions. This, in the early days of AI, was a big deal – the predominant thought at the time was that making computers able to perform formal logical reasoning would essentially solve AI.
Another diagram, showing the biological inspiration. The activation function is what people now call the non-linear function applied to the weighted input sum to produce the output of the artificial neuron – in the case of Rosenblatt’s Perceptron, the function just a thresholding operation. (Source)
However, the Mcculoch-Pitts model lacked a mechanism for learning, which was crucial for it to be usable for AI. This is where the Perceptron excelled – Rosenblatt came up with a way to make such artificial neurons learn, inspired by the foundational work of Donald Hebb. Hebb put forth the unexpected and hugely influential idea that knowledge and learning occurs in the brain primarily through the formation and change of synapses between neurons – concisely stated as Hebb’s Rule:
“When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased.”
The Perceptron did not follow this idea exactly, but having weights on the inputs allowed for a very simple and intuitive learning scheme: given a training set of input-output examples the Perceptron should ‘learn’ a function from, for each example increase the weights if the Perceptron output for that example’s input is too low compared to the example, and otherwise decrease the weights if the output is too high. Stated ever so slightly more formally, the algorithm is as follows:
Start off with a Perceptron having random weights and a training set
For the inputs of an example in the training set, compute the Perceptron’s output
If the output of the Perceptron does not match the output that is known to be correct for the example:
If the output should have been 0 but was 1, decrease the weights that had an input of 1.
If the output should have been 1 but was 0, increase the weights that had an input of 1.
Go to the next example in the training set and repeat steps 2-4 until the Perceptron makes no more mistakes
This procedure is simple, and produces a simple result: an input linear function (the weighted sum), just as with linear regression, ‘squashed’ by a non-linear activation function (the thresholding of the sum). It’s fine to threshold the sum when the function can only have a finite set of output values (as with logical functions, in which case there are only two – True/1 and False/0), and so the problem is not so much to generate a continuous-numbered output for any set of inputs – regression – as to categorize the inputs with a correct label – classification.
‘Mark I Perceptron at the Cornell Aeronautical Laboratory’, hardware implementation of the first Perceptron (Source: Wikipedia / Cornell Library)
Rosenblatt implemented the idea of the Perceptron in custom hardware (this being before fancy programming languages were in common use), and showed it could be used to learn to classify simple shapes correctly with 20×20 pixel-like inputs. And so, machine learning was born – a computer was built that could approximate a function given known input and output pairs from it. In this case it learned a little toy function, but it was not difficult to envision useful applications such as converting the mess that is human handwriting into machine-readable text.
But wait, so far we’ve only seen how one Perceptron is able to learn to output a one or a zero – how can this be extended to work for classification tasks with many categories, such as human handwriting (in which there are many letters and digits as the categories)? This is impossible for one Perceptron, since it has only one output, but functions with multiple outputs can be learned by having multiple Perceptrons in a layer, such that all these Perceptrons receive the same input and each one is responsible for one output of the function. Indeed, neural nets (or, formally, ‘Artificial Neural Networks’ – ANNs) are nothing more than layers of Perceptrons – or neurons, or units, as they are usually called today – and at this stage there was just one layer – the output layer. So, a prototypical example of neural net use is to classify an image of a handwritten digit. The inputs are the pixels of the image , and there are 10 output neurons with each one corresponding to one of the 10 possible digit values. In this case only one of the 10 neurons output 1, the highest weighted sum is taken to be the correct output, and the rest output 0.
A neural net with multiple outputs.
It is also possible to conceive of neural nets with artificial neurons different from the Perceptron. For instance, the thresholding activation function is not strictly necessary; Bernard Widrow and Tedd Hoff soon explored the option of just outputting the weight input in 1960 with “An adaptive “ADALINE” neuron using chemical “memistors”, and showed how these ‘Adaptive Linear Neurons’ could be incorporated into electrical circuits with ‘memistors’ – resistors with memory. They also showed that not having the threshold activation function is mathematically nice, because the neuron’s learning mechanism can be formally based on minimizing the error through good ol’ calculus. See, with the neuron’s function not being made weird by this sharp thresholding jump from 0 to 1, a measure of how much the error changes when each weight is changed (the derivative) can be used to drive the error down and find the optimal weight values. As we shall see, finding the right weights using the derivatives of the training error with respect to each weight is exactly how neural nets are typically trained to this day.
In short a function is differentiable if it is a nice smooth line – Rosenblatt’s Perceptron computed the output in such a way that the output abruptly jumped from 0 to 1 if the input exceeded some number, whereas Adaline simply output the input which was a nice non-jumpy line. For a much more in depth explanation of all this math you can read this tutorial, or any resource from Google – let us focus on the fun high-level concepts and story here.
If we think about ADALINE a bit more we will come up with a further insight: finding a set of weights for a number of inputs is really just a form of linear regression. And again, as with linear regression, this would not be enough to solve the complex AI problems of Speech Recognition or Computer Vision. What McCullough and Pitts and Rosenblatt were really excited about is the broad idea of Connectionism: that networks of such simple computational units can be vastly more powerful and solve the hard problems of AI. And, Rosenblatt said as much, as in this frankly ridiculous New York Times quote from the time:
“The Navy revealed the embryo of an electronic computer today that it expects will be able to walk, talk, see, write, reproduce itself an be conscious of its existence … Dr. Frank Rosenblatt, a research psychologist at the Cornell Aeronautical Laboratory, Buffalo, said Perceptrons might be fired to the planets as mechanical space explorers”
Or, have a look at this TV segment from the time:
The stuff promised in this video – still not really around.
This sort of talk no doubt irked other researchers in AI, many of whom were focusing on approaches based on manipulation of symbols with concrete rules that followed from the mathematical laws of logic. Marvin Minsky, founder of the MIT AI Lab, and Seymour Papert, director of the lab at the time, were some of the researchers who were skeptical of the hype and in 1969 published their skepticism in the form of rigorous analysis on of the limitations of Perceptrons in a seminal book aptly named Perceptrons. Interestingly, Minksy may have actually been the first researcher to implement a hardware neural net with 1951’s SNARC (Stochastic Neural Analog Reinforcement Calculator) , which preceded Rosenblatt’s work by many years. But the lack of any trace of his work on this system and the critical nature of the analysis in Perceptrons suggests that he concluded this approach to AI was a dead end. The most widely discussed element of this analysis is the elucidation of the limits of a Perceptron – they could not, for instance, learn the simple boolean function XOR because it is not linearly separable. Though the history here is vague, this publication is widely believed to have helped usher in the first of the AI Winters – a period following a massive wave of hype for AI characterized by disillusionment that causes a freeze to funding and publications.
Visualization of the limitations of Perceptrons. Finding a linear function on the inputs X,Y to correctly ouput + or – is equivalent to drawing a line on this 2D graph separating all + cases from – cases; clearly, for the third case this is impossible.
The Thaw of the AI Winter
So, things were not good for neural nets. But why? The idea, after all, was to combine a bunch of simple mathematical neurons to do complicated things, not to use a single one. In other terms, instead of just having one output layer, to send an input to arbitrarily many neurons which are called a hidden layer because their output acts as input to another hidden layer or the output layer of neurons. Only the output layer’s output is ‘seen’ – it is the answer of the neural net – but all the intermediate computations done by the hidden layer(s) can tackle vastly more complicated problems than just a single layer.
The reason hidden layers are good, in basic terms, is that the hidden layers can find features within the data and allow following layers to operate on those features rather than the noisy and large raw data. For example, in the very common neural net task of finding human faces in an image, the first hidden layer could take in the raw pixel values and find lines, circles, ovals, and so on within the image. The next layer would receive the position of these lines, circles, ovals, and so on within the image and use those to find the location of human faces – much easier! And people, basically, understood this. In fact, until recently machine learning techniques were commonly not applied directly to raw data inputs such as images or audio. Instead, machine learning was done on data after it had passed through feature extraction – that is, to make learning easier machine learning was done on preprocessed data from which more useful features such as angles or shapes had been already extracted.
Earlier, we saw that the weighted sum computed by the Perceptron is usually put through a non-linear activation function. Now we can get around to fully answering an implicit question: why bother? Two reasons: 1. Without the activation function, the learned functions could only be linear, and most ‘interesting’ functions are not linear (for instance, logic functions that only output 1 or 0 or classification functions that output the category).
2. Several layers of linear Perceptrons can always be collapsed into only one layer due to the linearity of all the computations – the same cannot be done with non-linear activation functions.
So, in intuitive speak a network can massage the data better with activation functions than without.
Visualization of traditional handcrafted feature extraction. (Source)
So, it is important to note Minsky and Papert’s analysis of Perceptrons did not merely show the impossibility of computing XOR with a single Perceptron, but specifically argued that it had to be done with multiple layers of Perceptrons – what we now call multilayer neural nets – and that Rosenblatt’s learning algorithm did not work for multiple layers. And that was the real problem: the simple learning rule previously outlined for the Perceptron does not work for multiple layers. To see why, let’s reiterate how a single layer of Perceptrons would learn to compute some function:
A number of Perceptrons equal to the number of the function’s outputs would be started off with small initial weights
For the inputs of an example in the training set, compute the Perceptrons’ output
For each Perceptron, if the output does not match the example’s output, adjust the weights accordingly
Go to the next example in the training set and repeat steps 2-4 until the Perceptrons no longer make mistakes
The reason why this does not work for multiple layers should be intuitively clear: the example only specifies the correct output for the final output layer, so how in the world should we know how to adjust the weights of Perceptrons in layers before that? The answer, despite taking some time to derive, proved to be once again based on age-old calculus: the chain rule. The key realization was that if the neural net neurons were not quite Perceptrons, but were made to compute the output with an activation function that was still non-linear but also differentiable, as with Adaline, not only could the derivative be used to adjust the weight to minimize error, but the chain rule could also be used to compute the derivative for all the neurons in a prior layer and thus the way to adjust their weights would also be known. Or, more simply: we can use calculus to assign some of the blame for any training set mistakes in the output layer to each neuron in the previous hidden layer, and then we can further split up blame if there is another hidden layer, and so on – we backpropagate the error. And so, we can find how much the error changes if we change any weight in the neural net, including those in the hidden layers, and use an optimization technique (for a long time, typically stochastic gradient descent) to find the optimal weights to minimize the error.
Backpropagation was derived by multiple researchers in the early 60’s and implemented to run on computers much as it is today as early as 1970 by Seppo Linnainmaa, but Paul Werbos was first in the US to propose that it could be used for neural nets after analyzing it in depth in his 1974 PhD Thesis. Interestingly, as with Perceptrons he was loosely inspired by work modeling the human mind, in this case the psychological theories of Freud as he himself recounts:
“In 1968, I proposed that we somehow imitate Freud’s concept of a backwards flow of credit assignment, flowing back from neuron to neuron … I explained the reverse calculations using a combination of intuition and examples and the ordinary chainrule, though it was also exactly a translation into mathematics of things that Freud had previously proposed in his theory of psychodynamics!”
Despite solving the question of how multilayer neural nets could be trained, and seeing it as such while working on his PhD thesis, Werbos did not publish on the application of backprop to neural nets until 1982 due to the chilling effects of the AI Winter. In fact, Werbos thought the approach would make sense for solving the problems pointed out in Perceptrons, but the community at large lost any faith in tackling those problems:
“Minsky’s book was best known for arguing that (1) we need to use MLPs [multilayer perceptrions, another term for multilayer neural nets] even to represent simple nonlinear functions such as the XOR mapping; and (2) no one on earth had found a viable way to train MLPs good enough to learn such simple functions. Minsky’s book convinced most of the world that neural networks were a discredited dead-end – the worst kind of heresy. Widrow has stressed that this pessimism, which squashed the early “perceptron” school of AI, should not really be blamed on Minsky. Minsky was merely summarizing the experience of hundreds of sincere researchers who had tried to find good ways to train MLPs, to no avail. There had been islands of hope, such as the algorithm which Rosenblatt called “backpropagation” (not at all the same as what we now call backpropagation!), and Amari’s brief suggestion that we might consider least squares [what is the basis of simple linear regression] as a way to train neural networks (without discussion of how to get the derivatives, and with a warning that he did not expect much from the approach). But the pessimism at that time became terminal. In the early 1970s, I did in fact visit Minsky at MIT. I proposed that we do a joint paper showing that MLPs can in fact overcome the earlier problems … But Minsky was not interested(14). In fact, no one at MIT or Harvard or any place I could find was interested at the time.”
It seems that it was because of this lack of academic interest that it was not until more than a decade later, in 1986, that this approach was popularized in “Learning representations by back-propagating errors” by David Rumelhart, Geoffrey Hinton, and Ronald Williams . Despite the numerous discoveries of the method (the paper even explicitly mentions David Parker and Yann LeCun as two people who discovered it beforehand) the 1986 publication stands out for how concisely and clearly the idea is stated. In fact, as a student of Machine Learning it is easy to see that the description in their paper is essentially identical to the way the concept is still explained in textbooks and AI classes. A retrospective in IEEE echoes this notion:
“Unfortunately, Werbos’s work remained almost unknown in the scientific community. In 1982, Parker rediscovered the technique [39] and in 1985, published a report on it at M.I.T. [40]. Not long after Parker published his findings, Rumelhart, Hinton, and Williams [41], [42] also rediscovered the techniques and, largely as a result of the clear framework within which they presented their ideas, they finally succeeded in making it widely known.”
But the three authors went much further than just present this new learning algorithm. In the same year they published the much more in-depth “Learning internal representations by error propagation”, which specifically addressed the problems discussed by Minsky in Perceptrons. Though the idea was conceived by people in the past, it was precisely this formulation in 1986 that made it widely understood how multilayer neural nets could be trained to tackle complex learning problems. And so, neural nets were back! In part 2, we shall see how just a few years later backpropagation and some other tricks discussed in “Learning internal representations by error propagation” were applied to a very significant problem: enabling computers to read human handwriting.
from DataTau http://www.andreykurenkov.com/writing/a-brief-history-of-neural-nets-and-deep-learning/
This is a game built with machine learning. You draw, and a neural network tries to guess what you’re drawing.
Of course, it doesn’t always work. But the more you play with it, the more it will learn.
So far we have trained it on a few hundred concepts, and we hope to add more over time.
We made this as an example of how you can use machine learning in fun ways.
Watch the video below to learn about how it works, and check out more A.I. Experiments here.
Built by Jonas Jongejan, Henry Rowley, Takashi Kawashima, Jongmin Kim, Nick Fox-Gieg, with friends at Google Creative Lab and Data Arts Team.
from Sidebar http://sidebar.io/out?url=https%3A%2F%2Fquickdraw.withgoogle.com%2F
End visual noise by removing unnecessary style divisions
Rendering visual borders around each component of a website or app does a disservice to user experience. In most cases the styling isn’t needed, or less of it is needed to afford action.
When humans speak, only 7% of their message is conveyed through the content of words. The other 93% is communicated through tonal elements and body language. Visual design is the body language of content. It is the voice and tone of message. Visual noise caused by “boxing” is like an overeager sales person pushing a line of products. You might want what is being sold, but the delivery is overbearing.
Facebook and Google+ use distinct styling to denote content groupings.
Facebook and Google+ make each timeline post a distinct visual card, complete with borders and drop shadows. Is this styling needed?
Isn’t Google Search so much more pleasant to look at when placed next to Google+?
Arguably, Google Search is better designed than Google+ because the results aren’t “boxed.” However, it is important to note that the use case is different. Google+ is about community discovery, whereas Google Search presents query results. Despite the differences, I think the visual design of Google+ would improve if it were “unboxed.”
Google Search results boxed and unboxed.
As an experiment, I “boxed” Google Search to see if it improved the design. Do the added borders, drop shadows, and background color improve or detract from the layout?
The design of the web has come a long way in the last few years. The “flat design” trend provided a framework for questioning superficial styling. And then Google’s Material Design devised a visual language that employs principles from physical reality to digital interfaces.
Regardless of the trend or framework, it is important to keep pushing and questioning the design of the web. I believe visual design has a larger impact on content comprehension than is currently recognized.
I think the main question designers should ask themselves is,“How much styling is needed?” In my opinion, not much. Unbox the web!
If you found this article of value please click the ♡ below so others can find this post. Find me on Twitter, and Dribbble.
from Sidebar http://sidebar.io/out?url=https%3A%2F%2Fuxdesign.cc%2Funbox-the-web-f00bc8e0d0e3%23.2u43qey52
Sundar Pichai is huddling with five Google staffers in a room next to his office that’s known—appropriately enough—as “Sundar’s Huddle.” The employees are members of the Google Photos team, and they’re here this morning to update Pichai on something they’ve been working on for months.
The group has barely begun its presentation when Pichai starts peppering them with questions, opinions, and advice. For half an hour, the discussion careens from subject to subject: the power of artificial intelligence, the value of integrating Google Photos with other products such as Google Drive, the importance of creating an emotional bond with the users of an app. After the team shows Pichai a rough cut of a promotional video, his feedback is unguarded and heartfelt: “That’s awesome!”
Google’s bearded, 44-year-old CEO is, unmistakably, in his element. “Nothing makes me happier than a product review in which I can sit with the team and they’re showing me something they’re building,” Pichai had told me a few days earlier. “Being able to react to it and think through, ‘When users get this, what will their feedback be?’ I’m always on a quest to do that better and do more of it.”
Pichai’s tone at the meeting—affable, engaged, ambitious—encapsulates his approach to running Google. In the year since he was named CEO, he’s been busy reshaping the company into a more harmonious, collaborative place in a quest to improve the productivity of an already inventive culture.
Pichai took charge at a pivotal moment. In August 2015, cofounder Larry Page split what had been Google into multiple units that now live under a new corporate umbrella, Alphabet, run by Page as CEO. Pichai’s Google is responsible for most consumer services and products, including search, Gmail, YouTube, Android, and hardware such as phones. With his distinctive blend of enthusiasm and curiosity, he has shuffled many of the business’s moving parts, putting longtime Googlers in new roles and hiring fresh talent to pursue a forward interpretation of the company’s foundational mission: organizing the world’s information and making it universally accessible and useful.
Google’s new hardware lineup: the Google Wi-Fi router, Chromecast Ultra media streamer, Home speaker, Pixel phones, and Daydream View VR headset
Results are starting to arrive at a fast clip. This fall, it held two major product launches in San Francisco less than a week apart. At the first, it unveiled Google Cloud, a big expansion of offerings for business customers, such as the G Suite assortment of productivity tools (formerly known as Google Apps). The second was an Apple-esque hardware extravaganza at which the company announced the first Google-designed smartphones (the Pixel and Pixel XL), as well as a competitor to Amazon’s Echo speaker (Google Home), a virtual-reality headset (Daydream View), a wireless router (Google Wifi), and an upgrade to its video-streaming gizmo (Chromecast Ultra).
The wide scope represented by that lineup may suggest that Pichai isn’t picking his competitive battles. But his key ambitions are bound by a core prediction: that the world is moving from the smartphone age into, in Pichai’s phrase, an “AI-first” era, in which Google products will help people accomplish tasks in increasingly sophisticated, even anticipatory ways. The Pixel phones and Google Home, for instance, are the first devices with embedded support for Google Assistant, a rival to Apple’s Siri and Amazon’s Alexa that is designed not only to handle straightforward commands but also fuzzier requests such as “Play that Shakira song from Zootopia.” The Assistant is also designed to engage in relatively complex conversations related to tasks such as making vacation arrangements.
“We think of the Assistant as of an evolution of Google search,” says John Giannandrea, who, as senior VP of search, research, and machine intelligence is responsible for the technologies that power both Google search in its classic form and the Assistant. “It’s a superset in some senses. If you said to Google search, ‘Get me a pizza,’ nothing happens. Our aspiration is that the assistant will go and get you a pizza. We don’t today, but that’s our aspiration.”
Each of the tech titans Google competes with in various ways—Amazon, Apple, Facebook, Microsoft—has sweeping AI initiatives of its own, and Siri and Alexa have major head starts with consumers. But Google—which built the Assistant using concepts it’s already been exploring in Google Now and Google voice search—has more experience teaching computers to understand language, photos, and other forms of information than anyone else. Google Assistant will be able to call on those technical underpinnings as it battles it out in the marketplace. “We’ve invested in machine learning for a long time, in anticipation of this moment,” Pichai says.
Though the most out-there moonshots that Page has championed have been spun out into other parts of Alphabet, Pichai thinks that Google’s present efforts have plenty of epoch-shifting potential. “Larry always challenges all of us to think on a much, much bigger scale,” says Pichai of his boss. “He has a healthy disregard for constraints and wants us to stay focused on solving big problems. He cares deeply about using technology to help others, and reminds me of the immense responsibility we have as Google to help make the world a better place.”
“Building general artificial intelligence in a way that helps people meaningfully—I think the word moonshot is an understatement for that,” Pichai says, sounding startled that anyone might think otherwise. “I would say it’s as big as it gets.”
Google’s AI-centric October product launch, introduced by Pichai
Pichai’s aspiration to build hyper-ambitious products is classic Google. His managerial style, however, is strikingly different from that of Page, who is legendary for setting expectations so high that meetings can be scary as well as inspiring. When you discuss Pichai with people who work closely with him, they mention his empathy, his humor, his eagerness to encourage teamwork across the company—and how he uses them to achieve his lofty goals for the company.
“We’re proud that this is a nice guy who’s gotten to the top—someone who cares about other people,” says Caesar Sengupta, a longtime Pichai protege and VP in charge of Google’s efforts in emerging markets. “But at the product strategy level, he’s been an amazing visionary.”
Philipp Schindler, chief business officer: “We’re not pushing hard for monetization too early on but we want to understand it. We want to lay the groundwork.”
According to Philipp Schindler, an 11-year Google veteran who, as the company’s chief business officer, manages a 15,000-person sales and operations group, Pichai “is as smart and thoughtful as you can be. He also has this ability to change perspective and look through other people’s eyes. That’s something that you don’t find so much in our world.”
Though Pichai is not a spotlight-hogger—at the San Francisco hardware launch, he briefly introduced the proceedings and then got off the stage—he claims to relish being a public face of Google, a responsibility that Page mostly sidestepped. Which is why, when Schindler was entertaining the CEO and chairman of one of the world’s largest consumer-goods companies at home, he didn’t hesitate to invite his boss over to help tell Google’s story over dinner. (Fortunately, he notes, “Sundar lives two minutes from my house.”)
“I really care about communicating what we are trying to do, our intent behind it,” says Pichai, who can stroll in seconds from his desk, through a door, and into Google’s sprawling “Partner Plex” welcome center, allowing him rapid access to Google’s many visitors, from advertising clients to foreign dignitaries. But he underlines that these interactions are as much about listening as talking. “I’ve done many customer meetings in which I’ve felt that I’ve walked away with a better understanding of their perspective on us.”
Pichai seems to have settled into the CEO role with aplomb. Though his ascent is often described as “meteoric,” he spent 11 years at Google before getting the top job. Born in 1972 in Tamil Nadu, India, he came to the U.S. as an engineering student in 1993, earned degrees from Stanford and Wharton, and worked at chip-manufacturing-equipment company Applied Materials before scoring a job as a McKinsey consultant. When his colleague Nick Fox left for Google in 2003, Fox’s new boss, Susan Wojcicki—then Google’s advertising chief, now the CEO of YouTube—asked if any other McKinsey-ites were worth recruiting. “The best one,” Fox recalls telling her, “is this guy Sundar.”
At the time, Google was in a very different place. “We had long discussions about whether he should take the job,” says Stefan Heck, another McKinsey colleague who is now CEO of autonomous-driving startup Nauto. “It’s funny in hindsight. Google was pre-IPO. You’d have been crazy not to join, but that was far from obvious.”
Once he took the plunge and signed on in April 2004—initially as product manager for the Google Toolbar—Pichai was immediately “struck that at Google, when you walked around, if you had an idea and shared it, people around you were naturally optimistic,” he remembers. “They would tend to build on it. They would say, ‘You know, it would be even cooler if you did this…’”
From early in Pichai’s days at Google, he was known as a low-key manager who tackled projects of ever-increasing scale with quiet persistence. “He was always given the toughest problems,” says Fox, who points to Pichai’s spearheading of the Chrome web browser as a career-defining success. When Google started work on Chrome in 2006, Microsoft’s Internet Explorer had more than 80% of the market. The simpler, speedier Chrome went on to become the world’s most-used browser; even Microsoft eventually gave up on IE, ditching it for the decidedly Chrome-like Edge.
That unlikely victory helps explain the fearlessness with which Google is now taking on entrenched products: Google Home vs. Echo, Google Assistant vs. Siri, Allo vs. Facebook Messenger. “Sundar didn’t ask, ‘How can you compete with Internet Explorer?’ ” says Fox. “He said, ‘We think we can build a better web browser. Let’s go do that.’ ”
“There’s never a month which goes by without me having moments of being a kid in a candy store, even today at Google,” says Pichai[Photo: Mark Mahaney]
Despite all the changes at Google, the company’s Mountain View, California, campus remains the same quirky corporate Xanadu it’s always been. When I wander around during a visit one October afternoon, I encounter both a “Chrometoberfest” party (Googlers enjoying steins of beer and an oompah band) and a tiny patch of simulated beach where a few staffers are playing volleyball.
Google’s playful creativity and bottom-up innovation—exemplified by “20% time,” which encourages workers to follow their passions—remain central to the company’s view of itself. As an example, Pichai proudly mentions the new Daydream VR platform, which grew out of Cardboard, the VR headset that two engineers had whipped up without seeking permission. Still, there’s no denying that Pichai’s Google, which now has more than 66,000 employees, aims to go after its overarching strategic goals in a more thoughtful, disciplined manner than in the past. “At our scale, it’s important to focus and do it well,” he says. “[You need to have] a clear sense of where you’re going as a company, and then work toward that in a prioritized way.”
Jen Fitzpatrick, VP, Geo: “The Google Assistant wouldn’t exist without Sundar—it’s a core part of his vision for how we’re bringing all of Google together.”
Officially, Google has always advocated for collaboration. But in the past, as it encouraged individual units to shape their own destinies, the company sometimes operated more like a myriad of fiefdoms. Now, Pichai is steering Google’s teams toward a common mission: infusing the products and services they create with AI.
“Ultimately this stuff comes out in product features for users,” says Giannandrea of the machine-learning technologies that his group spearheads. “Being about to talk to your smartphone, being able to search your photos, being able to ask Google to tell you a joke.”
As disparate groups intermingle their efforts, “Sundar has brought a new emphasis to [collaboration], particularly at the senior leadership level,” says Jen Fitzpatrick, who joined Google as one of its first interns in 1999 and now oversees Google Maps. “He’s made it a core value of how he wants to run the company.”
Google’s top executives are “emailing and talking and meeting and coordinating constantly now,” says Diane Greene, the celebrated computer scientist and VMware cofounder who joined the company shortly after Pichai became CEO and led the reimagining of Google Cloud. “We all have a really clear understanding of what we’re doing, why we’re doing it, and what we’re trying to achieve.”
Pichai opening the event at which Google introduced a bevy of new hardware on October 4, 2016 in San Francisco[Photo: Ramin Talaie/Getty Images]
In some instances, Pichai’s plan for Google involves not just collaboration, but centralization. In the past disparate groups at the company tackled hardware projects on their own, and the results—such as various Nexus phones, tablets, and media streamers—didn’t have much of an impact on either Google or the market. (One big exception: Chromecast, which has sold more than 30 million units.)
“In the past, we would say, ‘Okay, to do that, let’s go build this,’” says Pichai. “Now, we’re deeply committed to doing hardware over multiple product cycles. It’s very hard, when you just do one-off product efforts here and there, to tackle longer-term problems.”
To make sure that future gadgets are built for the AI-first era, Pichai has collected everything relating to hardware into a single group and hired Rick Osterloh to run it. Osterloh was already a Google vet, having served as CEO of Motorola Mobility during the brief period when Google owned the phone maker. But back then, the company isolated that smartphone business from the rest of its operations to avoid ticking off Android partners such as Samsung. “We were completely at arm’s length,” Osterloh says. “That’s just how it was. It’s a different time now.”
Since starting in April, Osterloh has scrapped works-in-progress that weren’t central to the company’s future, such as Project Ara, a Lego-like smartphone with snap-together magnetic components that had already failed to meet its original 2015 ship date. “AI and machine learning are very critical, so if we were going to emphasize something, I wanted us to emphasize that as opposed to modularity, which was interesting but super-complicated,” he says.
The Google Home smart speaker will compete with Amazon’s Echo, a category-creating device that it closely resembles. But Osterloh says that the idea is less about going head-to-head with Amazon than advancing the bigger goal of making Google Assistant pervasive: “Kudos to Amazon for coming up with the Echo product first. It was very clear to us that we needed to do something within the home that accomplished the goal of getting the Google experience to our users.”
Rick Osterloh, senior VP, hardware: “When we ship hardware now, we want to make sure that the full user experience is really good.”
Even with this new, more concentrated vision, Google’s hardware team has its work cut out for it. The Pixel phone has gotten excellent reviews, but it’s extremely late to a smartphone market in which Apple gobbles up nearly all the profits and many makers of Android phones are struggling.
Osteloh says that the Pixel phones are “about emphasizing the best that Google has to offer,” which is another way of admitting that other manufacturers’ Android phones don’t necessarily show off Google’s apps and services to their best advantage. By taking on more responsibility for hardware, the company can ensure that a phone’s microphones, for instance, are tuned to perform well with Google Assistant.
“That’s the old Apple line—you can’t build the best experience unless you control both software and hardware,” says Greg Sterling, a contributing editor to Search Engine Land. “And it’s really true as an objective matter. There are a lot of nice Android phones, but something’s lacking because of the lack of total integration between both sides.”
The Pixel phones are being marketed like iPhones, with slick TV ads, and will be sold at Verizon stores. But Osterloh acknowledges that it will take multiple generations of phones to make a dent in the market, and that even then Google is unlikely to become one of the biggest players. “It’s very early for us,” he says. “I think our main goal for this generation of work is to deliver experiences that people are super-happy with.”
Google Home
The Assistant is also part of Google’s new messaging app, Allo, which was created by a communications group that Pichai formed in 2015 and asked his old friend from McKinsey, Nick Fox, to run. Given that Facebook already has two messaging apps with more than a billion users apiece (Messenger and WhatsApp), Allo might seem to be engaged in a near-impossible game of catch-up. Still, Google is betting that the app—which includes both a built-in version of Assistant and the ability to suggest AI-generated, situation-based automatic replies such as “sounds good” and “not really”—will be a leader in the race to redefine messaging around automation. “We think that’s a paradigm shift in technology,” says Fox. “It’s one that we think we’re well suited to address and well suited to solve because of our deep investment in machine learning and AI over the years.”
Nick Fox, VP, communications: “With Allo, we have a lot of the assets to make something that’s better and different and really, really useful.”
Early reviews for Allo have been mixed. Like many new Google initiatives, it’s a rough draft of an idea that will take time to develop, and it’s not a given that the company will be committed for the long term. (Exhibit A: The would-be Facebook killer Google+, which, under Page, went from company-wide priority to afterthought within a few years.) But the people who work most closely with Pichai frequently bring up his patient approach to product development.
“Sundar often talks in terms of 10-year cycles in technology and history,” says Giannandrea. “I find him very easy to work with, because he thinks about the larger picture, rather than just ‘what decision are we making today?’”
Still another way in which the current incarnation of Google reflects Pichai’s long-term priorities is the attention it pays to consumers in emerging economies, an initiative it calls Next Billion. “Giving access to technology, computing, knowledge to everyone is something which I’m passionate about,” says Pichai, who, in a memorable bit of biographical detail, was twelve when his family got its first telephone—a rotary-dial model. “I’ve tried to instill that at Google, across everything we do.”
India is a particular emphasis, mostly because of the huge number of consumers there. However, Pichai acknowledges there’s a personal aspect, too. “I’ve benefited a lot from India,” says the CEO, who earned a degree in metallurgical engineering from the Indian Institute of Technology before emigrating. “If there’s any thoughtful way that we as a company can do the right thing and pay it back, we’re committed to it.”
In India, Facebook’s Free Basics apps were widely regarded as Silicon Valley imperialism and eventually shot down by regulators. By contrast, Pichai’s efforts to democratize internet access in the country—including hotspots at train stations and data-scrimping versions of apps such as YouTube—have been welcomed.
“People are really proud that someone of Indian origin is leading a huge company,” says Sengupta, who runs the Next Billion effort from Singapore. “But more important, Sundar’s approach to India is in many ways very humble.”
Rather than feeling dumbed down, what Google is creating for consumers in new markets often turns out to be useful in more developed countries. “Maps was one of the earlier teams at Google to embrace the next billion mantra,” says Fitzpatrick. Her team built a version of Google Maps that could store maps on the phone, a plus in areas where data access is spotty or unaffordable. It turned out that the feature was also valuable for people trying to pull up driving directions in their cars, where phones often try to connect to a home Wi-Fi network that’s too distant to provide a strong signal. Now it’s part of the core Maps experience.
For all of Google’s idealism, there’s another unglamorous but essential reality to the business that Pichai runs: It makes billions in profits from advertising, which subsidize not only Alphabet’s not-yet-profitable moonshots but also Google’s own new initiatives. In Alphabet’s third quarter, ads contributed almost 90% of Google revenues, which, in turn, accounted for 99% of Alphabet revenues.
If Google Assistant is indeed the evolution of Google search, it means that the company must aspire to turn it into a business with the potential to be huge in terms of profits as well as usage. How it will do that remains unclear, especially since Assistant is often provided in the form of a spoken conversation, a medium that doesn’t lend itself to the text ads that made Google rich. But Pichai says that he’s confident that the best strategy remains nailing the experience first—a mantra that the company has cherished ever since cofounders Larry Page and Sergey Brin turned their Stanford research into a breakthrough search engine, years before they started auctioning off text ads tied to keywords.
“I’ve always felt if you solve problems for users in meaningful ways, there will become value as part of solving that equation,” Pichai argues. “Inherently, a lot of what people are looking for is also commercial in nature. It’ll tend to work out fine in the long run.”
Diane Greene, senior VP, Google Cloud: “People saw that Google was selling to the enterprise, but weren’t convinced that it was a long-term commitment. That’s not happening anymore.”
But the fact that Google can pour resources into new projects without stressing out over immediate return doesn’t mean that it’s ignoring the subject entirely. Many of the people who are part of chief business officer Schindler’s staff are embedded in product groups. And even nascent operations have some number-crunchers on board thinking about they’ll look like when they are full-fledged businesses.
“The stage defines how much effort and attention I pay,” says Schindler. “The teams that are supporting the ad side are huge teams. While the team that is supporting the virtual reality, augmented reality side is one really smart guy and a couple of other people.”
Greene’s Google Cloud arm also has the potential to become a moneymaker whose eventual scale could rival Google’s ad business. The basic concept—providing an array of on-demand services to power other companies’ sites and apps—was pioneered by Amazon Web Services. “We have this enormous IT industry, at least a trillion dollar industry, almost overnight,” says Greene.
Here too Google sees its AI expertise as a powerful competitive advantage, as it turns the machine-language technologies it’s building for its own purposes into services it can sell to others. “We definitely see a big opportunity,” says Pichai of Google Cloud. “And the word ‘big’ probably understates it. We are probably at about one or two percent of the eventual market opportunity here.”
For all the tendency of Pichai’s employees to gush about his fundamental decency, it’s clear that it’s not just a personality trait: It’s also a management strategy he uses to give the company’s myriad, audacious dreams a shot at coming true.
“When you can align people to common goals, you truly get a multiplicative effect in an organization,” he tells me as we sit on a couch in Sundar’s Huddle after his Google Photos meeting. “The inverse is also true, if people are at odds with each other.” He is, as usual, smiling. The company’s aim, he says, is to create products “that will affect the lives of billions of users, and that they’ll use a lot. Those are the kind of meaningful problems we want to work on.”
from Co.Labs https://www.fastcompany.com/3065420/secrets-of-the-most-productive-people/at-sundar-pichais-google-ai-is-everything-and-everywhe?partner=rss
It seems like the current buzz word in the design industry and everyone wants one. But how exactly can a product benefit from having a living, breathing design language? I’m going to try break down the very basics so you can understand why it’s needed.
Creating an underlying language will unite our design philosophies and methodologies across our platform.
So why do we need a design language?
There are two ways of looking at it, from an internal and an external perspective.
Internal
It creates a holistic perspective to ensure we’re all adhering to the same methodologies and patterns as a team. Every team member should be inline with the concept that we’re promoting and should be able to reference the design principles against any project they are currently working on. The main goal of a design language is to create focus and clarity for designers. A design language is like any language. If there is any confusion it will cause a breakdown in communication.
External
Having a cohesive Design Language creates harmony within a platform. For onlookers, standardised colours, interactions and patterns creates a sense of familiarity and security. A well planned and well executed design language is the key to a gratifying experience. For instance, if you walk into a Starbucks in Iceland, you will recognize a lot of similar touches to your local Starbucks down the road. Familiarity brings a sense of comfort and security to the user.
Introducing design constraints on individual elements within a platform creates consistency at a higher level.
A successful design language will:
Focus: allow the designer to focus clearly on the project at hand rather then to be diverted by other distractions.
Clarity: allow the designer to think clearly about our design beliefs as well as the design constraints in place across the platform.
Confidence: allow the designer to have complete confidence in what they are designing and that it is in line with others in the team.
Consistency: create consistency across the product which in turn will create a secure, familiar experience across the platform.
Efficiency: create understanding across the teams, meaning less time consumed concentrating on the less important details.
Basically, if your designers are focused and understand the design language, it will give them confidence, which in turn will help the business at a higher level as it will create consistency and efficiency.
Building the foundations
Design principles
Having solid design principles in place, that the whole team has contributed to, ensures that we’re all adhering to the same methodologies and patterns as a team. Every team member should be in line with the concept that we’re promoting and should be able to reference the design principles against any project they are currently working on.
Tone of voice
Its important to create a consistent voice for our product. Each designer (or whoever is involved) should be aware of the approach needed when writing content. Having consistent content is a very large part of creating a consistent user experience and all designers should try to align all content accordingly.
How do we work together as a team? It’s important that everyone pulls in the same direction and everyone agrees that the chosen values are important to creating a happy working environment.
There are obviously a whole lot more elements you can establish to create a core foundation for your design identity. The above is just the tip of the iceberg. Every company is different so feel free to expand on it as much as you feel is right to explain the methodologies of your approach.
Visual identity
Creating the visual identity isn’t something that will be created overnight. It takes time. Sometimes it’s as clear as day as to what is needed, other times it takes time for the building blocks to fall into place. Once in place, it’s important that the fundamentals are captured and documented at a high level. The likes of use of colour, typography and style of iconography is key to creating consistency across a platform.
Colours: What is the colour palette used on the platform? Explain how, where and why we use certain colours.
Typography: What typeface is used on the platform? Summarises rules around weighting, sizing, vertical alignment etc?
Iconography: What is the generic style for icons? It will explain the rational as to why we have specific styles for different icon families.
Grid/Layouts: What grid system is used across the platform? Explain the use of the grid and the high level idealism of our layouts.
Interactions: What do people expect to see when they interact with our site? Give an overview of our standard interactions.
Animations: How do we approach animations? Explain the reason for animations on the platform and our constraints around using them.
Design Resources: A central point for assets to be easily downloaded for external partners. Colour swatches, logo’s, icon sets etc.
The next steps
You probably are fully aware of how important a design language is within your platform but saying to yourself ’where do I start?. This article is pretty high level. Creating a design language goes far, far deeper then what I have identified above. The creation of the style guide and in turn the development of a component library is the evolution of a design system.
So here is a process that I’ve put together that should help you focus on exactly what is needed to get the ball rolling:
Do a UI inventory audit
Before you start anything, its best to identify how inconsistent the current build is. This works in two ways. It helps identify the reason as to why you’re doing it, to identify how inconsistent everything is but it should help you get the backing of the business as to why exactly you’re creating the design system; to create consistency across the platform. Brad Frost has put together a great article around how you go about doing a UI audit.
An example of a UI Audit
Prioritize your UI elements
I’m sure every design team has different priorities with regards to what they feel is crucial to creating consistency but there are generally some elements that are critical to creating the basics. The likes of colors, typography and iconography is a great place to start. Work closely with the design and development team to create a list of priorities based on your UI audit, this should guide your road map for the foreseeable future.
I’ve found using a Trello board, as a way to keep a priority list up to date, is a great way of working. It allows you to a) create your list and set items in a line of priority i.e. what are you going to tackle first and b) allows you to track exactly how far along you are with each component.
An example of a Trello board documenting the transition of a component in the cycle
Start discussions with the design team
So now that you’ve identified exactly what you’re going to be tackling first in the priority list, it’s time to sit down with the design team to get all ideas and opinions out around the first components needed. There are various approaches as to who owns the design system project, but for this example I’m going to take the instance that there is one sole designer who is in charge of the project.
This means it’s up to you to discuss every aspect of the component with the designers who will, in time, be using the design language. This is extremely important to ensure that the designers all feel as if they have had an input into what is being created.
Document all instances
Its time to start making some decisions. Document what you are creating, ensuring that you’re catering for all instances needed. It’s vital that what you are creating is not subjective. You have to have rationale as to why you are making these decisions as it will allow you to explain your decisions to the design team down the line.
An example of color usage.
See if it works
The next step is to try out your decisions. It’s very easy to make decisions on paper but when you are putting them into practice it might turn out that some decisions just don’t work. Try out some examples of the new style using current designs.
Lock it down
Once you are happy with the outcome, and you have buy-in from all parties, it’s time to lock it down and educate the rest of the team as to how and why these elements are to be used. It’s important to remember that although you are locking down the styling, if you feel certain elements aren’t working, you can change them if needs be.
Move on to the next element
Once you have educated the team and are comfortable in the knowledge that the designers are respecting your decisions, it’s time to move on to the next set of elements. It’s up to you as to how many elements you take at a time, but you should never bite off too much. It will just distract you from really focusing on the smaller details. My starting preference would be : colors, typography, icons, input fields, tables, lists.
Once everyone is educated as to what the new style is, it’s important that all designers and developers are implementing the styles properly.
Weekly check-ins are vital to monitor the style choices to ensure that everyone is working off the same design decisions. Using products such as Craft by Invision really help bring consistency when moving forward.
How to gauge success
The design language is not a success until the company starts using it and finding value in it.
How often do you ask a friend or relative what their experience has been with a certain product or service before making a purchase decision? How many times have you seen people queuing for a busy restaurant while another sits empty next door?
Whether we realize it or not, we seek reassurance from others before making a wide range of our day-to-day decisions, and in the digital world, people now have more resources than ever to get such reviews and reassurance from.
Apps like Zomato, Tripadvisor, Uber, and Airbnb are just some of the many applications which people refer to before making any decisions, and their popularity underlines the changing way in which such information is sought. In fact, research shows that 88% of consumers trust online reviews as much as they do personal recommendations. In this new reality, it’s critical for brands to provide social proof within the online space in order to maximize their opportunities.
We’ve all seen the typical Verimark commercials showing just how effective their products are – whether it’s a cleaning product or a weight loss gimmick, their advertisements all promise excellence. But in the modern consumer process, brands speaking about themselves and paying actors to act as happy consumers in their commercials isn’t enough. Consumers are more demanding and smarter than ever before – brands either need to gain authentic social proof or be prepared to get left behind.
So how can brands gain social proof?
At the end of the day, that packed restaurant people are queuing for didn’t get popular by the owners talking about the quality of their food – the restaurant’s full because other people raved about it and maybe even rated it 5 stars on a food application.
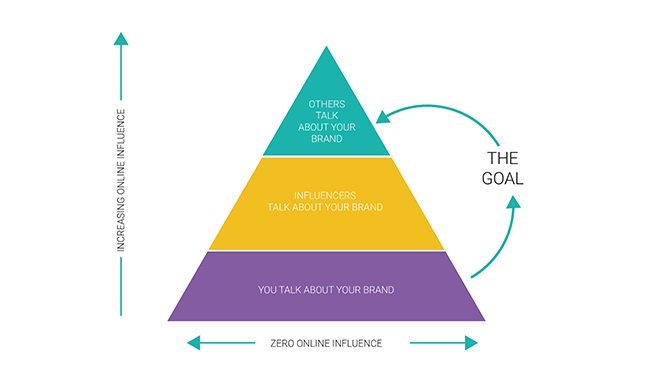
The following pyramid chart taken from this article on Social Media Today, explains the common steps to brands getting other people to talk about them online, ultimately achieving social proof/popularity in the market.
Essentially, gaining popularity or social proof in the market involves getting other people/consumers to speak about your brand, and one of the most successful ways to achieve this is through influencer marketing.
Influencer marketing involves leveraging an influencer’s ability to sway or impact the purchasing decisions of consumers.Through influencers reviewing products on their social channels, or simply using your products, they enable brands to connect with their target audiences. Influencers are able to get a brand’s message across in a more authentic way and ultimately spark conversations around your brand.
And because influencers are seen as credible sources to their audiences you gain social proof as soon as they mention your business.
The New Reality
However you look at it, the consumer discovery and purchase process has changed. In this new scenario, it’s more important than ever to generate positive word-of-mouth and find ways to help spread your brand message through online networks as a means of providing social proof.
Influencer marketing can be a great way to achieve this, and it’s worth considering how influencers within your target market could help boost your brand message.
from Social Media Today http://www.socialmediatoday.com/marketing/importance-social-proof-digital-space
Gemini has announced a series of API offerings aimed at automated traders.
Revealed today, Gemini users are now able to connect to the New York-based bitcoin and ether exchange via a REST API, WebSockets API and a FIX API, upgrades that bring more widely used electronic communications protocols to the platform.
In statements, representatives from Gemini said that the updates would make private order status information more readily accessible to traders.
The exchange wrote:
“This should prove to be much more efficient than the REST protocol for all of our automated traders, since order status updates and other events are pushed to you rather than requiring you to continually poll for updates.”
Notably, Gemini said the service was inspired by feedback from Whale Club, the popular network for bitcoin day traders, a move that may suggest a shift in strategy at the exchange.
Launched late last year by investors Cameron and Tyler Winklevoss, Gemini has arguably struggled to attract users from this community, in part due to its original positioning as a service for enterprise institutions and its lack of offerings for more active traders.
However, that market may be becoming more important now that Gemini’s initial target audience has proved somewhat elusive.
Data from Bitcoinity indicates Gemini lags behind the two most popular regulated US dollar bitcoin exchanges, Coinbase’s GDAX and Paxos’ itBit.
Over the last seven days, Gemini has traded 13,913 BTC (nearly $10m), while GDAX saw 40,455 BTC in volume (roughly $28.5m) during the time period.




 | Inc.com")












 It seems like the current buzz word in the design industry and everyone wants one. But how exactly can a product benefit from having a living, breathing design language? I’m going to try break down the very basics so you can understand why it’s needed.
It seems like the current buzz word in the design industry and everyone wants one. But how exactly can a product benefit from having a living, breathing design language? I’m going to try break down the very basics so you can understand why it’s needed.







{kind=link}