
https://medium.com/swlh/is-vr-actually-going-to-change-anything-2225c979d97c#.l1tg7ai9e
from Designer News Feed https://www.designernews.co/stories/74549-heres-why-youre-overlooking-how-much-vr-actually-matters
https://medium.com/swlh/is-vr-actually-going-to-change-anything-2225c979d97c#.l1tg7ai9e
from Designer News Feed https://www.designernews.co/stories/74549-heres-why-youre-overlooking-how-much-vr-actually-matters
Optimization is nothing new. It can come in many forms but simply put, it’s the process needed to satisfy the growing demands of today’s tech-savvy digital users. Having optimized digital products can be the difference between happy, loyal brand advocates and unhappy users who don’t come back.
True optimization means building an effortless experience for your users. Whether it’s a website, app or email, your users expect every click, scroll or swipe to take them where they want to go, in a way that feels effortless and intuitive.
Today’s companies know they need be optimizing their digital channels to stay ahead, but how exactly do they do it? Where do they start? And which approach is best?
Some will tell you that there’s no better method than hard, quantitative data from analytics tools, while others will argue that rich, qualitative insights from user feedback is the way to go.
Well, the most effective way to get the information you need to optimize your digital channels is actually a combination of the two. Analytics and quantitative data tells you what is happening, qualitative user insights tell you why.
The first step in becoming data driven in your approach to UX and conversion rate optimization is to use direct data to determine where your users are getting stuck. By direct data we mean sources like web analytics. This is the logical first step to initiate and drive the ideation process and is a great way of improving your understanding of where to direct your optimization efforts.
This will give you the information you need to start hypothesising what could be impacting the user experience but what next? Do you simply dive in and start running tests on particular page elements? Well, you could, but it might end up costing you time and resources without knowing the exact reason for the friction. To get a better understanding of how visitors are moving around on your site and to inform your hypothesis, you must pair quantitative with qualitative data.
A/B testing is the go-to optimization process for most companies when they know they have an improvement to make on their website. For example, from analytics, you see a low conversion rate on a sign up page and assume that it’s a particular element on the page that’s causing the problem.

Using an advanced A/B testing tool like Optimizely allows you to try out different variations of CTAs, images or copy etc. in order to improve the overall success of the page. It works by showing users different versions of the page randomly to users to determine which is more successful. The original is usually the control in the test with the altered version being the variation.
By directly comparing the two versions, you can effectively determine what’s impacting the success rate. This is a great way to identify problem areas and can help to inform future design and UX decisions, but how do you know the things you’ve chosen to test are the right ones? Or once you’ve identified several elements to test, how do you prioritise which to test first?
This is where qualitative data comes in.
Using a method of collecting qualitative user insights, like Usabilla, can help save you time by pointing to the area that needs to be tested. It substantiates your test criteria and validates the need for the test in the first place; it can actually direct you to what needs to be tested. This effectively removes the element of ‘shooting in the dark’ and tells you what you need to test.
If you’ve seen from analytics that you have a low sign-up rate, ask your users directly what’s stopping them from converting. Then, you can move that element to the front of the line to run an A/B test on. The great thing about this kind of feedback is that it might point to something you’d overlooked. For example, you could assume that it’s something simple like the colour or placement of a CTA that’s stopping users from converting when really, it’s something like a lack of transparent pricing information.
User feedback validates and sometimes trumps internal assumptions. Analytics can only get you so far, collecting user feedback is the only way to truly understand why your users do the things they do.
So you’ve decided what to test based on user feedback and rolled out an A/B test that gives you a clear winner. End of story, right? Well, user feedback can add a final layer to the optimization process by validating the end result. Ask your users directly what they think of the change you’ve made or simply give them a chance to express whether or not they’re happy with that particular page.

Rather than just blindly following the numbers, you’ll be able to read the feedback of a successful variation to understand why it performed better. This allows for informed iterations and faster optimization. As you can see in the image above, Usabilla feedback items will pull any associated A/B experiment you’re running so you can see the direct correlation between the feedback and the test. With Usabilla, you can also filter by experiment, so you can gauge the overall sentiment of that test.
Combining A/B testing with Usabilla also means you can target slide-out surveys to trigger on specific test variations. For example, if you’re A/B testing a big change on your homepage, survey the users who see the variation and ask what they think of it. This will reduce risk for changes moving forward.
Bringing user feedback into the A/B testing process will save time and resources as you will know what to test, know what to prioritise and know if the end result is the right one.
This iterative process of optimization will save you time, money and resources. Having the channel to your users always open through user feedback software like Usabilla will mean you always know what you need to optimize for a better user experience, and you’ll have no shortage of things to populate your A/B tests with.
User Feedback and A/B testing are great processes on their own and can give you tangible, actionable results. However, if you want to be truly data-driven (and user-centric) in your approach to optimization, you need to combine quantitative and qualitative sources to deliver the seamless digital experience your users are looking for.

The post Why User Feedback and A/B Testing Need Each Other appeared first on Usabilla Blog.
![]()
from Usabilla Blog http://blog.usabilla.com/user-feedback-ab-testing-need/
UX research has borrowed a lot from the fields of psychology, sociology, and anthropology. From analysing behaviour to documenting how people perform certain tasks, you clearly see these fields bleeding into UX. In fact, some even say that those who have studied anthropology are already well trained for being a UXer.
Observational research is a powerful research technique – one of the many popular qualitative methods used in the industry. The information gleaned from observational research helps you discover what your users think and experience, and how you can fix problems they face.
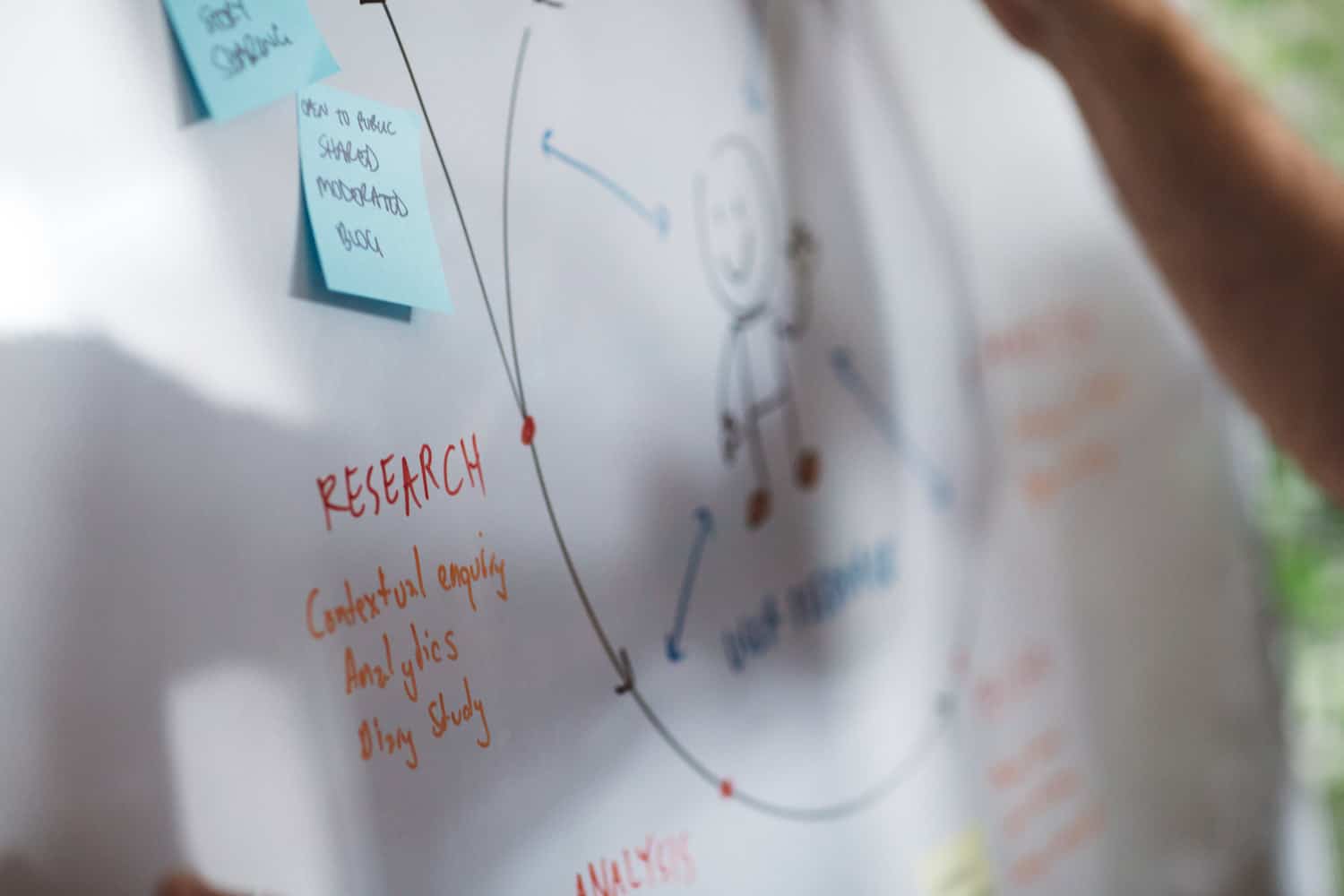
Qualitative research delves deep into the thoughts, feelings, and behaviours of your participants.
Research observations fall under the umbrella of qualitative research, so let’s dive into definitions.
Qualitative research is exploratory, and it delves deep into the thoughts, feelings, and behaviours of your participants. It gives us an opportunity to identify problems and uncover answers for questions we didn’t know we had by tapping into the minds of our research participants.
Qualitative research takes a number of different forms, such as interviews, focus groups, and usability testing, and many of these methods involve writing research observations. As you can see by these types of research methods, each one provides a forum for people to discuss a topic in depth to provide quality insights.
Some of the many benefits of using qualitative research are:
Researchers Catherine Marshall and Gretchen Rossman defined observations in their book “Designing Qualitative Research” as “the systematic description of events, behaviours, and artefacts in the social setting chosen for study”.
In the case of UX research, these are things that happen when you’re watching people perform certain tasks or when you ask them interview questions.
For example, when conducting a usability test, a research observation would be something the researcher sees or hears — something that provides insight into what the research participants are doing, thinking and feeling. This could be that it took 10 minutes for the participant to find the login screen of the website you’re testing, and the participant expressed frustration.
There are various kinds of observations you can note down in your research. A paper from Michael Angrosino, citing research from Oswald Werner and Mark Schoepfle, identifies three different kinds of observational research processes.
Interestingly, authors Robert M. Emerson, Rachel I. Fretz and Linda L. Shaw penned similar thoughts in their book “Writing Ethnographic Fieldnotes”. According to the authors, writing field notes (which are research observations) “is not a matter of passively copying down ‘facts’ about ‘what happened’. Rather, these descriptive accounts select and emphasise different features and actions while ignoring and marginalising others.”

Descriptive, focused or selective. What types of observations are you recording?
Research observations, once collected, allow you to drill down deeper into the behaviours of your users. Observational research can also help you to verify or explain other kinds of research you have collected or are collecting, such as a Treejack study or other methods of remote user testing. Remember, what your users may say in a study might not be what they’re actually thinking or feeling. Observational research will help you get over that hurdle.
When it comes time for you to begin your research and note down your observations, keep these tips front of mind.
You might be about to embark on a qualitative research project for the first time, or a seasoned veteran. Either way, I hope you’ll be able to record better observations using Optimal Workshop’s qualitative research tool Reframer.
Whether you’re researching alone or as part of a team, just remember that preparation, detail, and organisation are key to helping you get great research results. Happy testing!
Interviewing users and stakeholders is a key skill for UXers to develop. Cameron shares how to conduct an effective interview, how to hone your techniques, and offers some techniques to avoid.
It’s exciting to see more professionals wanting to research customers to make their services and products fit better. But there’s a lot of confusion about how to choose the most appropriate research methods to suit…
A content audit isn’t something you’re going to want to tackle. But you can’t undertake a redesign of a content-heavy site without it. Donna Spencer shows you how to conduct a Content Audit in this…
from UX Mastery http://uxmastery.com/how-to-write-effective-research-observations/
Messaging looks set to disrupt the computing landscape but not for any of the reasons you might expect. Chat’s threaded UI, where all communication and actions are placed in a clear context of who, what and why, is the killer feature that’s been around forever and yet everyone is overlooking.
Mobile is the future of global computing, and according to Mary Meeker and Co., the killer app for mobile continues to be messaging (a.k.a. Conversational UI among pedantic product designers like me.) In 2015, messengers surpassed social networks in both number of users and rate of growth. And even though the mobile-OS-plus-app thing is still strong, research consistently shows that users interact with just 27 unique apps per month, and actually care about far fewer over time.
To find fresh, lightweight ways to reach users, forward-thinking businesses are turning to chat (and of course Intercom helps companies do this!). Chatbots have been anointed by industry leaders like Zuckerberg and Satya as the way to launch and scale this effort, and it’s all really real, according to Gartner (via Techcrunch). They predict by 2018 a full 30 percent of our technology interactions will be mediated through conversations with bots.
New threaded experiences will be enabled, supplanting single-purpose apps, sites, and services – even on the desktop
But chat UI will not blow up just because of bots or other emerging UI bits and pieces. As messengers evolve into full blown computing platforms, new threaded experiences will be enabled, supplanting single-purpose apps, sites, and services—even on the desktop. It’s the threaded organisation of interactions into useful contexts centered around people, businesses and task threads that could change the world.
On top of the twin forces of app-ennui and bot-ification, there’s a third force at work that’s gaining momentum—and it’s the one that could really transform chat into a general purpose platform. It’s the tighter and tighter integration of third party services, notably payments, into threads. The Chinese chat leader, WeChat, has a general purpose wallet and interpersonal micro-transfer platform that’s huge in the Chinese market. Reuters reported that in 2016, WeChat’s estimated transaction volume on personal transfers alone (excluding wallet transactions like movies, meals and wheels) will be almost double PayPal’s $280bn 2015 volume, and all without the aid of single bot!
While it’s true that uniquely Chinese factors steroid-ed this growth (a distrust for online card payments, a trust of mobile operators, and a giant population) western messengers such as Snapchat and Facebook M also have integrated payments, and rumors abound that Apple Messenger and Telegram will soon follow suit. Messenger payments are definitely coming and where payments go, so goes general commerce.
If you zoom out a bit and look at the broad messenger picture, then, what you see is a class of service that’s:
As a total package, that’s a pretty compelling mix, and much more than browser apps can bring to the table.

What will drive all of this is not just the arrival of bots, but the fact that threads are simply a better paradigm for organising your digital life than anything cobbled together from email, web pages, apps and the odd SMS. They’re great at keeping context (simply scroll up if you forget what you’re talking about), so they can help people shift quickly from one stream of communication to another without the soul destroying digging around we are forced to do today. And they’re perfect for organising everything around what’s actually important: the thing you’re trying to do or the person with whom you want to communicate. Let’s look at a couple of examples of how this could work.
It’s lunchtime, I’m hungry, and in my messenger of choice, I search for McDonald’s. In my (future) address book’s location-aware (and smarter) business directory tab, I pick McDonald’s, and start a chat with the restaurant by texting or speaking “Hey,” poking them with my poke button, or ringing a branded minterface McDonald’s hamburger-shaped doorbell. This conversation starter creates implied consent, so I’m happy for McDonald’s to determine which store I’m near, take a good long look at my AI-enriched profile to see how I like to pay, and whether or not I want to get a calorie total of the meal or not before paying (ha, ha).
McDonald’s can easily see my past orders, organised into the McDonald’s thread, and using this information, deliver a custom soft-keyboard picture menu sporting its latest healthy snack and today’s elderflower cordial shake.

As I select items, my order is assembled into a tidy chat bubble that I can review, edit and add new things to, using standard chat interface interactions until I’m happy. Then I just hit “send” to place the order. The order is received, paid for with a minterface payment button that appears inline, and it’s ready for pickup by the time I arrive.
Let’s say I want to buy a new jacket, and from past web browsing or brick and mortar shopping experiences, I think UNIQLO’s the brand for me. I search for UNIQLO in my business directory, and text them to say “I want a lightweight jacket for delivery to my home, please.” I’ve given implied consent to share AI-enriched profile information with UNIQLO, so they get information about my size, gender, and my delivery area.

In return for all of this helpful information, UNIQLO sends me a hand-crafted (no, not really) message with a URL payload that’s unfurled nicely in my messenger. It looks good, full of exactly what I’m looking for, along with a few surprising extras to entice me. I tap the message and a page appears filled with jackets for my gender, in my size, and available for delivery in my area.
When I’m ready to order that snappy new windbreaker, UNIQLO requests payment from my messenger, which in turn requests payment from my authorised payment provider, adding a payment button to the thread. I tap it (of course I do!) and I get a nice thank you from UNIQLO. The next thing I know, my bank drops in a confirmation message into the same thread, followed by DHL who drops in the related tracking details. Et voila, at least 10 screens, annoying bank security freak-outs and three or four different service hops have been made redundant. But most importantly, it’s all organised in the way I think about things: buying my jacket. The old way would be the store, bank, and delivery services all sending me disconnected, disjointed bits of information that I have to weave back together into something meaningful.
That’s a really important shift. The information isn’t scattered in several different unrelated places that might include SMS, email, or potentially an app or two on your phone—it’s all in context with what the user wants to accomplish. And that’s huge. Going the other direction starting on the web is even simpler. I give the UNIQLO website a phone number or messenger ID, and then finalise my transaction in a similarly nicely organised, sensible thread.
The great thing about organising a purchase or any compound interaction this way is that all of the context and information is preserved in the same thread. So if there’s ever a problem or question, the customer service person, account manager, bot or other helper on the other side of the thread will have everything needed to help. No more order numbers or account verification required.
By adding richer context to every interaction the web gets faster and more effective for everyone
Think about how much time and effort you’ve had to waste getting reps up to speed, only to have it to do it again and then again because of a call transfer or an unavoidable interruption. These types of redundant, wasteful interactions appear at every level of business interaction, whether it’s B2C or B2B. By adding richer context to every interaction (and memory) the web gets faster and more effective for everyone.
This is the key about conversational UI: it’s not really about the UI or bots. It’s the fact that messengers uniquely combine rich context, security, and natural language tools organised meaningfully into threads that better represent what we’re doing and trying to accomplish. The messenger doesn’t replace the web browser or apps, instead it can orchestrate a more relevant and pain-free experience. It doesn’t replace the bank, but it could replace random, potentially insecure payment experiences (just like PayPal, Apple Pay, and others are trying to do today). And it doesn’t replace tracking systems, it simply puts the tracking information where it should go, helping you see the full flow of the task you are trying to accomplish.
Unlike browsers or devices, only the messenger is perfectly poised to bring truly new, personal and relevant experiences to life. These next few years will tell us whether this potential can be realised.
The post The killer feature of messaging no one’s talking about appeared first on Inside Intercom.
from The Intercom Blog https://blog.intercom.com/killer-feature-messaging-no-ones-talking/

As mobile app technology evolves, it seems logical that our mobile analytics capabilities should evolve proportionally. Yet for the most part, any evolution in the mobile analytics realm is happening at a much more glacial pace. Now that’s not to discount improvements in areas such as data visualisation, product integrations, and real-time capabilities, which have helped product managers gather and dissect their data better than ever before. These advancements are valuable, but do not supersede the underlying disproportion between mobile app technology and our capability to analyse mobile app usage that exists today.
Interestingly, this disparity is due to the data itself – you’ve all heard the quote “the devil is in the data”. But what if I was to tell you that the quantitative data you have been gathering is actually functioning more like a prologue to an important story than the story itself – in this case, your users’ story. This quantitative data gives you a powerful introduction into what users are doing in your mobile app, but it doesn’t allow you to explore their specific experiences. Mobile product managers need data that provides them with the ability to actually see and understand specific user behaviour instead of having to define it by aggregate, numerical data.
However, a few mobile analytics companies, including Appsee, have recognised this need and brought a new type of analytics to market – qualitative analytics.
And as you probably guessed, once you combine qualitative analytics with your quantitative data, you are able to obtain that epic, complete story on your mobile users. But how exactly?
In order to understand the potency of this union, we first need to understand why relying solely on analytics that provides quantitative data (traditional analytics) simply does not cut it.
Let’s just review the definition of quantitative for a moment. Merriam Webster notes the definition as follows:
1: of, relating to, or expressible in terms of quantity
2: of, relating to, or involving the measurement of quantity or amount
3: based on quantity; specifically of classical verse: based on temporal quantity or duration of sounds
Numbers, numbers, numbers – that is the core of the definition. So when it comes to quantitative analytics, basically all of the data and information it collects can be measured with numbers.
This is no bad thing, in fact it’s extremely important. Quantitative data can help you gather insights on overall user actions and usage trends, such as the length of the average user session or how many users completed a certain conversion funnel. But these numbers don’t answer the pivotal question of “why?”. Quantitative analytics can only answer your number based inquiries. Numbers have an extremely important story to tell, but how do you figure out and communicate that story?
Enter qualitative analytics.
While quantitative analytics focuses on aspects of your app that can be measured by numbers, qualitative analytics zones in on the one essential element of your mobile app that cannot be delineated by numbers. That element is the user experience; your user’s unique story within your app.
At the moment, how do you know whether your users are frustrated with a certain unresponsive button or confused by a particular feature? To put it simply, no number on a dashboard can effectively describe those specific in-app experiences. In order to fully understand and assess your users’ stories, you need data that enables you to see what your users are experiencing and how they behave. This is the essence of qualitative analytics.
With features such as user session recordings and touch heatmaps, qualitative analytics allows you to actually step into the shoes of your real users (not beta testers) and examine how they truly interact with your app. This is the best way to analyse a KPI as subjective and nuanced as user experience.
Yet the value of qualitative analytics is not limited to inspecting user experience. It also serves as an extremely powerful compliment to your quantitative data.
Quantitative analytics allows you to identify on a numerical basis important trends, issues, and actions within your mobile app. Then, qualitative analytics (such as unique user session recordings) augments this data by supplying the crucial “whys” behind those numbers.
Let’s look at some compelling use cases of this power couple in action.
Your quantitative analytics tells you that your daily app crash rate has increased by 50%. This is very important, but now you need to understand why this is happening. To obtain valuable visual context behind your crashes, you turn to your qualitative analytics and watch session recordings of crashed sessions from that specific day. This allows you to accurately reproduce a crash and discern the sequence of user actions that led to a crash.

You have an ecommerce app with a conversion funnel in place for purchase completion. Your quantitative data tells you that over a seven-day period, 74.4% of your users that visited the “My Cart” screen, dropped out of the funnel and did not trigger the event “Purchase Complete”. These stats alert you to the fact that your users might be encountering a potential issue or multiple issues within the “My Cart” screen. What are the issues exactly? By drilling down to specific session recordings of users that dropped out of the funnel, you can see exactly what might have caused friction within their experience.

In a nutshell, this combination of quantitative data and qualitative information allows you to streamline the process of turning data into information, and information into insights – actionable insights. No more scenarios of drowning in copious amounts of quantitative data and guesswork.
To top it off, by using qualitative analytics to distill quantitative data, you can save valuable time and resources – which product managers often are low on. At the end of the day, this quantitative and qualitative union should empower you to separate the “wheat from the chaff” within your data and make key decisions regarding your product with more confidence. We can’t wait to hear what insights you obtain.
The post The matrimony of qualitative and quantitative analytics appeared first on MindTheProduct.
from MindTheProduct http://www.mindtheproduct.com/2016/09/the-matrimony-of-qualitative-and-quantitative-analytics/
We have now tracked the global average cart abandonment rate for 7 years. Sadly, little has improved in those years, and the average cart abandonment rate currently sits at 68.8%. Stop for a second to consider that: after having gone through the trouble of finding a product and adding it to their cart, a whopping 2 out of 3 users choose to abandon their purchase.

Today we’re therefore launching a new and completely revised version of our Checkout Usability study. This new usability study is the result of 7 years worth of e-commerce checkout research – testing live production sites of major brands with real end-users – to figure out why those 68.8% of shopping carts are abandoned, and what e-commerce sites can do to improve this abysmal statistic.
The findings in the study are based on qualitative usability testing with 272 test subject / site sessions following the “Think Aloud” protocol (1:1 moderated testing), a large-scale eye-tracking study of checkout flows, two rounds of checkout benchmarking more than 850 checkout steps, and four quantitative studies with a total of 6,052 participants.
Despite testing leading e-commerce sites, the subjects encountered 2,700+ instances of checkout usability issues. It’s these hiccups that, along with the quantitative data, have been analyzed and distilled into the 134 checkout usability guidelines that constitute the backbone of this study.
Now in all fairness, a large portion of cart abandonments are simply a natural consequence of how users browse e-commerce sites – it is users doing window shopping, price comparison, saving items for later, exploring gift options, etc. These are largely unavoidable cart abandonments.
In fact, our latest quantitative study of reasons for cart abandonment finds that 58.6% of US online shoppers have abandoned a cart within the last 3 months because “I was just browsing / not ready to buy”. Naturally, this segment of users is almost impossible to reduce through a better checkout design – most of these will abandon even before they initiate the checkout flow. However, if we segment out this “just browsing” segment, and instead look at the remaining reasons for abandonments we get the following distribution:

Unlike the “just browsing” segment, a lot of these issues can be resolved. In fact, many of them can be fixed purely through design changes. Let’s take a look at just one example from the new checkout study:
In other words, 1 out of 4 shoppers have abandoned a cart in the last quarter due to a “too long / complicated checkout process”, yet for most checkouts it’s possible to make a 20-60% reduction in the default number of form elements shown to users during checkout. And again, this is just one of many examples of causes for checkout abandonments.
So while a 0% cart abandonment rate might be unattainable, we can certainly do better than 68.8%. But how much better? Well, our research suggests the average e-commerce site can improve its conversion rate by 35% solely through design improvements to the checkout process.
If we focus exclusively on the checkout usability issues which we – during multiple rounds of large-scale checkout usability testing – have documented can be fixed by checkout design improvements alone, then the average large-sized e-commerce site can gain a 35.26% increase in conversion rate. And that is despite this figure being based on the checkout flows of leading e-commerce sites, such as Walmart, Amazon, Wayfair, Crate & Barrel, ASOS, etc.
Now, achieving such gains won’t come easy. But even when we audit leading Fortune 500 companies, who’ve already run a couple of checkout optimization projects, we find that major gains are still possible. And the potential is big: our benchmark of 50 leading e-commerce sites reveal that the checkout flows of large e-commerce sites on average have 39 potential areas for improvements.
Yet don’t be discouraged if you don’t have the resources of a Fortune 500 site – the vast majority of the checkout changes in this report are related to page layout, addition of simple form features, and improving microcopy, and thus don’t require advanced technical implementation or deep pockets. Indeed, we find small online retailers just as capable of crafting great checkout experiences, if they stay nimble and focused.

6,000+ manually reviewed checkout elements summarized across 18 themes, with each dot in the scatterplot representing a major e-commerce sites. For an interactive version of this graph, head to the benchmark page.
During the past 7 years of testing e-commerce sites we’ve consistently found that the design and flow of the checkout process is frequently the sole cause for abandonments. Either because users grow so infuriated with the site that they leave in anger, or because they get stuck on how to complete one or more fields and end up having no other option than to leave.
Over the next couple of months we’ll dive deeper into our findings from the usability research study in a series of articles on checkout usability. In the meantime consider taking a look at the just-released checkout UX performance and ranking of 50 major e-commerce sites. In the free and public part of the benchmark database you can also browse the 380 manually reviewed checkout steps, by “step type” for checkout inspiration.
As with all of our research studies, the checkout usability study released today includes an exhaustive usability report along with an integrated benchmark database. The report is 718 pages long, and outlines 134 design guidelines on how to improve checkout usability (and thus lower cart abandonments). The benchmark database is based on more than 6,000 manually reviewed checkout elements and contains 50 case studies of major e-commerce sites and 380 annotated checkout steps.
You can learn more about getting full access to the study at: baymard.com/checkout-usability

![]()
from Baymard Institute http://tracking.feedpress.it/link/9825/4462568
A data scientist is, essentially, a statistician who can code. That might not sound like a big deal, but in reality, companies are chomping at the bit to hire data scientists–so much so that Glassdoor just named it the hottest job of 2016. The power data scientists wield to generate more revenue for growing companies is truly awesome. So what exactly does a data scientist do all day, and why is the field growing so rapidly?
“Data science is sort of a mingling of statistics, programming and machine learning,” said Galvanize Lead Instructor in Data Science Giovanna Thron. “It’s not just knowing how to apply statistics on a data set, it’s also being able to write the code to do anything … to put their ideas into action.”
Thron attributes the swell in demand for data scientists to a few key factors. But first, it’s important to understand what a data scientist does. Here’s an example:
If an online retailer like Amazon has a million users perusing its site, those million individuals’ generate information, a record, essentially, of every click, query, and purchase. From those millions upon millions of data points, data scientists can glean an understanding of the site users’ interests and product preferences. They can then make sense of all of that information, using programming languages like Python or SQL, to provide the company insights about what products, marketing or site design might work well in the future. For example, they can get a sense of a customer through their interactions with the site and expertly target products at the customers they’re most likely to purchase.
That’s extremely valuable.
Say a data scientist is able to increase customer purchases by just one percent with the recommendations she has programmed–the revenue she’ll bring in will more than cover her (ample) salary. With the insights data scientists provide, online retailers today (a field growing by about 16 percent year over year in the last quarter, a pace about seven times faster than all retail commerce growth, according to the U.S. Dept. of Commerce), are doing a better job of serving their customers than ever before.
Job growth in this field is far outpacing the national average, and here’s why the field is growing right now:
First, there are many companies today that are growing large enough to have a wealth of information–the critical mass of users one needs to have to generate enough data points–that good predictions can be made from it.
Secondly, hard drive space, the machinery used to store all of that information, is extremely cheap (it wasn’t always that way), so storing mountains of information is economical.
Next, computational power to plow through that data is stronger than it’s ever been, and getting better all the time. That means clever data scientists have powerful tools at their disposal to create models (using programming languages) that can extrapolate sound findings from unfathomable amounts of data. It’s not your grandma’s statistical modeling.
In doing so, and this is the fourth and most important reason for the growth of data science, data scientists can use their awesome powers to increase revenue in a way old-fashioned number-crunching and business intuition never could.
While online retail is a huge area of growth in the world of data science, it’s by no means the only one. For example, as the world shifts more wholeheartedly to dealing in plastic and other transactions over cash, data scientists are the first line of defense against fraud. Data scientists create models, using their statistics-savvy and programming languages like Python or R, to analyze our past purchasing behaviors and determine the likelihood of whether a given transaction is fraudulent or legitimate. In doing so, they’re able to save billions (if not trillions) every year in prevented fraud and protect you from having your money stolen.
Data scientists are also crucial to insurance companies being able to build ever-more efficient and precise cost structures by analyzing risks. They also generate revenue for companies like Twitter, Facebook, and Instagram, who sell valuable targeted advertising space by scraping sites for user data and making sense of it to target ads to the most relevant users.
Whatever the field, companies can dramatically improve business with that kind of precise insight. No wonder employers are clamoring for data scientists faster than universities can turn them out.
The post Why You Need a Data Scientist on Your Team appeared first on Galvanize.
from Galvanize http://www.galvanize.com/blog/why-you-need-a-data-scientist-on-your-team/
At UserTesting, we believe customer insights should be part of every design and development process. So we’re excited to announce our partnership with InVision—to connect designers and developers with their users early in the development cycle!
The traditional methods for …
The post UserTesting partners with InVision to bring fast user feedback to leading design collaboration platform appeared first on UserTesting Blog.
from UserTesting Blog https://www.usertesting.com/blog/2016/09/20/invision-prototype-testing-announcement/

As a star is devoured by a supermassive black hole, it emits a bright stream of material called a tidal disruption flare.
Credit: NASA/JPL-Caltech
A doomed star falling into a black hole may produce a flare of light that “echoes” through nearby dust clouds, according to two new studies.
Monster black holes can be millions of times more massive than the sun. If a star happens to wander too close, the black hole’s extreme gravitational forces can tear the star into shreds, in an event called “stellar tidal disruption.”
This kind of stellar destruction may also spit out a bright flare of energy in the form of ultraviolet and X-ray light. The two new studies examine how surrounding dust absorbs and re-emits the light from those flares, like a cosmic echo, according to a statement from NASA’s Jet Propulsion Laboratory (JPL). [Millions of Black Holes Seen by WISE Telescope (Photos)]
“This is the first time we have clearly seen the infrared-light echoes from multiple tidal disruption events,” Sjoert van Velzen, a postdoctoral fellow at Johns Hopkins University and lead author of one study, said in the statement.
The new studies use data from NASA’s Wide-field Infrared Survey Explorer (WISE). The NASA study led by van Velzen used these “echoes” to identify three black holes in the act of devouring stars. The second study, led by Ning Jiang, a postdoctoral researcher at the University of Science and Technology of China, identified a potential fourth light echo.
Flares emitted from stellar tidal disruptions are extremely energetic and “destroy any dust” that is within the immediate neighborhood, according to NASA. However, a patchy, spherical web of dust that resides a few trillion miles (half a light-year) from the black hole can survive the flare and absorb light released from the star being gobbled up.
“The black hole has destroyed everything between itself and this dust shell,” van Velzen said in the statement. “It’s as though the black hole has cleaned its room by throwing flames.”
The absorbed light heats the more distant dust, which in turn gives off infrared radiation that the WISE instrument can measure. These emissions can be detected for up to a year after the flare is at its brightest, the statement said. Scientists are able to characterize and locate the dust by measuring the delay between the original light flare and the subsequent echoes, according to the NASA study, which will be published in the Astrophysical Journal.
“Our study confirms that the dust is there, and that we can use it to determine how much energy was generated in the destruction of the star,” Varoujan Gorjian, an astronomer at JPL and co-author of the paper led by van Velzen, said in the statement.
Follow Samantha Mathewson @Sam_Ashley13. Follow us @Spacedotcom, Facebook and Google+. Original article on Space.com.
from Space.com http://www.space.com/34123-black-holes-devour-stars-echoes-reveal.html

![]() Harriet Taylor / CNBC:
Harriet Taylor / CNBC:
Forrester: AI will eliminate 6 percent of jobs in customer service, trucking, taxi industries in five years — A Forrester Research report expects intelligent agent to displace about 6-percent of positions within the next five years. — Within five years robots and so-called intelligent agents …
from Techmeme http://www.techmeme.com/160914/p9#a160914p9