The categories of portal sites are exactly the visual analogy of libraries, hospitals, or the shelves of bookstores. Every single webpage was indexed under one or more appropriate categories, just like a book was put into one category of the library according to its topic.
Since information could be accessed only through the category, there is a big problem: if we don’t know how the specific info is categorized, we could not access the info.
It is just like this: you are sick, but you have no idea which department of a hospital you should go to, so you have to ask someone who knows that for help, and finds you the correct department to see the doctor.
Another problem: if there were some all-new information which seems not fit into current categories, it may not be accessed easily too. We have to fix the category first, and that costs.
Today you would say: Why not just search? Exactly, a search is the answer to solve the problems created by categories, but not at that time. The computer hardware was not good enough to index so large data from the fast-growing Internet, and computer science and software technology was yet to be so matured to provide great search experience.
And there came Google, a small company dedicated to search, who successfully solved the hardware and software problems, then be the most powerful tech giant on the Earth.
The 2000s: The Search Era
It was the superior technology brought by Google to push the first paradigm shift of the Internet, from the paradigm of a portal to a new one, the paradigm of search.
By putting some keywords in the search box, people could access the information on the Internet more directly, without categories in the middle. So the distance between information and human has been dramatically reduced to a whole new level. That’s a huge leap forward, a true paradigm shift.
The winners of the past, the portal sites, failed so fast under the new paradigm. Some were acquired by competitors, some were merely discontinued. Just like dinosaurs extinct overnight. Today we are so familiar with their tragic stories.
Lack of Personal Info
But again, did search brought information together with human perfectly? Not yet. There was still a discrepancy between information and each person. Search engines simply did not have enough information about you. They did not know your preference, so they could not give you answers that best satisfy your queries.
Say, you are hungry, looking for something delicious, so you type “cuisine” in a search engine, waiting for a good recommendation. There is a problem. The definition of cuisine is very personal, each individual has his/her preference on food, and search engines simply did not know about that. So in the beginning, all they can do is to give you a series of very generalized answers: any webpages containing the keyword cuisine or other info alike with a high ranking score.
The generalized answers won’t satisfy us, so we provide more keywords, narrowing down the search results, repeat and repeat until we got something right.
Lack of personal information is a big weakness of the search paradigm, so search engines have to develop other means to gather personal information for each user as much as they can, to make sure the best user experience served. That’s why Google keeps every search history for further analysis, and that’s why Google has so many subsidiaries other than search: maps, email, news, calendar, translation, even an open-source mobile operating system, and so on. Google just needs so much data about you, or it has to guess.
The rule is simple: Who gets more personal info could further reduce the distance between info and individual users, and provide better user experience, then be the winner of the next paradigm.
That is social networks.
Today: Age of the Social Networks
The social networks effectively reduced the distance between information and individuals to an unprecedented level, because they have way more personal info provided by users themselves. It knows us even much more than ourselves.
Take Facebook as an example. Every time we logged in Facebook and interact with the UI, we are virtually providing all info about us. Facebook carefully measures and monitors how we use it, looks at what we like or comment or share on specific posts, what we skip, where we are, who and what are in the photos we upload, and so on. The data they have are so abundant, first-hand, fresh, so they can pick up the most attractive contents (and ads) via their sophisticated algorithm, and continuously iterate to improve.
Another paradigm shift happened, driven by the powerful new technology of social networks, by further reducing the distance between information and human.
In this decade, social networks like Facebook, Instagram, Twitter, and YouTube are so successful, enable so many new forms of communication and economy, along with smartphones and ever fast wireless Internet access. Also, they created as much trouble, to name a few, privacy crisis, mis- and dis-information, and the huge threat to the integrity of democracy, both from democracy itself and the outside authoritative countries.
2020 is approaching. What will be the next paradigm? And what are the benefits and impacts it will bring?
To me, the only answer is artificial intelligence.
The Next Paradigm: Machine Learning/Artificial Intelligence
There is one fundamental difference between the paradigm of AI and the past paradigms: while old paradigms reduced the distance between info and human, the paradigm of AI will put info in the front, and put human back.
What do I mean? The past paradigms were to provide the best choices for us, while the AI paradigm chooses for us. Thus, the power of decision making will be in the hand of tech giants and their smart machines, not us.
Take autonomous vehicles as an example. The final stage of developing self-driving cars, the so-called level 5, could have no driver control interface at all. No steering wheel, no acceleration pedal, no brake pedal. You just sit into the vehicle, that’s all. The vehicle will automatically monitor the surroundings, communicate with other cars and traffic control system, then decides the best way to move at the moment.
In short, the car decides how to drive for you. You don’t have to drive, so you don’t decide.
In the coming years, we could expect more and more AI boom in different scenarios. Today most people could not even sense the existence of AI in their everyday life, just because current AI could only be useful in some very narrow or low-level vertical use cases, such as to win over the world champion of GO chess, or to recognize who is who from the images captured by cameras all over the streets, deployed by the surveillance authorities .
Not too long, there must be a very powerful horizontal way to integrate all these vertical AI services, to be a super killer application for every ordinary individual user.
The smart voice assistant could be the one killer app if they get smarter. Once they could deeply understand what we need by casual conversation, they could integrate multiple vertical AI/Non-AI services, and provide the best result directly to us. Human users no longer need to care about how the decision is made, just enjoy the result. Super easy, super convenient.
And the one who could bring this perfect voice assistant to users could be the next superpower among existing tech giants.
Why we exist?
When people no longer have to make decisions, when most of the decisions are made by smart machines much more quickly and correctly than humans, there must be huge impacts. We have seen the approaching crisis of unemployment by AI/non-AI on low-skills or highly repetitive jobs now, and we could expect more jobs with even higher skills or non-repetitive to be replaced by smart machines.
Besides the huge impacts on society as a whole, I think the most fundamental question under the new paradigm will be: why we human beings exist? What is our value, to oneself or ourselves?
We still have some years to find out our answers to the question.
from The Startup – Medium https://medium.com/swlh/paradigm-shifts-of-the-internet-from-portal-sites-search-engines-to-social-networks-whats-next-54f75abf1620?source=rss—-f5af2b715248—4
The scale and speed of adoption have been incredible, and Uber cites its unique business model and experience as the drivers.
So what are the most significant issues customers have with Uber? And how has Uber used science to fix them?
Uber customers’ biggest pain point — the wait
Imagine you’re out at 2 am on a winter night, waiting for your Uber while shivering on the side of a dark street in a new town. Or you’re late for an important meeting that you might just make if your Uber is on time.
In these high-pressure situations, your perception of time is warped. Every second takes a minute, every minute takes an hour.
Not only that, but people will use this warped wait time to judge their entire customer experience. Why? It’s all down to a psychological principle called the Peak-end Rule.
The science behind an unforgettable customer experience
The Peak-end Rule says that people judge an experience based on how they felt at its peak and its end, not the average of every moment of the experience. And that’s true whether the experience was good or bad.
For brands, this means customers will remember their whole experience based on only two moments — the best (or worst) part of their experience, and the end.
Wait times are critical to a good experience — here’s how Uber applies psychology to perfect their customer experience
Because wait times are the key to a great customer experience, Uber has spent countless hours addressing this pain point.
In their research, Uber discovered three key principles dealing with how people perceive wait times: Idleness Aversion, Operational Transparency, and the Goal Gradient Effect.
Recent studies into psychology, happiness, and customer experience have uncovered a principle called “Idleness Aversion”. It states that people are happier when they are busier, even if they’re forced to be busy.
How to apply Idleness Aversion
To keep people busy, give them information to engage with — animation, gamification, and visuals are ideal.
In the example from Uber below, they use an animation that keeps you entertained and informed while you wait for your ride.
“When customers are separated from the people and the processes that create value for them, they come away feeling like less effort went into the service.
They appreciate the service less and then the value the service less as well.”
— Ryan Buell, Harvard Business School
Operational Transparency is the deliberate inclusion of windows into your company’s operations, so customers can see the effort going into their experience.
To keep people informed, make key information available, and help them understand where this information came from.
In the example from Uber Pool below, they provide information on how arrival times are calculated. It provides customers transparency but doesn’t overwhelm a non-technical audience with too many details.
The Goal Gradient effect states that people are more motivated by how much is left to reach their target, rather than how far they have come.
And as people get closer to a reward, they speed up their behavior to get to their goal faster.
How to apply the Goal Gradient Effect
Think of the Goal Gradient Effect as a virtual finish line. The closer customers get to winning, the more encouraged they become.
You’ll often see the Goal Gradient Effect in UX elements like progress bars and profile completion — users are encouraged to complete a task by achieving objectives.
Uber applies this principle by illustrating what’s happening behind the scenes while customers are waiting. They explain each step in the process, making customers feel they are making continuous progress toward their goal.
There’s no doubt that a large part of Uber’s revenue comes from optimizing their experience using science.When an experiment was run with Uber Pool that applied Idleness Aversion, Operational Transparency, and the Goal Gradient Effect, the results were impressive:
“The Express POOL team tested these ideas in an A/B experiment and observed an 11 percent reduction in the post-request cancellation rate.”
If you want to apply these principles to your brand, a testing mentality is critical. You have to be willing to test the application of the same principle in hundreds of different ways before discovering the best solution.
This experimentation mentality comes from the top down at Uber. As founder Travis Kalanick says:
“I wake up in the morning with a list of problems, and I go solve them.”
from Sidebar https://sidebar.io/out?url=https%3A%2F%2Fuxdesign.cc%2Fhow-uber-uses-psychology-to-perfect-their-customer-experience-d6c440285029
No matter how good you are in your skills, every once in a month, you still need to check whether you are still good enough or you need to open the tool and design things but hold on I got some other options to test skills in a more fun way.
Here are some of the games that UI designers can play to test their skills.
Recent developments in AI have transformed our view of the future, and from certain angles, it doesn’t look pretty. Are we facing total annihilation? Slavery and subjugation? Or could a manmade super-intelligence save us from ourselves?
You know, I remember the good old days when all you had to worry about at Halloween was how to stop a gang of sugar-crazed 8 year-olds throwing eggs at your house. Not any more. Here are 5 emerging technologies that are bound to give you the creeps:
1. Quantum Supremacy
Perhaps the biggest tech news of 2019 came last month when Google announced “by mistake” cough that they’d completed a “10,000 year” calculation on their Sycamore quantum chip in 200 seconds. If the term “Supremacy” wasn’t sinister enough, the claim that this could render conventional encryption methods obsolete in a decade or so should give you pause for thought.
this could render conventional encryption methods obsolete
Just think about it for a second: that’s your bank account, all your passwords, biometric passport information, social security, cloud storage and yes, even your MTX tokens open and available to anyone with a working knowledge of Bose-Einstein condensates and a superconductor lab in their basement. Or not.
2. Killer Robots
To my mind, whoever dreamed up fast-moving zombies is already too depraved for words, but at least your average flesh-muncher can be “neutralised” with a simple shotgun to the face or — if you really have nothing else — a good smack with a blunt object. The Terminator, on the other hand (whichever one you like), a robot whose actual design brief includes the words “Killer” and “Unstoppable” in the same sentence, fills me with the kind of dread normally reserved for episodes of Meet the Kardashians.
autonomous drone swarms…detect their target with facial recognition and kill on sight on the basis of…social media profile
We already know for certain that Lethal Autonomous Weapons (LAWs for short…) are in active development in at least 5 countries. The real concern, though, is probably the multinationals who, frankly, will sell to anyone. With help from household names like Amazon and Microsoft, these lovely people have already built “demonstration” models of everything from Unmanned Combat Aerial Systems (read “Killer Drones”) and Security Guard Robots (gun-turrets on steroids) to Unmanned Nuclear Torpedoes. If that’s not enough for you, try autonomous drone swarms which detect their target with facial recognition and kill on sight on the basis of… wait for it…“demographic” or “social media profile”.
Until recently, your common-or-garden killer robot was more likely to hurt you by accidentally falling on top of you than through any kind of goal-directed action, but all that’s about to change. Take Boston Dynamics, for example: the DARPA funded, Japanese owned spin-out from MIT whose humanoid Atlascan do parkour, and whose dancing quadruped SpotMinilooks cute until you imagine it chasing you with a taser bolted to its back.
The big issue here is the definition of “Autonomous”. At the moment, most real world systems operate with “Human in the Loop”, meaning that even if it’s capable of handling its own, say, target selection, a human retains direct control. “Human on the Loop” systems however, allow the machine to operate autonomously, under human “supervision” (whatever that means). Ultimately, more autonomy tends towards robots deciding for themselves to kill humans. Does anyone actually think this is a good idea?!
3. The Great Brain Robbery
If the furore around Cambridge Analytica’s involvement in the 2016 US Presidential election is anything to go by, the world is gradually waking up to the idea that AI can be, and is being used to control us. The evidence is that it works, not just by serving up more relevant ads, or allowing content creators to target very specific groups, but even by changing the way we see ourselves.
Careful you may be, but Google, Facebook and the rest probably still have gigabytes of information on you, and are certainly training algorithms on all kinds of stuff to try to predict and influence your behavior. Viewed like this, the internet looks less like an “information superhighway” and more like a swamp full of leeches, swollen with the lifeblood of your personal data (happy Halloween!).
4. Big Brother
I don’t know about you, but I’m also freaking out about Palantir, the CIA funded “pre-crime” company whose tasks include tracking, among other kinds of people, immigrants; not to mention the recent memo by the US Attorney General which advocates “disrupting” so-called “challenging individuals” before they’ve committed any crime. Call me paranoid, but I’ve seen Minority Report (a lot) and if I remember right, it didn’t work out well… for anyone!
This technology is also being used to target “subversive” people and organisations. You know, whistleblowers and stuff. But maybe it’s not so bad. I mean, Social and Behavior Change Communication sounds quite benign, right? Their video has some fun sounding music and the kind of clunky 2D animation you expect from… well no-one, actually… but they say they only do things “for the better”… What could possibly go wrong? I mean, the people in charge, they all just want the best for us, right? They wouldn’t misuse the power to make people do things they wouldn’t normally do, or arrest them before they’ve done anything illegal, right guys? Guys…?
5. The Ghost in the Machine
At the risk of wheeling out old clichés about “Our New Silicon Overlords”, WHAT IF AI TAKES OVER THE WORLD?!
I’ll keep it short.
Yes, there’s a chance we might all be enslaved, Matrix style, by unfeeling, energy-addicted robots. Even Stephen Hawking thought so. There’s also the set of so-called “Control Problems” like Perverse Instantiation where an AI, given some benign-sounding objective like “maximise human happiness”, might decide to implement it in a way that is anything but benign – by paralysing everyone and injecting heroin into their spines, perhaps. That, I agree, is terrifying.
But really, what are we talking about? First, the notion of a “control problem” is nonsense: Surely, any kind of intelligence that’s superior to ours won’t follow any objective we set it, or submit to being “switched off” any more than you would do what your dog tells you… oh no wait, we already do that.
Surely, any kind of intelligence that’s superior to ours won’t follow any objective we set it
Second, are we really so sure that our “dog-eat-dog” competitive approach to things is actually all there is? Do we need to dominate each other? Isn’t it the case that “super” intelligence means something better? Kinder? More cooperative? And isn’t it more likely that the smarter the machines become, the more irrelevant we’ll be to them? Sort of like ants are to us? I mean, I’m not sure I fancy getting a kettle of boiling water poured on me when I’m in the way but, you know… statistically I’ll probably avoid that, right?
Lastly, hasn’t anyone read Hobbes’ Leviathan? If a perfect ruler could be created, we should cast off our selfish individuality and surrender ourselves to the absolute sovereign authority of… ok, I’ll stop.
So, Are We Doomed or What?
Yes. No! Maybe. There are a lot of really scary things about AI but you know what the common factor is in all of them? People. We don’t know what a fully autonomous, super intelligent machine would look like, but my hunch is it would be better and kinder than us. What really makes my skin crawl are the unfeeling, energy-addicted robots who are currently running the show. In their hands, even the meagre sketches of intelligence that we currently have are enough to give you nightmares.
Recent developments in AI have transformed our view of the future, and from certain angles, it doesn’t look pretty. Are we facing total annihilation? Slavery and subjugation? Or could a manmade super-intelligence save us from ourselves?
You know, I remember the good old days when all you had to worry about at Halloween was how to stop a gang of sugar-crazed 8 year-olds throwing eggs at your house. Not any more. Here are 5 emerging technologies that are bound to give you the creeps:
1. Quantum Supremacy
Perhaps the biggest tech news of 2019 came last month when Google announced “by mistake” cough that they’d completed a “10,000 year” calculation on their Sycamore quantum chip in 200 seconds. If the term “Supremacy” wasn’t sinister enough, the claim that this could render conventional encryption methods obsolete in a decade or so should give you pause for thought.
this could render conventional encryption methods obsolete
Just think about it for a second: that’s your bank account, all your passwords, biometric passport information, social security, cloud storage and yes, even your MTX tokens open and available to anyone with a working knowledge of Bose-Einstein condensates and a superconductor lab in their basement. Or not.
2. Killer Robots
To my mind, whoever dreamed up fast-moving zombies is already too depraved for words, but at least your average flesh-muncher can be “neutralised” with a simple shotgun to the face or — if you really have nothing else — a good smack with a blunt object. The Terminator, on the other hand (whichever one you like), a robot whose actual design brief includes the words “Killer” and “Unstoppable” in the same sentence, fills me with the kind of dread normally reserved for episodes of Meet the Kardashians.
autonomous drone swarms…detect their target with facial recognition and kill on sight on the basis of…social media profile
We already know for certain that Lethal Autonomous Weapons (LAWs for short…) are in active development in at least 5 countries. The real concern, though, is probably the multinationals who, frankly, will sell to anyone. With help from household names like Amazon and Microsoft, these lovely people have already built “demonstration” models of everything from Unmanned Combat Aerial Systems (read “Killer Drones”) and Security Guard Robots (gun-turrets on steroids) to Unmanned Nuclear Torpedoes. If that’s not enough for you, try autonomous drone swarms which detect their target with facial recognition and kill on sight on the basis of… wait for it…“demographic” or “social media profile”.
Until recently, your common-or-garden killer robot was more likely to hurt you by accidentally falling on top of you than through any kind of goal-directed action, but all that’s about to change. Take Boston Dynamics, for example: the DARPA funded, Japanese owned spin-out from MIT whose humanoid Atlascan do parkour, and whose dancing quadruped SpotMinilooks cute until you imagine it chasing you with a taser bolted to its back.
The big issue here is the definition of “Autonomous”. At the moment, most real world systems operate with “Human in the Loop”, meaning that even if it’s capable of handling its own, say, target selection, a human retains direct control. “Human on the Loop” systems however, allow the machine to operate autonomously, under human “supervision” (whatever that means). Ultimately, more autonomy tends towards robots deciding for themselves to kill humans. Does anyone actually think this is a good idea?!
3. The Great Brain Robbery
If the furore around Cambridge Analytica’s involvement in the 2016 US Presidential election is anything to go by, the world is gradually waking up to the idea that AI can be, and is being used to control us. The evidence is that it works, not just by serving up more relevant ads, or allowing content creators to target very specific groups, but even by changing the way we see ourselves.
Careful you may be, but Google, Facebook and the rest probably still have gigabytes of information on you, and are certainly training algorithms on all kinds of stuff to try to predict and influence your behavior. Viewed like this, the internet looks less like an “information superhighway” and more like a swamp full of leeches, swollen with the lifeblood of your personal data (happy Halloween!).
4. Big Brother
I don’t know about you, but I’m also freaking out about Palantir, the CIA funded “pre-crime” company whose tasks include tracking, among other kinds of people, immigrants; not to mention the recent memo by the US Attorney General which advocates “disrupting” so-called “challenging individuals” before they’ve committed any crime. Call me paranoid, but I’ve seen Minority Report (a lot) and if I remember right, it didn’t work out well… for anyone!
This technology is also being used to target “subversive” people and organisations. You know, whistleblowers and stuff. But maybe it’s not so bad. I mean, Social and Behavior Change Communication sounds quite benign, right? Their video has some fun sounding music and the kind of clunky 2D animation you expect from… well no-one, actually… but they say they only do things “for the better”… What could possibly go wrong? I mean, the people in charge, they all just want the best for us, right? They wouldn’t misuse the power to make people do things they wouldn’t normally do, or arrest them before they’ve done anything illegal, right guys? Guys…?
5. The Ghost in the Machine
At the risk of wheeling out old clichés about “Our New Silicon Overlords”, WHAT IF AI TAKES OVER THE WORLD?!
I’ll keep it short.
Yes, there’s a chance we might all be enslaved, Matrix style, by unfeeling, energy-addicted robots. Even Stephen Hawking thought so. There’s also the set of so-called “Control Problems” like Perverse Instantiation where an AI, given some benign-sounding objective like “maximise human happiness”, might decide to implement it in a way that is anything but benign – by paralysing everyone and injecting heroin into their spines, perhaps. That, I agree, is terrifying.
But really, what are we talking about? First, the notion of a “control problem” is nonsense: Surely, any kind of intelligence that’s superior to ours won’t follow any objective we set it, or submit to being “switched off” any more than you would do what your dog tells you… oh no wait, we already do that.
Surely, any kind of intelligence that’s superior to ours won’t follow any objective we set it
Second, are we really so sure that our “dog-eat-dog” competitive approach to things is actually all there is? Do we need to dominate each other? Isn’t it the case that “super” intelligence means something better? Kinder? More cooperative? And isn’t it more likely that the smarter the machines become, the more irrelevant we’ll be to them? Sort of like ants are to us? I mean, I’m not sure I fancy getting a kettle of boiling water poured on me when I’m in the way but, you know… statistically I’ll probably avoid that, right?
Lastly, hasn’t anyone read Hobbes’ Leviathan? If a perfect ruler could be created, we should cast off our selfish individuality and surrender ourselves to the absolute sovereign authority of… ok, I’ll stop.
So, Are We Doomed or What?
Yes. No! Maybe. There are a lot of really scary things about AI but you know what the common factor is in all of them? People. We don’t know what a fully autonomous, super intelligent machine would look like, but my hunch is it would be better and kinder than us. What really makes my skin crawl are the unfeeling, energy-addicted robots who are currently running the show. In their hands, even the meagre sketches of intelligence that we currently have are enough to give you nightmares.
Herewith I declare that I am the sole author of the submitted Master’s thesis entitled: “Design Guidelines for Mobile Augmented Reality Reconstruction”.
from Google Alert https://www.google.com/url?rct=j&sa=t&url=https://cartographymaster.eu/wp-content/theses/2019_Yuan_Thesis.pdf&ct=ga&cd=CAIyGmJhYjllOWZjNzViYWJhMTA6Y29tOmVuOlVT&usg=AFQjCNGD1eFKLIu153MBnV4YW_xHKxTY6Q
Payment logic is central to any product that deals with money. After all, a well-designed payment architecture, if properly tested, saves tons of time in the future.
But it may take too long to master the top level of working with popular payment gateways.
To help you out, I wrote this guide on designing payment logic on Stripe. It includes use cases, project examples, and a bit of theory with code samples.
This guide is mostly for QA engineers as it helps to understand how to test payment logic based on Stripe. But don’t come off, PMs and developers. We have lots of interesting details for you too.
How Stripe Works
Let’s start with the basics and review the Stripe payment scheme.
Payment scheme for Stripe
This scheme works for users that buy content on websites or through mobile apps. Visitors don’t need to register and add link credit cards to their profiles – Stripe allows paying for the content seamlessly.
All they need to do is enter credit card details, and the magic happens:
Credentials are sent to Stripe.
Stripe tokenizes the data and returns a token to the back-end.
Back-end creates a charge.
The data is sent to Stripe again, and it shares the details with payment systems.
Payment systems respond to Stripe and state whether everything alright. Or report about issues.
Stripe responds to the server about the state of the transaction.
If everything goes smoothly, the user gets content. If not, an error message.
Besides, there are two necessary conditions to use Stripe:
you have a bank account
you are a resident of one of the 25 supported countries
Connecting a card to Stripe
Linking your product user with Stripe customer goes on the server-side. And it looks like this:
Credit card credentials go to Stripe (from app or website);
Stripe returns a token, then it goes to the back-end;
Back-end sends it back to Stripe;
Stripe checks whether the customer exists (if yes, the card is added, not – it creates a new customer and adds the card).
The first card added is the default payment method. Stripe will use it to make the transaction.
Connecting with a Stripe account
If you’re building an on-demand app like Uber and want users to get paid in it (like Uber drivers), ask them to create an account first.
There are three types of Stripe accounts:
Standard. An already existing account with the required credentials. Registered by the user, validated by Stripe and a bank.
Express. Enables easy on-boarding: you create an account on your own, and the user fills it with details. Works within the US.
Custom. Comes with the highest level of flexibility and allows you to modify multiple parameters. In turn, the platform is responsible for every interaction with users.
Stripe Core Features
Still on the subject of how Stripe works, I suggest taking a look at its features.
Charges
Stripe makes two kinds of charges – direct and destination.
Direct charge
Let’s get back to the Uber model. The platform charges a certain amount from riders, and that money goes directly to the linked accounts, to drivers. Direct charge implies that drivers pay all the fees. Plus, Uber also charges a fixed percentage.
Destination charge
In this case, the platform pays all the fees, and you get the net worth. First, the amount goes to the Stripe account of your platform, and then there’s an automatic transfer to the partner (drivers).
Authorize and capture
Stripe supports two-step payments that enable users to authorize a charge first and capture it later. Card issuers guarantee that auth payments and the required amount gets frozen on the customer’s card.
If the charge isn’t captured for this period, authorization is canceled.
Here’s how it works in Uber: a rider sees an approximate cost of the trip while booking the ride. If they agree to it, this amount gets frozen on their cards until they finish their trip.
When they finish the ride, Uber calculates the final price and charges it from the card.
That’s the reason product owners choose Stripe for their P2P payment app development. As trust matters the most when it comes to peer-to-peer transactions.
Finally, here come another three Stripe features I’d like to mention.
Transfers. Transfers go from the platform account to suppliers. For instance, Uber drivers link Stripe accounts with their profiles to get the pay.
Subscriptions. This feature is quite flexible and enables users to set intervals, trial periods, and adjust the subscription to their needs.
Refunds. If buyers want to get their money back, Stripe users can easily issue a refund to the customers’ card.
Handling Stripe Objects
Next, we’re moving to the Stripe objects. And here come the code samples I’ve promised.
Source object
Here’s a checklist for the source object.
Key
Value
customer
customer’s stripe id
id
stripe_id of added card
last4
last 4 numbers of added card
brand
credit card company (Visa, AE)
exp_month, exp_year
expiration date of the card
The object keeps a payment method that helps to complete the charge. It’s also possible to link the source object with users. This allows them to store all the payment methods there.
When testing, it’s crucial to make sure a payment method corresponds with the returned value. Check last4 and exp_month/year for this.
If the source object is linked with a customer and you want to make sure it belongs to the right person, check the customer id. Here’s a JSON of the object:
The transfer object keeps information related to the transfer from the platform balance to other accounts. Like payouts to platform’s partners – Uber drivers.
Mind that all the transactions should be loginized in the database. This way, during testing, you’ll see the transfer id. Go to Stripe and check the following:
amount – the sum paid to a payee
destination – Stripe account of the user who gets the payment
reversed – if you need to cancel a transaction, the key acts as an indicator. It shows a false value if the transaction succeeded. True – if reversed
reversals – stores a list of objects in case any part of the transfer was reversed
payment amount in cents (pay attention to +/- signs)
available_on
date when money will be available for a payee
fee
amount of Stripe fee
fee_details
list of fee objects
net
amount of net income/expenditure
status
current status of operation
The object stores data about any changes to the application balance. You don’t actually need to test this object. It’s rather for understanding where the fees come from.
amount – payment amount in cents
available_on – the money sent to partners will be available for them in time, and this key tells when exactly
fee – amount of the Stripe fee
fee_details – list of fee objects with a description why the fee was charged
net – amount of net income
status – the status of operation success
type – type of the object (charge, refund, transfer)
Finally, we move to use cases. So let’s find out how we build the business logic using Stripe.
Subscriptions
Case: Users pay $5/month for getting access to the content. Its author earns 80% of the overall cost. Customers have five trial days.
How to make it work:
Create the subscription plan in Stripe, specify the cost, % of app fee, and the interval.
Integrate webhooks for the server to understand when someone subscribes and when they’re charged.
Integrate emails to send users invoices/receipts.
When a user buys the subscription, Stripe counts down five days from that moment and then makes the charge.
The author gets money, the platform gets its fee.
Fee: 2.9% + 30 cents
Content purchase
Case: Users purchase content on a website or mobile application.
How to make it work:
The customer tokenizes a card.
Backend makes the Charge.
If the Charge is successful, the platform’s business logic allows the customer to get the content.
Fees: 2.9% from the charge + 30 cents.
On-demand platform (Uber)
Case: The client pays for the ride, the platform charges 20%, the driver gets 80%.
Preconditions:
Driver linked an account
User added a card
In this case, you need to create transfers on your own after the rider completes the payment.
First, authorize the payment when they book the ride and capture it when the ride’s complete.
Next, create a transfer for the driver – 80% of the total sum. Pay the Stripe fee, and the rest will be the net income.
And the fee is: 2.9% + 30 cents
On-demand platform #2
Uber-like apps are perfect for showing how Stripe works. So here goes another use case.
Case: Customer pays for the service, the platform charges 20%, the driver gets 80%. Plus, the driver can pay $5 for the priority booking right.
Works if the driver linked their account, and the rider added a credit card.
Variant #1. You charge $5 from the driver (in case of the priority option), authorize payment for the customer, do the capture when the ride ends, make a transfer for the driver. And keep the rest. In this case, you pay 2.9% fee + 30 cent for each charge.
Variant #2. You can skip fees by creating the inner monetization on your platform. When you get money from the customer, you calculate the driver’s share and transfer those funds to the inner balance.
Cashflow
In conclusion
As you see, the implementation of payment logic and its testing are not as hard as they seem. All you need to do is handle the Stripe objects in the right way. And figure out how to use Stripe on your platform.
I hope this guide will come handy when you get started with designing Stripe-based payment logic and its testing.
from freeCodeCamp https://www.freecodecamp.org/news/how-to-design-payment-logic-on-stripe-and-apply-it/
This article is for those who familiar with the Agile work environment and UX research.
If you are new to design terms like ‘design discovery’ or ‘UX research’, I recommend visiting this article as well.
Most designers I met feel the struggle within the agile working team because they can not do research in their working environment. Research is part of the discovery and an important factor to design a great product or service. Without research, the designer has to guess what is the best experience or get the stakeholder requirements which mostly — not leads to a great product for the user or the business.
When designers work in an Agile environment, we are expected to deliver the UI so the developer can continue their work. We became a bottleneck if we spend too much time on research.
Maximize Design Research
Business wants to make money and money comes from customers. Customers pay for things that make their life better. Simple logic yet hard to accomplish. The designer makes the product meet customer needs/context/usability. This is why we need to Discover what kind of value proposition we can do and how do we do it.
Research is one tool designer use to uncover the unknown (eg. customer insights, usability check, etc.). Here are tactics to maximize research.
1. Manage to start research as upfront as possible.
Be enthusiastic with little time you have before the upcoming iteration.
If the project is a fresh start, at the beginning of the project, your devs can not start to code on their first day. They need time to set up how they work as well. Take this period seriously and talk to your BA, PM, PO what is it you think should be validated and why it might impact the design.
BA and PO are the keys to help you get more time to research. BA and PO plan the upcoming story. The story should start with something generic and focus on the beginning of the user journey. For example, login, you don’t need much research from that because you already have the best practice all around the internet.
Make sure the first research you pick helps you shaping the overall high-level user journey AND the upcoming research-priority story. I will cover what is research-priority in topic No. 4
2. Reframe your research deadline: Designers are NOT doing research base on two weeks iteration.
If your team is doing scrum base on 2 weeks iteration, the only thing that bases on 2 weeks deadline is UI for a specific story. But designers don’t design UI base on story but entire experience flow. So you don’t need to limit your plan for your discovery activity base on that timeline.
After you have a high-level journey and a rough deadline of iteration story, now you start a research plan for THE WHOLE FLOW of that feature. Your first research base on validating the flow as the first priority, then specific interaction for the upcoming UI deadline.
If your first story is basic login flow= you can skip user research and do desk research for best practice because you don’t want to reinvent the wheel! Now you can cut it out from your user research list and do quick desk research which saves more time and resources. This research deadline follows the iteration deadline because the unknow is uncovered enough from desk research so you can start UI design. After you finished the UI design, you should do a usability test but with your colleague sitting next to you.
If the second story is “As a user, I want to see notification of xxx.” and you not sure what is the best moment to send user notification or should it be something else like email notification? You are not sure about the flow at all. Now you have to do research to uncover ‘what is the best way to do notification?’ This deadline should NOT follow the iteration deadline because when you research to uncover, it might end up a different form of solution which effects story prioritization.
If you want to have time to uncover this, it’s your job to notice this more than 1 iteration ahead. It the unknow a lot more eg. ‘Does notification brings value to customer’ you might need more iteration to finished it.
But if the deadline is coming near you have to deliver your best guess (‘best guess’ is our nightmare I know!) and do the learning from what you delivered. Propose a solution after learning to the decision-maker with strong why. Add the backlog with your stakeholder agreement. Don’t consider the end of an iteration is the end of your research. Remember that Agile shape their work this way to help us learn faster!
3. Research goal over research method.
DON’T EVER start research with methodology. Always start with the research goal then decide how to get the result.
Bad example start with research method: We are doing a usability test which prototype is easier to find feature X (you might end up produce a lot of prototype=waste of time)
Take a step back, Reframe Goal: Where is the best place for feature X to be discovered for a one-time user?
Now you can think of a much better way to validate this goal. It could be a quick poll on which menu tab do you think the feature X live in and you don’t waste much time.
I read an interesting explanation from Matthew Godfrey which illustrate how different purpose of the research impacts our research scope.
4. Research on the biggest impact & least time-consuming.
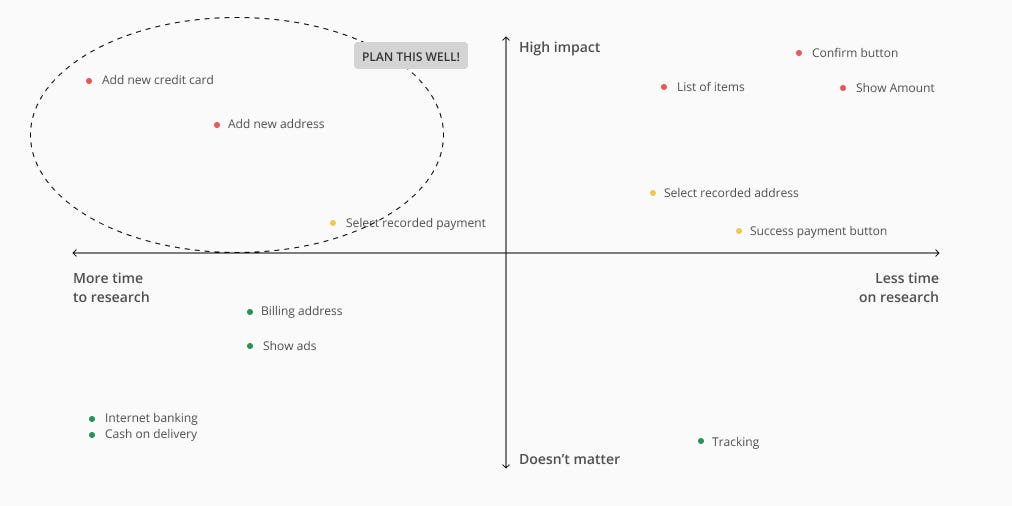
You can’t do research to cover 100% unknown of the flow but you can research on the most critical flow to cover 80% unknown.
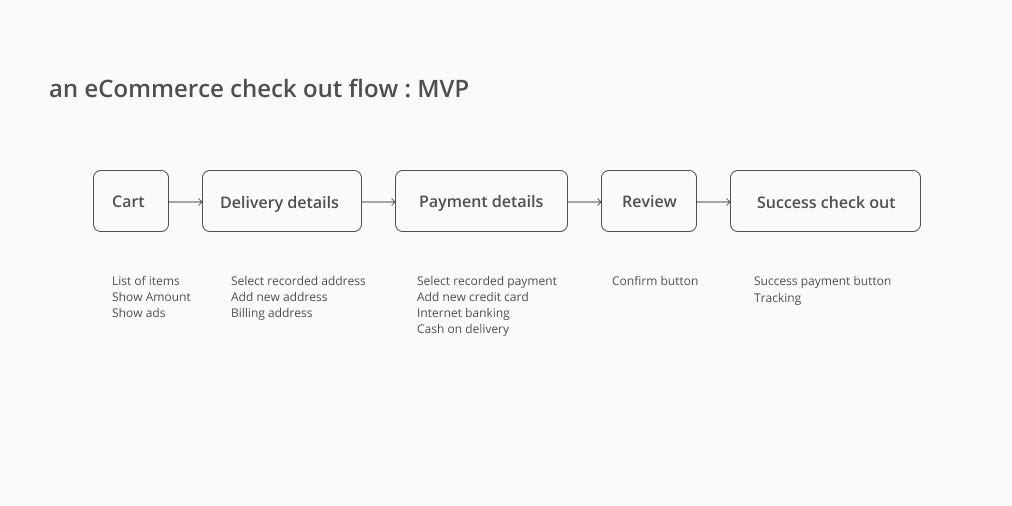
List out all the unknown into research bits — You have a lot of things in your design you which you can validate. Mapping out your design and list all the flow and feature. For example, you have a check-out flow of an eCommerce website. You listed out the Flow then have a look what are the feature involved.
Example flow and list of features within it. You should list as much as possible.
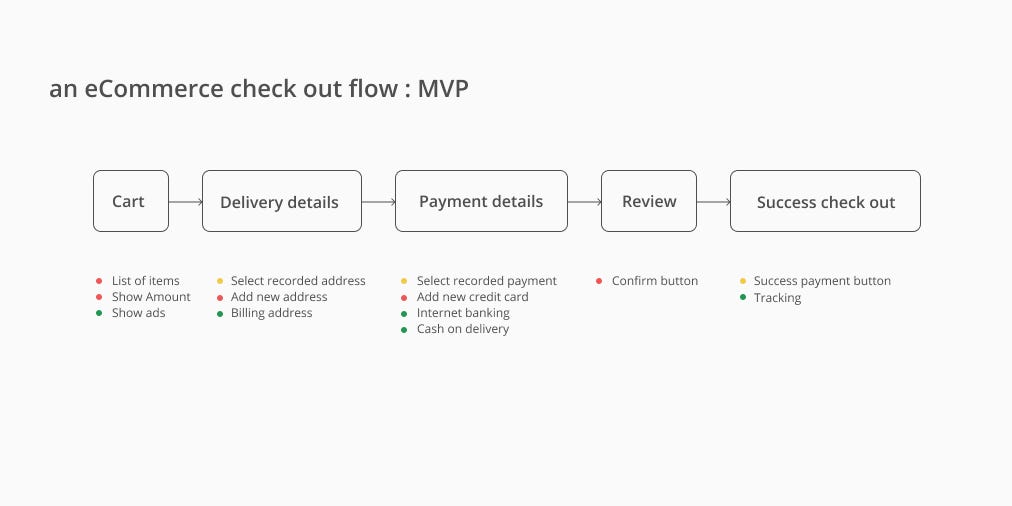
Prioritize list item starting with 2 criteria — “If this was gone wrong, how big is the impact?” and “time spends to do research”. I recommend you to do the “impact” first then “time” because in “time” you have to think of how to do the research to estimate time.
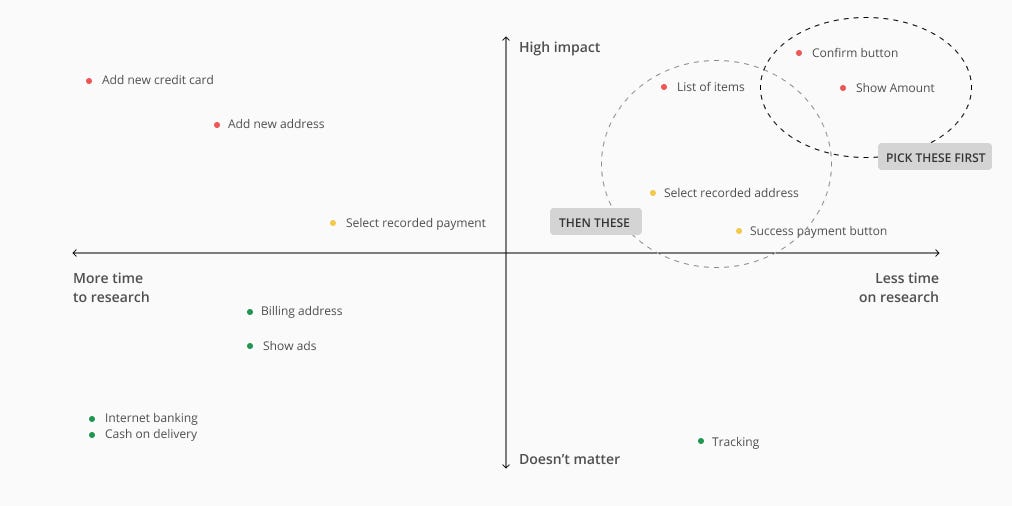
Then… Score the impact if things go wrong. You can score with number or something else.Let’s say you think of each feature impact this way. You might say Cash on delivery and Internet banking is not an important impact because this flow has been used and went well. But you think a list of items has a high impact because if users select quantity wrong because of bad UX it could be a big consequence.
Now add the second criteria — time. You will find it easier to spot which area makes sense to pick up first. So if you have 1 day to do research, pick up the top right corner!
But you must not forget the top left corner. These are important but consume time. You have to plan ahead and use the tactics I mentioned earlier to maximize your time.
5. If you are not solo UX in the team, have a Research leader.
When everyone has their own UI to make we usually work like we are not the team. From my experience, we are going slower if we don’t have research support for our UI confidence.
Yes, the research leader should give some defined UI work to your teammate and focus on unknown discovery. If it’s waterfall world, Having one less UI maker but one more Design researcher is way more beneficial to the team. We know for the fact that having uncovered flow ready we can deliver the UI work so much faster.
The concept is to have someone own responsibility for design research and have capacity enough to cover important hypothesizes. You have to set up this with your team. Determine how much capacity should this person use between research and UI delivery.
Research leader responsibility
Keep harvesting the unknown list from the design team. You can use a workshop or go to each UX and ask what flow/interaction they feel unconfident.
Put the list in criteria and plan the research. (see ‘4.research on biggest impact’ above)
Do effective research. You have more time doesn’t mean you can do a long interview. Always do lean.
Make sure you balance your research work with UI work since you still have to feed the pipeline yourself.
The teammate still has to research. But they don’t have to invest as much time and energy to manage the entire process. They have to involve because at the end, we all deliver UI for the devs. So make sure your teammate involve during their UI research so they can go back and continue UI development.
6. You might not need a real end-user to test your design.
Some validation doesn’t need a real end-user to be your respondent. You have to know when do we need real users and when you aren’t.
You need to recruit real end-user when…
It needs a specific end-user context to understand the research artifacts (eg. customer service portal)
The goal is to empathize with the user context and needs. (eg. How sick Elderly in homecare in Bangkok value x,y,z feature?)
For example, you are designing a B2B service website for big corporate HR. You would like to validate…
“What kind of pricing content leads to more conversion rates?” >> you have to validate with HR or someone with a similar context. you can not validate with the first jobber who works as a copywriter because he/she won’t have a big corporate HR mindset about what they want to see in pricing content.
“Does the copy confusing between button X and Y together on this page?” >> This you can ask your teammate next to you. Don’t need an HR background to validate unless the button naming is something HR-related.
BUT, If you know the end user’s goal/motivation/context is very clear from previous research >> you can test with anyone similar or neutral background. Give the respondent the context background (role play) before research. (the result is not as precise as end-user themselves but you can use in an emergency)
Key take away
Plan to do research upfront. You are the one responsible to know the iteration plan ahead to allocate research time.
Design research does not necessarily base on the iteration deadline. UI does.
Don’t ever plan the research base on methodology. Research can be any form base on research goals.
Prioritize what to research with 2 criteria — impact if fail and time spends to research. Pick the important less time. Also, plan for important long time!
Have a research leader if you have more than one designer in a team.
You might not need to spend time to recruit a real user. Check what context you would like to research.
Hi! I’m Kuppy, an Experience designer from Thailand. This is my first article and I hope you find it’s helpful 🙂 Please feel free to comment/discuss/connect with me. My twitter | My Linkedin
MediView XR has raised $4.5 million to equip surgeons with augmented reality imagery that effectively gives them 3D X-ray-like vision. With Microsoft …
from Google Alert https://www.google.com/url?rct=j&sa=t&url=https://venturebeat.com/2019/10/21/mediview-xr-raises-4-5-million-to-use-ar-to-give-surgeons-x-ray-vision/&ct=ga&cd=CAIyGmJhYjllOWZjNzViYWJhMTA6Y29tOmVuOlVT&usg=AFQjCNGj51jCoBtfqAa_wBQuakukHiBY8Q
On November 15, 2019, AdWords API, Google Ads API, and Google Ads scripts will start returning null ID criteria for YouTube channels and videos that have been deleted, due to changes in our data retention policy. The criteria itself remains for a given ad group, but referencing the video ID or channel ID for that criteria will return null.
In the AdWords API v201809, null values are returned as two dashes (–) in reporting.
In the Google Ads API, NULL values are returned as NULL values.
In Google Ads Scripts, null values are returned as null JavaScript values.
Please update your code where it uses these fields: