Too many interfaces are guilty of displaying too much information at once. Not all that’s displayed is immediately relevant. Some information is temporarily irrelevant until users meet certain conditions. As such, you should conceal irrelevant info so users can focus on what’s relevant. Focusing on relevant info first allows them to complete tasks with fewer […]
An old, not very good sketch from Yours Truly (picture from the Author)
Have you tried to Google “Behance Car Design Sketch” lately?
If you do, I bet your eyeballs will be assaulted by a barrage of out-of-proportion, often even out of perspective “vehicles” whose massive wheels and impossibly tiny glass fight for your attention, yet they all look the same. We have been fetishizing sketching to a point where we have lost sight of what matters, especially in the design academy’s world.
Over the past forty years, many automobile design courses have popped up in various locations worldwide, all seemingly with the same goal: to separate wealthy kids’ families from an atrociously large chunk of their cash in exchange for the “high education” needed to enter the field.
Except that’s not what they deliver, in most cases.
The proliferation of for-profit design schools flooded what has always been a small job market with bright, resourceful, and creative young professionals that sketch like demi-gods and make ace renders but know nothing of designing a vehicle. The result are hundreds of portfolios full of shiny eye-candy whose wheels don’t turn, suspensions have no travel, zero outward visibility.
As a former Pininfarina studio chief wisely stated in this brilliant Form Trends article
“You don’t pretend to beat Federer by simply hitting the ball hardest.”
Any game’s rules are there to be challenged, bent, or changed, but refusing to learn them in the first place gets you nowhere. Small wonder that “junior designers” ‘ market value has been driven below zero, as the supply of “sketch monkeys” vastly exceeds the little market demand for them.
I’ve seen things you wouldn’t believe…
…like plenty of talented young designers and supposedly “senior” ones, blissfully ignoring the most fundamental manufacturing realities because they’ve been issued a vehicle design diploma without ever see a technical drawing and a typical section.
I’ve seen 1:1 scale “epowood” (rigid resinous material used to make life-size vehicle mock-ups) models milled with bonnets whose shape could not be stamped, with shut-lines placed regardless of manufacturing technology, Once, and this is one I’ll never forget, I’ve “taught” a smooth-talking, supposedly experienced colleague how to calculate the total diameter of a tire in millimeters from the sizes written on its sidewall. Enough said.
While the world certainly has worse problems than this, I feel for the families who get tricked into spending large sums on courses and masters whose titles sound impressive but offer little actual value in exchange.
Is there a solution?
Of course, there is. The formation of future automobile designers should be taken over by the automobile industry itself. Each year, according to their actual necessities, each manufacturer’s design studio should train a small number of thoroughly vetted candidates for free in exchange for a few years of a contractual commitment to the company once tuition will end.
I’m under no illusion it’ll ever be put into practice, but I believe it’s high time to have this discussion within the automobile design business.
Zoom became one of this year’s big success stories for real-time video communications, as the rapid shift to remote work forced businesses to rethink their operations. Now a new startup is setting out to become the go-to platform for asynchronous video communications.
There is no shortage of non-real-time communication tools that allow globally distributed teams to check in with each other — email and Slack, for starters. But Supernormal is meshing video messaging with some nifty AI smarts to bring more engagement and utility to “async” interactions, where nuance and meaning isn’t lost amid a barrage of emojis. At a time when companies are increasingly committing to a distributed workforce spread across multiple time zones, Supernormal could carve itself a niche in a space awash with real-time video and voice tools.
“Supernormal is focused on helping teams communicate async and enabling key personas — engineers, designers, managers — to have creative time and choose when they want to consume or create team communication,” cofounder and CEO Colin Treseler told VentureBeat.
To aid its mission, the company today announced it has raised $2 million in a seed round of funding led by EQT Ventures, with support from several angel investors.
Supernormal (in the new normal)
Available via the web or through a desktop Mac app, Supernormal allows users to record company (or personal) announcements, presentations, greetings, or just about anything else. A separate function lets users record their screen in order to give presentations or product walkthroughs, with a little video avatar of the speaker embedded inside the screencast.
The app uses natural language processing (NLP) to instantly transcribe content and provide it as text beside the video while also extracting what it thinks are the three most interesting sentences from a transcript to suggest as caption summaries.
According to Treseler, the company develops its AI system “mostly” in-house. “We’ve built our own machine learning for detecting the most interesting sentences and have trained it on a massive corpus,” Treseler said.
Above: Supernormal: Screen recording with video message overlay
For businesses that sign up using their Slack or Google account credentials, Supernormal also automatically tags specific users in a company if their name is mentioned in the video, alerting the individual via Slack or Gmail. Presenters are notified whenever their team or intended audience has viewed the video, enabling them to follow up with any relevant communications.
Above: Supernormal: Text extraction and automatic alerts
Videos can also be embedded into digital properties such as websites, and dedicated links can be manually shared through any app. If they’re shared on Twitter, Slack, Facebook, or Microsoft Teams, they can be viewed inline directly on those platforms. Anywhere else, the user will have to click to view the video on the Supernormal platform itself.
There are other notable players in the space. San Francisco-based Loom is perhaps the most obvious example, having raised nearly $75 million in funding — including a $29 million tranche in the midst of the pandemic — from notable investors that include Sequoia Capital, Coatue, Kleiner Perkins, and Instagram’s founders. Founded in 2016, Loom has a bit of a head start and an impressive roster of clients, including Atlassian, Intercom, and HubSpot. It also offers additional smarts, such as a drawing tool, allowing presenters to illustrate or highlight specific items on their screen.
Prezi is doing some interesting things in the video presentation realm, though it’s aimed at a different market. Elsewhere, Slack is gearing up to launch a new Stories feature, which are essentially video-based status updates along the lines of Snapchat and Instagram’s consumer versions. Don’t be surprised if Microsoft follows suit with something similar for Teams.
Although it’s still early days for Supernormal, the startup’s use of AI to generate transcriptions, summaries, and smart alerts makes it worth keeping tabs on.
There are also potential use cases far beyond the enterprise, as Loom has demonstrated. For example, teachers struggling to get their entire class online for a live demo could simply record a short video-based presentation and send it by email for the students to view on their own time.
“Right now, we are seeing a lot of use by ‘prosumers,’ and we are open to education/nonprofits,” Treseler said. “Our core focus, however, will be on teams at the enterprise level.”
The story so far
As is increasingly the case with companies these days, Supernormal can’t be pinned to one location, with a workforce spanning the Americas and Europe. Treseler is currently based in Stockholm, Sweden, though he has served in various technical roles on both sides of the Atlantic over the past decade, including a two-year stint as a Facebook product manager in Menlo Park, California.
Treseler and his team started work on Supernormal in January, fortuitous timing given how global events would unfold in the months that followed. “When we started to create our solution, we didn’t expect every business to be relying on virtual communication this heavily,” Treseler said.
Supernormal was initially trying to be more of a catch-all video communication tool, but the company ultimately decided to go all-in on recorded video.
“We had live video in the initial product but felt that it wasn’t additive to the team experience and was not helping our core focus — shifting teams to becoming more asynchronous,” Treseler said.
Since its official launch in August, Supernormal claims it has been picked up by more than 400 teams, with workers at companies like Spotify and GitHub, and has seen “heavy engagement” across the spectrum, from SMBs to Fortune 500 companies.
The company is now working on native apps for Windows desktop and smartphones, along with one-click editing tools that enable users to remove pauses or specific words or sentences from transcripts. Treseler said the team is also exploring additional data reporting and analytics tools for customer-facing roles, such as sales and customer support.
In terms of pricing, it is entirely free for now, as the product is developed and iterated. But Supernormal will eventually adopt a SaaS model, with pricing to be determined. “We’ll eventually get to pricing that is considerably cheaper than the competitors in the space,” Treseler said.
With an extra $2 million in the bank, Treseler said the company will now double down on product development and expand its “fully remote team” around the world.
from VentureBeat https://venturebeat.com/2020/12/01/supernormal-brings-ai-powered-asynchronous-video-messaging-to-remote-teams/
When it comes to interaction design, visibility of system status is the first of Jakob Nielsen’s ten heuristics of usability. These principles date all the way back to the 90s and remain as the general rules of thumb today in the design of interfaces, as well as experiences beyond the screen.
In this article, I want to take a dive into the first heuristic. The visibility of system status is all about leveraging the use of clear communication and transparency in order to build trust and provide a great experience.
Let’s take a look at a few examples of this in action.
The visibility of system status refers to how well the state of the system is conveyed to its users. Ideally, systems should always keep users informed about what is going on, through appropriate feedback within reasonable time.
Important and timely feedback
When a user interacts with a website or app, the most important thing they need to know is whether their action was recognized. This is true for everyday experiences as well. Think about taking an elevator ride up to your office or apartment. How frustrating would it be if the buttons didn’t immediately light up in response to you pressing it? You would be left wondering if the system received your action or if it was working at all.
In digital design, visual feedback can exist in the form of color or state changes or progress indicators. This relays to the user that the system is working and reduces uncertainty about the action.
This example from Loom’s sign up page really takes it to the next level. Real-time feedback during your new account set-up communicates which password requirements you’ve fulfilled as you type, saving you time, energy, and uncertainty during the process.
Petition to have all forms designed this beautifully
Where you are and where you can go
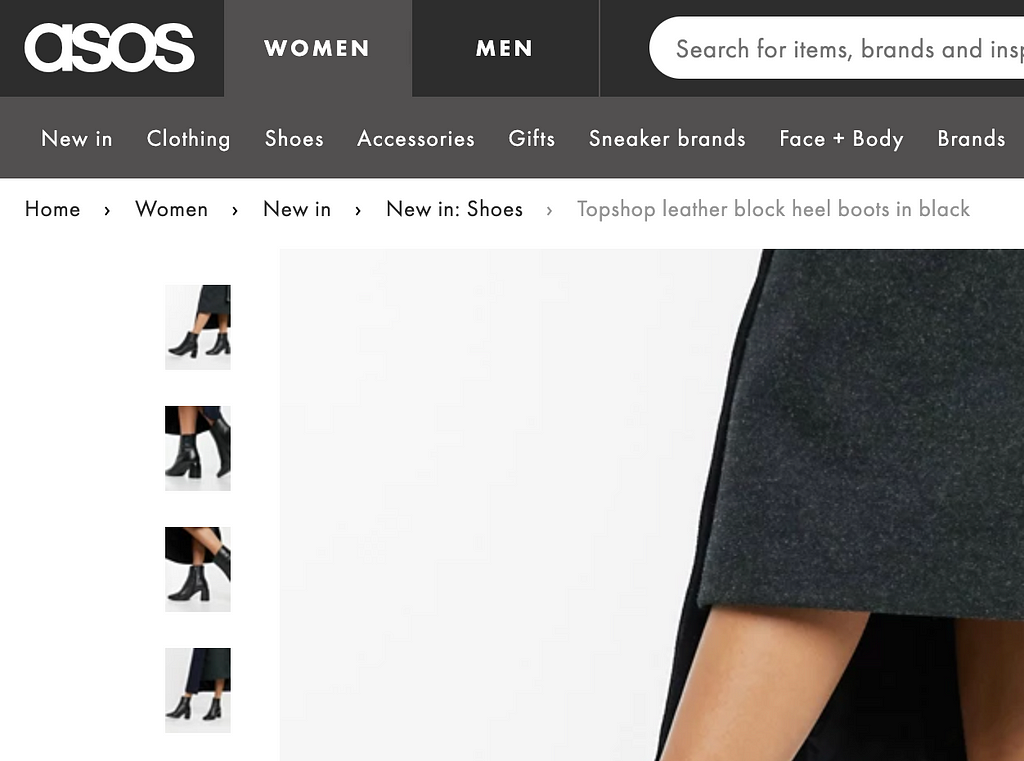
No one likes to feel lost, whether it’s somewhere in person or online. That leads us to another system status that falls under this usability principle. When navigating a site or an app, the user should be informed of where they are on the site. This can be achieved in the form of highlighted menu labels or use of breadcrumbs. Breadcrumbs help users understand their location by showing them how they arrived at their current page and can even lead them to other relevant pages.
The breadcrumb trail shows the location of the current page within the hierarchy of ASOS’s site
Open communication
You probably wouldn’t be be very happy if any of your friends changed their dinner plans with you without ever updating you. That same idea applies to users as they should always be informed of any changes made in the system.
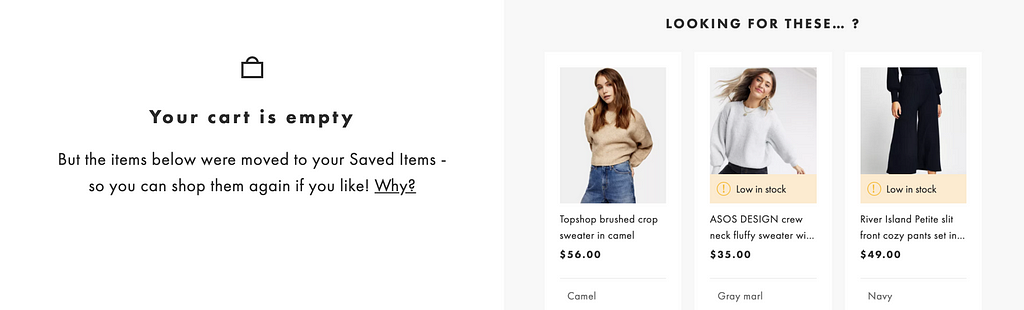
Take for example, my shopping cart on ASOS. After 60 minutes, my items are automatically moved to my saved items. If I left and came back the next day, I might be wondering why my cart is empty. The site does a great job of letting me know that all my items were moved and can be be easily accessed under saved items.
ASOS cart updates
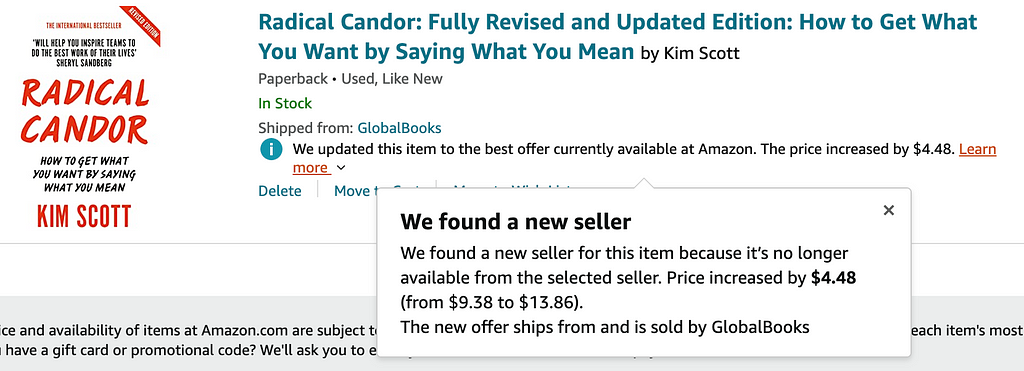
Another example can be seen on Amazon. I probably wouldn’t notice if the seller or price for a book changes in my cart, but they make sure to clearly indicate the details of any changes that might have occurred while I was away.
Amazon cart updates
To sum it up, the visibility of system status heuristic encourages open and continuous communication to enable a smoother experience for the user. It’s easy to see how this principle applies to our relationships with devices as much as it does to our relationships with other people.
Handing over single page designs is pretty straight forward: export web preview, drop it on Netlify and you’re done. In theory. There is a couple of pitfalls though.
I decided to use solely Framer X for my work at SatoshiPay, where I lead the design efforts. The unique product we are building requires unconventional interactions that would be hard to produce unless you had React and a ton of tutorials at hand — more on that later.
To keep existing workflows (almost) intact, first, I had to figure out a simple way to hand over static designs just like the all-too-familiar Sketch and InVision combo.
Prepare for different screen sizes
Before you dig into exporting stuff, take a minute to think of different screen sizes. Your peers might be using different monitors with different screen resolutions. To make sure your design looks like it should, check the following:
Set the preview window to ‘Canvas — Responsive’
Set constraints for different frames according to your needs and test them in the preview window
To make sure everyone sees the exact same results, you’ll need to add the custom fonts you’ve used that others might not have installed on their computers.
Install the Font Files package by Jordan Dobson, and follow the installation instructions:
Export Web Preview
Easy. Go to File — Export Web Preview…
Add a couple of lines to the CSS
To make sure tools like Prism or CSSPeeper can inspect your designs you need one last change to make: open build/style.css in the exported Web Preview folder, and add the following lines at the end of the document:
All there is left to do is to publish your design. Sign up for a Netlify account (its free), and simply drop the exported Web Preview folder onto it. In a second, your page will be live at the generated URL.
Inspect your designs with Prism or CSSPeeper and you should see dimensions, colors, and fonts. Bam its done.
Tip:Change the site URL to something easier to find before its too late
Hope this helps. Keep Framering.
from Medium https://dnlklmn.medium.com/how-to-hand-over-designs-created-in-framer-x-bc4233cd6f5f
Now, whether that phrase takes you back to a simpler (maybe? I don’t know, I was born in the 80s) time of gold panning, Mark Twain, and metallurgical assay — or just makes you want some Velveeta shells and liquid gold (I also might be hungry) — the point is, there is a lot you can learn from analyzing search results.
Search engine results pages (SERPs) are the mountains we’re trying to climb as SEOs to reach the peak (number one position). But these mountains aren’t just for climbing — there are numerous “nuggets” of information to be mined from the SERPs that can help us on our journey to the mountaintop.
Earning page one rankings is difficult — to build optimized pages that can rank, you need comprehensive SEO strategy that includes:
Content audits
Keyword research
Competitive analysis
Technical SEO audits
Projections and forecasting
Niche and audience research
Content ideation and creation
Knowledge and an understanding of your (or your client’s) website’s history
And more.
A ton of work and research goes into successful SEO.
Fortunately, much of this information can be gleaned from the SERPs you’re targeting, that will in turn inform your strategy and help you make better decisions.
The three main areas of research that SERP analysis can benefit are:
Keyword research
Content creation
And competitive analysis.
So, get your pickaxe handy (or maybe just a notebook?) because we’re going to learn how to mine the SERPs for SEO gold!
Finding keyword research nuggets
Any sound SEO strategy is built on sound keyword research. Without keyword research, you’re just blindly creating pages and hoping Google ranks them. While we don’t fully understand or know every signal in Google’s search algorithm — I’m pretty confident your “hopes” aren’t one of them — you need keyword research to understand the opportunities as they exist.
And you can find some big nuggets of information right in the search results!
First off, SERP analysis will help you understand the intent (or at least the perceived intent by Google) behind your target keywords or phrases. Do you see product pages or informational content? Are there comparison or listicle type pages? Is there a variety of pages serving multiple potential intents? For example:
Examining these pages will tell you which page — either on your site or yet to be created — would be a good fit. For example, if the results are long-form guides, you’re not going to be able to make your product page rank there (unless of course the SERP serves multiple intents, including transactional). You should analyze search intent before you start optimizing for keywords, and there’s no better resource for gauging searcher intent than the search results themselves.
You can also learn a lot about the potential traffic you could receive from ranking in a given SERP by reviewing its makeup and the potential for clicks.
Of course, we all want to rank in position number one (and sometimes, position zero) as conventional wisdom points to this being our best chance to earn that valuable click-through. And, a recent study by SISTRIX confirmed as much, reporting that position one has an average click-through rate (CTR) of 28.5% — which is fairly larger than positions two (15.7%) and three (11%).
But the most interesting statistics within the study were regarding how SERP layout can impact CTR.
Some highlights from the study include:
SERPs that include sitelinks have a 12.7% increase in CTR, above average.
Position one in a SERP with a featured snippet has a 5.2% lower CTR than average.
Position one in SERPs that feature a knowledge panel see an 11.8% dip in CTR, below average.
SERPs with Google Shopping ads have the worst CTR: 14.8% below average.
SISTRIX found that overall, the more SERP elements present, the lower the CTR for the top organic position.
This is valuable information to discover during keyword research, particularly if you’re searching for opportunities that might bring organic traffic relatively quickly. For these opportunities, you’ll want to research less competitive keywords and phrases, as the SISTRIX report suggests that these long-tail terms have a larger proportion of “purely organic SERPs (e.g. ten blue links).
To see this in action, let’s compare two SERPs: “gold panning equipment” and “can I use a sluice box in California?”.
Here is the top of the SERP for “gold panning equipment”:
And here is the top of the SERP for “can I use a sluice box in California?”:
Based on what we know now, we can quickly assess that our potential CTR for “can I use a sluice box in California?” will be higher. Although featured snippets lower CTR for other results, there is the possibility to rank in the snippet, and the “gold panning equipment” SERP features shopping ads which have the most negative impact (-14.8%) on CTR.
Of course, CTR isn’t the only determining factor in how much traffic you’d potentially receive from ranking, as search volume also plays a role. Our example “can I use a sluice box in California?” has little to no search volume, so while the opportunity for click-throughs is high, there aren’t many searching this term and ranking wouldn’t bring much organic traffic — but if you’re a business that sells sluice boxes in California, this is absolutely a SERP where you should rank.
Keyword research sets the stage for any SEO campaign, and by mining existing SERPs, you can gain information that will guide the execution of your research.
Mining content creation nuggets
Of course, keyword research is only useful if you leverage it to create the right content. Fortunately, we can find big, glittering nuggets of content creation gold in the SERPs, too!
One the main bits of information from examining SERPs is which types of content are ranking — and since you want to rank there, too, this information is useful for your own page creation.
For example, if the SERP has a featured snippet, you know that Google wants to answer the query in a quick, succinct manner for searchers — do this on your page. Video results appearing on the SERP? You should probably include a video on your page if you want to rank there too. Image carousel at the top? Consider what images might be associated with your page and how they would be displayed.
You can also review the ranking pages to gain insight into what formats are performing well in that SERP. Are the ranking pages mostly guides? Comparison posts? FAQs or forums? News articles or interviews? Infographics? If you can identify a trend in format, you’ve already got a good idea of how you should structure (or re-structure) your page.
Some SERPs may serve multiple intents and display a mixture of the above types of pages. In these instances, consider which intent you want your page to serve and focus on the ranking page that serves that intent to glean content creation ideas.
Furthermore, you can leverage the SERP for topic ideation — starting with the People Also Ask (PAA) box. You should already have your primary topic (the main keyword you’re targeting), but the PAA can provide insight into related topics.
Here’s an example of a SERP for “modern gold mining techniques”:
Right there in the PAA box, I’ve got three solid ideas for sub-topics or sections of my page on “Modern Gold Mining”. These PAA boxes expand, too, and provide more potential sub-topics.
While thorough keyword research should uncover most long-tail keywords and phrases related to your target keyword, reviewing the People Also Ask box will ensure you haven’t missed anything.
Of course, understanding what types of formats, structures, topics, etc. perform well in a given SERP only gets you part of the way there. You still need to create something that is better than the pages currently ranking. And this brings us to the third type of wisdom nuggets you can mine from the SERPs — competitive analysis gold.
Extracting competitive analysis nuggets
With an understanding of the keywords and content types associated with your target SERP, you’re well on your way to staking your claim on the first page. Now it’s time to analyze the competition.
A quick glance at the SERP will quickly give you an idea of competition level and potential keyword difficulty. Look at the domains you see — are there recognizable brands? As a small or new e-commerce site, you can quickly toss out any keywords that have SERPs littered with pages from Amazon, eBay, and Wal-Mart. Conversely, if you see your direct competitors ranking and no large brands, you’ve likely found a good keyword set to target. Of course, you may come across SERPs that have major brands ranking along with your competitor — if your competitor is ranking there, it means you have a shot, too!
But this is just the surface SERP silt (say that five times fast). You need to mine a bit deeper to reach the big, golden competitive nuggets.
The next step is to click through to the pages and analyze them based on a variety of factors, including (in no particular order):
If the page is lacking in any, many, or all these areas, there is a strong opportunity your page can become the better result, and rank.
You should also review how many backlinks ranking pages have, to get an idea for the range of links you need to reach to be competitive. In addition, review the number of referring domains for each ranking domain — while you’re competing on a page-to-page level in the SERP, there’s no doubt that pages on more authoritative domains will benefit from that authority.
However, if you find a page that’s ranking from a relatively unknown or new site, and it has a substantial amount of backlinks, that’s likely why it’s ranking, and earning a similar amount of links will give your page a good chance to rank as well.
Lastly, take the time to dive into your competitor’s ranking pages (if they’re there). Examine their messaging and study how they’re talking to your shared audience to identify areas where your copy is suboptimal or completely missing the mark. Remember, these pages are ranking on page one, so they must be resonating in some way.
Conclusion
Successful SEO requires thorough research and analysis from a variety of sources. However, much of what you need can be found in the very SERPs for which you’re trying to rank. After all, you need to understand why the pages that rank are performing if you want your pages to appear there, too.
These SERPs are full of helpful takeaways in terms of:
Keyword research and analysis
Content ideation and strategy
And competitive analysis and review.
These golden nuggets are just there for the takin’ and you don’t need any tools other than Google and your analytical mind — well, and your metaphorical pickaxe.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
from Moz https://moz.com/blog/mining-seo-insights-from-search-results
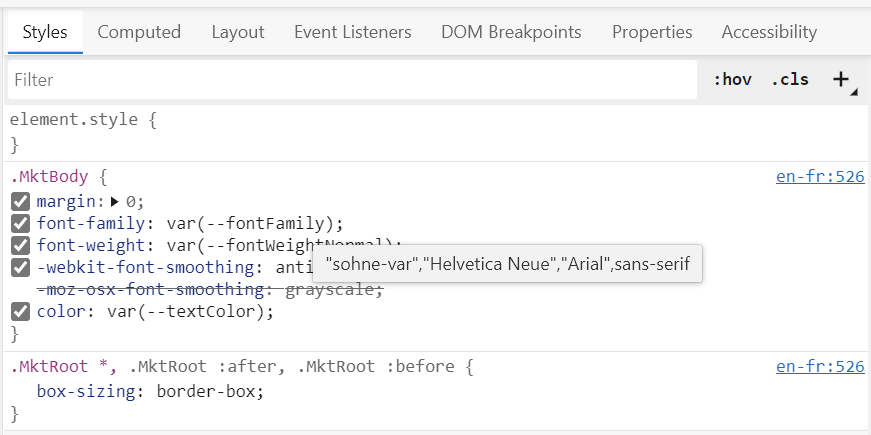
CSS variables (or custom properties, depending on how you prefer to call them) are really cool, and chances are, you’re already using them in your projects already.
In this article, I’ll talk about 3 things that I think a lot of people might now know about:
what happens when a var() function uses an undefined variable,
how fallback values work,
and how browser DevTools can help you.
Undefined variables
There are several reasons why you may be trying to use an undefined variable in a var() function. We’ll look at a few in a minute. But before we do that, it’s important to know that when this happens, CSS falls back on its feet.
CSS and HTML are super resilient languages where mistakes are forgiven and one tiny error doesn’t prevent the entire page from rendering.
So, using an undefined variable won’t lead to a parsing error, it won’t prevent your stylesheet to load or parse or render. In fact, you might not even realize that something went wrong without a lot of investigation.
Some of the reasons using an undefined variable might happen are:
you’ve simply made a typo in the name of the variable,
you’re trying to use a variable you thought existed, but doesn’t,
or you’re trying to use a totally valid variable, but it happens to not be visible where you want to use it.
Let’s go over that last example.
Variables participate in the cascade. This means, for a variable to be available to a var() function, that variable needs to be declared in a rule that also applies to the element being styled, or to one of its ancestors.
For the sake of giving an example, let’s look at this:
ol li{--foo: red;} ul li{color:var(--foo);}
Of course your particular case will likely be more complicated than this, with many more rules and much more complicated selectors. But what happens here is that for ul li elements to have the color red, they would also need to match the rule ol li where that color is actually defined. And that will probably not happen.
Now, in many cases, CSS variables tend to get defined in some top-level selector like :root or html and are therefore available throughout the DOM tree (those selectors match ancestor elements of all other elements in the page).
In this case, the problem of a missing variable almost never occurs.
However sometimes it’s handy to declare variables in other places and when you do this, you’ve got to start paying more attention to whether your variable will actually be visible (via the cascade) to where you intend to use it.
So, with this out of the way, let’s see how browsers deal with undefined variables:
If the property is not inheritable (like border), then the property is set to its initial value.
If it is inheritable (like color), then the property is set to its inherited value. If there isn’t any, then it is set to its initial value.
Let’s look at 2 examples to illustrate this:
:root{ --main-color: #f06; }
.my-lovely-component{
border: 1px solid var(--main-colo); }
In this first example above, a typo was made in var(-main-colo) and as a result the browser cannot tell what the final value for the border property should be. Because the border property is not inheritable in CSS, the browser finds itself in case 1 from above. It therefore sets the value to its initial state which happens to be medium none currentColor (see the initial value on MDN).
So, even if only the color part of the border was missing, the border will be missing entirely.
Let’s look at a second example now.
:root{ --main-color: #f06; }
body{
color: gold; }
.my-lovely-component{
color:var(--secondary-color); }
In this one, an undefined variable was used in .my-lovely-component for the value of color.
Now, because this property is inherited, the browser will traverse the DOM up through the element’s ancestors until it finds one that does define a color value. The <body> element has a rule applied to it that specifies gold as a value, so that’s what will end up being used.
In both of these examples, the hard part is figuring out what’s happening exactly. In the last part of this article, I’ll explain how DevTools can help, but without specific tooling here, it would be really hard to understand the problem.
The source of it is that, even if those var() functions use invalid properties, when the browser parses the stylesheet, it has no way of knowing this. As far as it’s concerned, those border and color properties are totally valid. So we’re left with wondering why the border is missing in the first example, and why the color is black in the second.
Property names or values are only considered invalid by the style engine in a browser when those are not known. But since a var() function can resolve to pretty much anything at all, the style engine doesn’t know whether the value containing the function is known or not.
It will only know when the property actually gets used, at which point, it will fall back to an inherited or initial state silently, and leave you wondering what happened.
Thankfully, we’ll see later in this article how some new DevTools can help with this.
Fallback values and nesting
Here is another thing about CSS variables that doesn’t seem to get used a lot, and therefore is probably not very well known either: var() functions accept a second, optional, parameter.
So you can write something like this:
color:var(--theme-color, red);
What happens in this case is: if --theme-color is not found by the browser, it will fall back to using the value red.
Now, why would you use this? I can see a few reasons why this could be interesting:
It might come in handy if you’re creating a component that gets embedded into a bigger system and can be customized with variables, but you still want some safe defaults.
Or maybe you’re styling an element that has several states, with the default state using a var() with fallback value, and the other state defining the variable.
Let me give an example to clarify that second case:
In this example, while the element isn’t being hovered, its color property uses an undefined variable (indeed, the --active-color property does not apply to the element yet), so the browser uses the fallback value. As soon as the user hovers over the element, the second rule starts to apply, and --active-color becomes defined, so the element switches to red.
Of course, this is a dummy example, and you could simply have defined color: red in the second rule and let it override the first one. But sometimes you need to use the variable in several properties at once.
Now, let’s look at a second weird thing that happens with fallback values: nesting var() functions.
This is totally valid, but probably completely useless.
What’s happening here is that the fallback value is, itself, another var() function. And because it is, it (in turn) can also use a fallback value, and so on…
To be honest, I don’t think I’ve seen var() functions used as fallback values very often, if at all. Fallback values themselves are probably rarely used to begin with.
But at least you know this is possible, and hopefully won’t be surprised if you ever see this.
Let me conclude on fallback values by looking at a third aspect which I think is rarely known and may lead to confusion: using commas.
A CSS variable is, basically, any text you want. Because a variable can be used anywhere a value would go, it doesn’t have any strong typing at all, and therefore the only important rule is that it shouldn’t contain a semicolon, since that signifies the end of the value (in reality, it’s more complicated than this).
As a result, something like this is valid:
--my-variable: one, two, three;
The interesting thing here is that fallback values also follow the same rule in that they can be any text you want. So the above example could also be used as a fallback value:
content:var(--foo, one, two, three);
Even though it really looks like the one, two, three part is three different parameters to the var() function, it’s really just one. Don’t get confused by that.
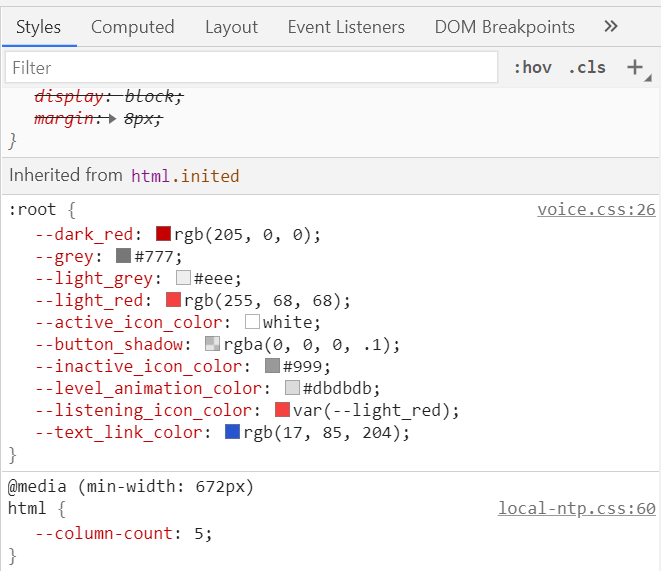
DevTools tips and tricks
In this last section I’ll go over some of the DevTools around CSS variables that you might now know about and which should make your life easier.
Autocompleting variable names
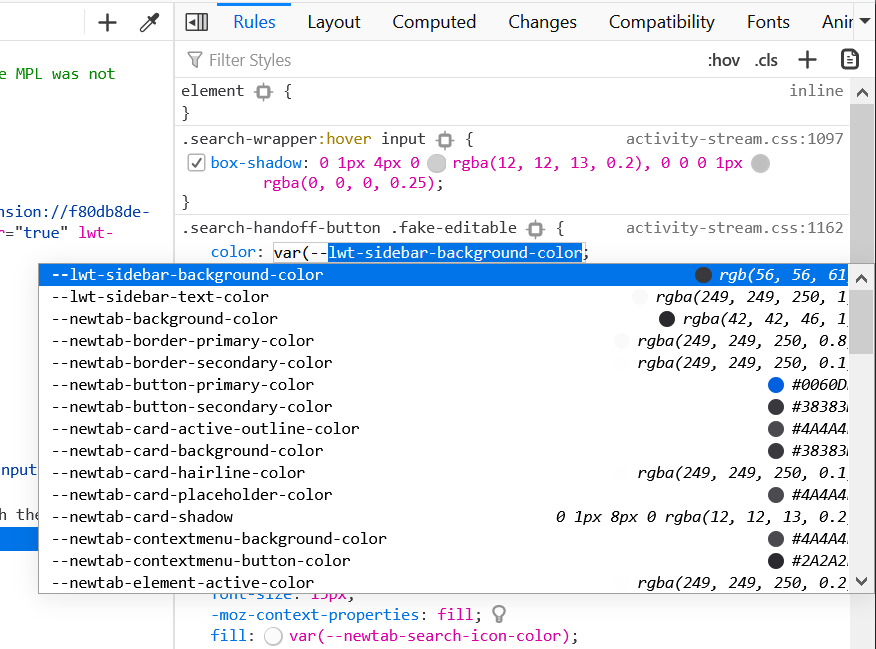
This one is super useful when doing some quick changes in the Elements/Inspector panel and your site defines a lot of different variables:
DevTools will automatically suggest the list of existing variables when you start typing var(.
The above screenshot is in Firefox, but both Edge and Chrome also support this feature.
Knowing what the computed value is
When looking at a var() function in DevTools, it’s not necessarily easy to know what final value it computes to. The variable it uses may be lost in a really long list of rules, or it may itself point to another variable, making the hunt for the final value more difficult.
You can switch to the Computed tab in DevTools to see what the final computed value of the entire property is. But if you want to know what the computed value for just that var() function is, you can simply hover over it in DevTools:
The above screenshot is in Edge, but the same thing happens in Chrome and Firefox too.
Interestingly, if no tooltip appears, then that’s a good clue that the variable used is undefined.
Color types
A little earlier, I said that variables accepted any text at all, because when they’re defined, variables don’t really have a type yet.
A consequence of this is that what looks like a color may actually not be used as a color.
Consider the following example:
:root{ --i-look-like-a-color: black; }
Even thought black is a valid color, at this point, we can’t assume that it will actually be used as one. It may end up being used in a animation-name property, or somewhere else.
That said, DevTools still show a little color swatch next to css variables that look like colors. That is done as a convenience, because they are very likely to actually be colors! And even if they aren’t, it’s not going to be a problem for users.
Future features
Now, 2 things that, I think, would be super useful but don’t exist yet is:
jumping from a var() function to where the variable used in it is declared,
quickly seeing that a var() function uses an undefined variable.
As it turns out, I’m working on exactly that right now in the DevTools for Chromium-based Edge and Chrome! You can check out the bug entry to follow along if you want.
Hopefully this article has been useful and you learnt a few things! Happy coding!
from patrickbrosset.com https://patrickbrosset.com/articles/2020-09-21-3-things-about-css-variables-you-might-not-know/
Extremely energy-efficient artificial intelligence is now closer to reality after a study by UCL researchers found a way to improve the accuracy of a brain-inspired computing system.
The system, which uses memristors to create artificial neural networks, is at least 1,000 times more energy efficient than conventional transistor-based AI hardware, but has until now been more prone to error.
Existing AI is extremely energy-intensive — training one AI model can generate 284 tonnes of carbon dioxide, equivalent to the lifetime emissions of five cars. Replacing the transistors that make up all digital devices with memristors, a novel electronic device first built in 2008, could reduce this to a fraction of a tonne of carbon dioxide — equivalent to emissions generated in an afternoon’s drive.
Since memristors are so much more energy-efficient than existing computing systems, they can potentially pack huge amounts of computing power into hand-held devices, removing the need to be connected to the Internet.
This is especially important as over-reliance on the Internet is expected to become problematic in future due to ever-increasing data demands and the difficulties of increasing data transmission capacity past a certain point.
In the new study, published in Nature Communications, engineers at UCL found that accuracy could be greatly improved by getting memristors to work together in several sub-groups of neural networks and averaging their calculations, meaning that flaws in each of the networks could be cancelled out.
Memristors, described as “resistors with memory,” as they remember the amount of electric charge that flowed through them even after being turned off, were considered revolutionary when they were first built over a decade ago, a “missing link” in electronics to supplement the resistor, capacitor and inductor. They have since been manufactured commercially in memory devices, but the research team say they could be used to develop AI systems within the next three years.
Memristors offer vastly improved efficiency because they operate not just in a binary code of ones and zeros, but at multiple levels between zero and one at the same time, meaning more information can be packed into each bit.
Moreover, memristors are often described as a neuromorphic (brain-inspired) form of computing because, like in the brain, processing and memory are implemented in the same adaptive building blocks, in contrast to current computer systems that waste a lot of energy in data movement.
In the study, Dr Adnan Mehonic, PhD student Dovydas Joksas (both UCL Electronic & Electrical Engineering), and colleagues from the UK and the US tested the new approach in several different types of memristors and found that it improved the accuracy of all of them, regardless of material or particular memristor technology. It also worked for a number of different problems that may affect memristors’ accuracy.
Researchers found that their approach increased the accuracy of the neural networks for typical AI tasks to a comparable level to software tools run on conventional digital hardware.
Dr Mehonic, director of the study, said: “We hoped that there might be more generic approaches that improve not the device-level, but the system-level behaviour, and we believe we found one. Our approach shows that, when it comes to memristors, several heads are better than one. Arranging the neural network into several smaller networks rather than one big network led to greater accuracy overall.”
Dovydas Joksas further explained: “We borrowed a popular technique from computer science and applied it in the context of memristors. And it worked! Using preliminary simulations, we found that even simple averaging could significantly increase the accuracy of memristive neural networks.”
Professor Tony Kenyon (UCL Electronic & Electrical Engineering), a co-author on the study, added: “We believe now is the time for memristors, on which we have been working for several years, to take a leading role in a more energy-sustainable era of IoT devices and edge computing.”
from ScienceDaily – Artificial Intelligence https://www.sciencedaily.com/releases/2020/08/200827150957.htm
[This article was first published on R – Myscape, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don’t.
Exact tests often are a good place to start with differential expression analysis of genomic data sets.
Example mean difference (MD) plot of exact test results for the E05 Daphnia genotype.
As usual, the types of contrasts you can make will depend on the design of your study and data set. In the following example we will use the raw counts of differentially expressed (DE) genes to compare the following Daphnia genotypes.
The design of our experiment is described by three replicates of ultra-violet radiation (UV) treatment, and three replicates of visible light (VIS) control for each of the Daphnia genotypes.
After normalization of raw counts we will perform genewise exact tests for differences in the means between two groups of gene counts. Specifically, the two experimental groups of treatment and control for the E05 Daphnia genotype.
D. melanica from the Olympic mountains in WA (left) and the Sierra Nevada mountains in CA (right).
Exact Test and Plotting Script – exactTest_edgeR.r
The following R script will be used to normalize raw gene counts produced by a quantification program such as Hisat2 or Tophat2. Then, we will perform exact tests for a specified genotype data set and plot both intermediate and final results.
We will use several different plotting functions to generate informative plots of our input data sets and exact test results with edgeR.
barplot – Bar plots of sequence read library sizes
plotMDS– Multi-dimensional scaling (MDS) scatterplot of distances between the samples
heatmap– Heatmaps of moderated log counts per million (logcpm)
plotBCV– Genewise biological coefficient of variation (BCV) plots against gene abundance
plotMD– Mean difference (MD) plots of all log fold change (logFC) against average count size
plotSmear– MA plots of log-intensity ratios (M-values) versus log-intensity averages (A-values)
Script Inputs
A csv formatted file of raw gene counts is expected as an input to the script. Below is an example raw gene count table where columns are samples, rows are gene IDs, and raw counts are represented by “N#” for simplicity here.
Additionally, the column numbers for the range of samples you wish to perform exact tests on need to be specified. So for example, the column numbers 1 and 6 should be input to perform an exact test on the E05 Daphnia genotype for the example raw gene count table above. This selects all replicates of the UV treatment and VIS control for the E05 genotype.
R Script
First, we should add some comments to the top of the R script describing how to run the script. We should also add a comment with a reminder of the purpose of the script.
#!/usr/bin/env Rscript
#Usage: Rscript exactTest_edgeR.r rawGeneCountsFile startColumn endColumn
#Usage Ex: Rscript exactTest_edgeR.r daphnia_rawGeneCounts_htseq.csv 1 6
#R script to perform exact test DE analysis of raw gene counts using edgeR
Before proceeding with plotting and exact tests we will need to import the edgeR library.
#Load the edgeR library
library("edgeR")
Next, we retrieve the input path for our raw gene counts and the column range for the exact test. The number of input arguments to the script are verified to help ensure that the required data is input to the script.
#Retrieve inputs to the script
args = commandArgs(trailingOnly=TRUE)
#Test if there is one input argument
if (length(args)!=3) {
stop("One file name and a range of columns must be supplied.n", call.=FALSE)
}
Now we can import our data with the input path to our raw gene counts and the column range for the sample we want to test.
#Import gene count data
countsTable <- read.csv(file=args[1], row.names="gene")[ ,args[2]:args[3]]
head(countsTable)
The samples that represent our treatment and control need to be specified as a grouping factor to perform the exact tests with edgeR. In our example input data set the samples are ordered as:
Treatment replicate 1
Treatment replicate 2
Treatment replicate 3
Control replicate 1
Control replicate 2
Control replicate 3
#Add grouping factor
group <- factor(c(rep("treat",3),rep("ctrl",3)))
#Create DGE list object
list <- DGEList(counts=countsTable,group=group)
This is a good point to generate some interesting plots of our input data set before we begin preparing the raw gene counts for the exact test.
First, we will plot the library sizes of our sequencing reads before normalization using the barplot function. The resulting plot is saved to the plotBarsBefore jpg file in your working directory.
#Plot the library sizes before normalization
jpeg("plotBarsBefore.jpg")
barplot(list$samples$lib.size*1e-6, names=1:6, ylab="Library size (millions)")
dev.off()
Next, we will use the plotMDS function to display the relative similarities of the samples and view batch and treatment effects before normalization. The resulting plot is saved to the plotMDSBefore jpg file in your working directory.
#Draw a MDS plot to show the relative similarities of the samples
jpeg("plotMDSBefore.jpg")
plotMDS(list, col=rep(1:3, each=3))
dev.off()
It can also be useful to view the moderated log-counts-per-million before normalization using the cpm function results with heatmap. The resulting plot is saved to the plotHeatMapBefore jpg file in your working directory.
#Draw a heatmap of individual RNA-seq samples
jpeg("plotHeatMapBefore.jpg")
logcpm <- cpm(list, log=TRUE)
heatmap(logcpm)
dev.off()
There is no purpose in analyzing genes that are not expressed in either experimental condition (treatment or control), so raw gene counts are first filtered by expression levels. The normalized gene counts are output to the stats_normalizedCounts csv file.
#Filter raw gene counts by expression levels
keep <- filterByExpr(list)
table(keep)
list <- list[keep, , keep.lib.sizes=FALSE]
#Calculate normalized factors
list <- calcNormFactors(list)
#Write normalized counts to file
normList <- cpm(list, normalized.lib.sizes=TRUE)
write.table(normList, file="stats_normalizedCounts.csv", sep=",", row.names=TRUE)
#View normalization factors
list$samples
dim(list)
Now that we have normalized gene counts for our samples we should generate the same set of previous plots for comparison.
First, we plot the library sizes of our sequencing reads after normalization using the barplot function. The resulting plot is saved to the plotBarsAfter jpg file in your working directory.
#Plot the library sizes after normalization
jpeg("plotBarsAfter.jpg")
barplot(list$samples$lib.size*1e-6, names=1:6, ylab="Library size (millions)")
dev.off()
Next, we will use the plotMDS function to display the relative similarities of the samples and view batch and treatment effects after normalization. The resulting plot is saved to the plotMDSAfter jpg file in your working directory.
#Draw a MDS plot to show the relative similarities of the samples
jpeg("plotMDSAfter.jpg")
plotMDS(list, col=rep(1:3, each=3))
dev.off()
It can also be useful to view the moderated log counts per million (logcpm) after normalization using the cpm function results with heatmap. The resulting plot is saved to the plotHeatMapAfter jpg file in your working directory.
#Draw a heatmap of individual RNA-seq samples
jpeg("plotHeatMapAfter.jpg")
logcpm <- cpm(list, log=TRUE)
heatmap(logcpm)
dev.off()
With the normalized gene counts we can also produce a matrix of pseudo-counts to estimate the common and tagwise dispersions. This allows us to use the plotBCV function to generate a genewise biological coefficient of variation (BCV) plot of dispersion estimates. The resulting plot is saved to the plotBCVResults jpg file in your working directory.
#Produce a matrix of pseudo-counts
list <- estimateDisp(list)
list$common.dispersion
#View dispersion estimates and biological coefficient of variation
jpeg("plotBCV.jpg")
plotBCV(list)
dev.off()
Finally, we are ready to perform exact tests with edgeR using the exactTest function. The resulting table of differentially expressed (DE) genes are written to the stats_exactTest csv file to your working directory.
#Perform an exact test for treat vs ctrl
tested <- exactTest(list, pair=c("ctrl", "treat"))
topTags(tested)
#Create results table of DE genes
resultsTbl <- topTags(tested, n=nrow(tested$table))$table
#Output resulting table
write.table(resultsTbl, file="stats_exactTest.csv", sep=",", row.names=TRUE)
Using the resulting DE genes from the exact test we can view the counts per million for the top genes of each sample.
#Look at the counts per million in individual samples for the top genes
o <- order(tested$table$PValue)
cpm(list)[o[1:10],]
#View the total number of differentially expressed genes at 5% FDR
summary(decideTests(tested))
We can also generate a mean difference (MD) plot of the log fold change (logFC) against the log counts per million (logcpm) using the plotMD function. DE genes are highlighted and the blue lines indicate 2-fold changes. The resulting plot is saved to the plotMDResults jpg file in your working directory.
#Make a MD plot of logFC against logcpm
jpeg("plotMDResults.jpg")
plotMD(tested)
abline(h=c(-1, 1), col="blue")
dev.off()
As a final step, we will produce a MA plot of the libraries of count data using the plotSmear function. There are smearing points with very low counts, particularly those counts that are zero for one of the columns. The resulting plot is saved to the plotMAResults jpg file in your working directory.
#Make a MA plot of the libraries of count data
jpeg("plotMAResults.jpg")
plotSmear(tested)
dev.off()
Every year there are dozens of new tools and trends that pop up in the software engineering industry. Now that I’ve been around for a while I think I’m starting to develop a decent radar for which trends are going to have a lasting impact and which ones are going to fizzle out. To be sure, I have made a few embarrassing predictions, such as betting one of my friends that Git would lose out to Mercurial because Git’s user ergonomics were so horrific. We all know how that turned out.
But overall I think I have a really good sense of what technologies will be winners, and what technologies will be losers. And when it comes to Serverless computing, I don’t need to use any of that expertise.
Wait, what?
Yeah, you read that right. It doesn’t take a prognosticator to see that Serverless computing is the future. Nobody wants to manage servers. Managing servers is a nasty side effect of wanting to execute code. I need a secure environment to run code, and because of von Neumann architecture I need some memory, some disk space, and a processor. It doesn’t really matter what form those items take, as long as I have enough. My code needs some amount of all three, and I need an environment that provides it to me. Simple.
My desire to accomplish that doesn’t mean I want to manage a server, or the environment in which it runs. In an ideal scenario I would just go up to a cloud provider and say, “Here is my app, run it for me.”
What is Serverless?
Before we get started, let’s get on the same page about what exactly Serverless is. You’ll see some definitions of Serverless that say it provides computing resources on an as-needed basis. While that is a purist definition, the more frequently used wider definition is that it is a way of providing computing resources in a way that doesn’t require you to think about managing servers.
Serverless comes in a few flavors
Serverless Containers
Serverless container services such as Heroku, Netlify, AWS ECS/EKS Fargate, Google Kubernetes Engine, and Azure Kubernetes Service provide you with an environment where you can build a container and push it up into a service that manages the deployment and execution of the container. You don’t have to worry about running the cluster that hosts your control servers, node servers, etc., you just have to push up a container with some metadata and the service handles the rest.
Serverless Functions
Serverless functions such as AWS Lambda, Google Cloud Functions, or Azure Functions are services that provide an environment where you can push up a chunk of code with a specific interface and later invoke that code.
Serverless vs Virtual Machines
Many people don’t consider Serverless containers to be true Serverless, because when you build and push a container you are essentially bundling a whole server in a nice package. While I tend to agree that they aren’t *true* Serverless, they have absolutely have enormous benefits over running a full Virtual Machine, and distinct advantages in some situations over Serverless functions.
Pros of Serverless Containers
Serverless containers have a ton of advantages over traditional servers. Here are a few of them:
Very little server management – No servers to manage, patch, or troubleshoot. You still have an operating system inside of the container, but that can be an incredibly minimal install, and the surface area of management is much smaller.
Generally stateless – When building applications designed for containers, you’re usually building a 12-factor app or following a similar pattern. Your containers are cattle, not pets. If your container crashes, a new one is automatically fired up.
Easy horizontal scalability – Nothing about a Virtual Machine is inherently limited in terms of scalability, but containers push you in a direction that allows Serverless Container services to easily scale your software as needed. Based on factors such as load, timing, and request count, your Serverless Container service can run one instance of your container or 10,000 instances of it all while transparently handling storage allocation, load balancing, routing, etc.
Security – The operating system installed in a container is usually short-lived, very minimal, and sometimes read-only. It therefore provides a much smaller attack surface than a typical general purpose and long-lived server environment.
Source controlled environment – Your container definition is described in a file that can be put into source control. While this is best practice in almost any situation these days, it is still a distinct advantage when compared with a traditional server environment where someone can get in and change things that make your server configurations drift.
Application and environment bundling – You’re combining your application with the environment it is running in, and deploying that as a single unit. This way if the new version of your software uses updated libraries, operating system version, or new language version, it can all be deployed, and rolled back, as a single unit.
Cost – You can easily scale your workloads up and down. While running a Serverless container might be a bit more expensive, with some providers you can make up for it in flexibility. Serverless containers usually provide you with more flexibility to slice up resources into smaller units than traditional Virtual Machine options. For instance, an EC2 T3 nano instance provides 2 vCPUs, but you can request a container with only 0.25 vCPUs.
Pros of Serverless Functions
Serverless functions have all of the advantages of Serverless containers, but take it to another level.
Virtually zero management – You don’t need to think about the OS at all in most instances. You can just push your code up, and then run it. There’s nothing at the OS level to patch, and nothing to maintain—just push it and forget it.
Stateless by default – Serverless functions force you to write your code in a stateless way, since you can’t depend on anything being left around between invocations. This allows them to easily scale, since your function can be fired up on any server without depending on local state.
Almost perfect horizontal scalability – Something invokes your function, and it runs. If it is invoked once, then it runs once. If it is invoked 100,000 times, then it runs 100,000 times. Sure, there are some platform limitations that might come into play, but those are generally safeguards to keep you from accidentally spending $10,000, rather than limitations of the platform.
Cost – Serverless functions only cost money while they are executing. So if you have functions that only execute rarely, or are very bursty, you can have significant savings.
Serverless Containers vs Serverless Functions
Advantages of Serverless Containers
Easy migration – If you have an existing application, it might take a bit of work, but you can get it running inside of a container.
Cheaper for stable workloads – If you have a consistent workload, then it is likely that Serverless containers will be cheaper than equivalent invocations of a Serverless function.
Flexibility – There are no limits to your OS, binaries, languages, versions, etc. you literally control the entire container. Serverless function services will limit you to particular runtimes and versions. Some Serverless function services allow custom runtimes, but you will still be locked into the OS.
Troubleshooting – Containers make it easy to jump in and troubleshoot what is happening in your live environment. They also allow you to run a chunk of your environment locally, which makes it easier to debug what is happening.
Long running tasks – A Serverless container runs all of the time, which suits long-running tasks best. Most Serverless functions are going to have limits around how long a function can execute. For example, as of this writing, AWS Lambda has a 15-minute limit.
Advantages of Serverless Functions
Lower cost for bursty workloads – Serverless functions are pay-per-invocation, meaning that you only pay when your code is actually executing. This means that for workloads that don’t run very often, they can be much cheaper in comparison to typical servers or containers.
Fast scaling – Serverless function services can create a new instance of your function and have it ready to serve traffic within a few seconds (sometimes with in a fraction of a second). There are certain limits to this, and you can see more discussion about those limits in the “Scaling Serverless functions” section below.
Fine-grained scalability – Let’s say you have an application that consists of a few dozen different Serverless functions, and one of those functions is called 1000 times more than the other functions. That one function will be scaled independently of the rest of your functions and you don’t even have to think about it. .
Disadvantages of Serverless Containers
Heavier deployments – Serverless containers usually require a large build step and then you have to push a several hundred megabyte container to your repository. Then you have to deploy your containers across your cluster which could take a while if you have large deployments. This turnaround time is significantly longer than pushing up a single cloud function and have it picked up and begin serving requests within a few seconds.
Coarse scalability – When you deploy out a Serverless function you are really just deploying out a single function. That function could perform multiple tasks, but generally you are deploying a single-purpose function that can scale independently of all of your other functions. When you deploy a Serverless container you’re generally deploying an entire application or Microservice. All of the functionality in that application or Microservice is going to be deployed into a single container, so in order to scale it you have to spin up more instances of that container. That means the whole thing scales as a single unit. If one chunk of your application is getting hit a ton, you’ll have to scale the whole thing to increase the amount of traffic you can serve.
Disadvantages of Serverless Functions
Lack of control – Someone is managing the servers your code is running on. Your code is running in an operating system, just not one you have any control over.
Proprietary – There aren’t any real standards around Serverless functions. Because of this you are usually writing your Serverless applications using a particular provider’s tooling and interfaces. Using a tool such as AWS step functions makes for a strong vendor tie-in, because orchestrating across Serverless functions is not standard at all right now. This can pull you deeper into a particular vendor’s ecosystem and make it harder to switch.
Rewrite – Taking an existing application and making it work within a Serverless function is generally not a possibility. You almost always have to write your application from scratch to take advantage of Serverless functions.
Traceability – Serverless functions have the same challenges as Microservices, but taken to an extreme. Tracing a single request across your system could involve dozens of Serverless functions. You need to make sure you’re leveraging tools like AWS X-ray, Google Cloud Trace, or Distributed Tracing in Azure.
Debugging/Testing – You can run a cloud function fairly easily on your local machine using tools like Serverless, Google Function Framework, or AWS SAM, but getting realistic invocations can be a challenge because cloud functions often integrate with cloud ecosystems in automated and proprietary ways. Also, services such as AWS step functions, which introduce an orchestration layer between lambdas, can make it even harder to debug what is happening in a live environment.
Deployment – Deployment of Serverless functions can be a challenge, but mostly because they provide tools (like an IDE) that encourage bad behaviors. Using the Serverless framework can make your deployments automated and manageable, but you need to be sure you take the effort to set it up and keep it organized, otherwise versioning and maintaining dozens, or hundreds, of functions will become a real pain.
Scaling Serverless Functions
Scaling Serverless functions requires a bit of extra attention here because people often think that tools like AWS Lambda or GCP Cloud Functions are a panacea for scalability. They assume that you can just push up your cloud function and get virtually instant scalability. But this is far from the truth. These Serverless function services make scaling incredibly easy, but there are limitations to the platforms that affect how fast and how high your functions can scale.
As an example, AWS Lambda has an initial per-region limit of 1000 concurrent function invocations (this is across all functions in the region). This limit is in place as a safety limit to prevent accidental resource usage and can be increased by contacting AWS support.
Based on that you might think you can just call up AWS support and request an increase to 20,000 concurrent invocations, and then you can push a bunch of requests to your Lambda function and have it rapidly scale up to that level to meet the demands of your service. Unfortunately, this is not the case.
Even after getting AWS support to increase your limit to 20,000 concurrent invocations, AWS Lambda will still limit you to 500 additional concurrent invocations per minute, meaning that it will take nearly 40 minutes to scale up to 20,000 concurrent invocations if you’re starting from zero traffic. In the meantime, all of the requests hitting your service that can’t be routed to an active function will receive 429 errors.
If you know that your traffic will need to burst more than this, you can purchase what Amazon calls “provisioned concurrency.” This will keep a certain number of Lambda functions warm and ready to go, but then you’ll be giving up some of the benefits of Serverless functions because you’re paying to keep them running all of the time. But, in some cases, this is worth the tradeoff.
There’s also the concern that a single function will eat up all the concurrency available for a particular region. You could configure the “reserved concurrency” for specific functions to ensure that their concurrency can’t be completely consumed by other functions. But let’s say you have a total concurrency of 5000 and you set the reserved concurrency of a function to 1000, then you’ll only be left with 4000 concurrency for the rest of your functions in that region.
While many of these settings are necessary to provide an environment that is both safe and usable, it can provide a lot of surprises for folks new to working with Serverless functions.
Vendor Lock-In
Almost all cloud platforms take every opportunity to lock you in, and Serverless is no exception to that. However, Vendor Lock-In is more of a concern with Serverless functions than it is with Serverless containers. The ways in which functions are invoked, deployed, orchestrated, and allocated are all dependent on the cloud provider you’re using.
There are projects like Knative that are making progress in creating a standard environment that companies can use to deploy Serverless workloads, but, in general, you have to deploy and manage the platform itself to get the benefits. This can quash many of the upsides to running your code in a Serverless manner. The goal was to avoid running infrastructure, right? I should mention that you can get native support for Knative with Google Cloud Run and with some effort you can run Knative on AWS Fargate.
What Do You Have Against Serverless Functions?
It might sound like we don’t like Serverless functions, but that isn’t true at all. We just think their uses are more limited than Serverless containers. There are certain use cases when Serverless functions are the perfect solution. Surprisingly, it’s often when you need a strong integration with the underlying cloud platform. Say you want to upload an image to S3, and have it automatically trigger a cloud function that processes it in some way; or you have logs coming off a logging service like Cloudwatch and you want to have a piece of code to easily analyze the log stream. That’s when Serverless functions truly show their worth. They also work well in places where you have a handful of hot endpoints that you want to scale differently than the rest of your application.
As you can tell, in most cases we are still recommending Serverless containers. But you won’t see us leaping for joy because Serverless containers don’t provide the true holy grail of Serverless computing. What is the holy grail of Serverless computing? I’m so glad you asked.
The Holy Grail of Serverless Computing
The holy grail of Serverless computing is true utility computing. To have all of my resources available when I need them, as I need them. To be able to upload a chunk of code (whether that is a single function or a whole application) along with a bit of metadata and have it run in a way that allows it to infinitely scale (with some safety limits). To not have to think at all about how much memory, storage, or compute it needs, it just figures that out automatically. Serverless functions are actually closer to this than Serverless containers, but for the reasons noted above, they still miss the mark.
Serverless, All Grown Up
Please don’t interpret this post as saying that I don’t think Serverless functions or containers are ready for real-world adoption. For most organizations, running servers should be as important to them as generating their own power (and some large orgs need to do both!). With Serverless computing, your code is still running on a server somewhere, just not a server you have to care about. And that really should be the long-term goal for most organizations, to be able to just push a chunk of code into a service and have it run. Serverless computing isn’t quite able to achieve the dream of “push code up and forget about it,” but we’re getting close.
Serverless computing is here, and here to stay. We’ll continue to see Serverless services getting closer and closer to the ideal described here. But while Serverless has definitely grown up, we still have a ways to go. To truly reach the ideal of Serverless computing we need to significantly rethink current computing and security models. While the challenge is huge, the payoffs are even bigger, so we’ll probably get there more quickly than we think.
from Simple Thread https://www.simplethread.com/serverless-im-a-big-kid-now/