“You are not your user” A reminder that you are not designing the product for people like yourself. Often used as a way to encourage more user research in a project.
“If Henry Ford had asked people what they wanted, they would have told him faster horses” Used as a counter-argument to the previous statement, when you start to realize you won’t have time or money to do enough user research.
“We are testing the design, not your skills” Disclaimer given to users at the start of a user testing session to make them feel better about being stupid.
“Designers should have a seat at the table” When you are not able to prove your strategic value to the company based on your everyday actions and behaviors, and you have to beg to be invited to important meetings.
“Choices should be limited to 7 plus or minus 2” A nicer way of saying that choices should range from 5 to 9, without sounding too broad. When in reality every good designer knows choices should range from 1 to 2.
“People don’t want to buy a quarter-inch drill bit; they want a quarter-inch hole” Wait, do they really want a hole? Or do they want wireless Bluetooth instead, so no holes are needed whatsoever?
“UX should be a mindset, not a step in the process” When you realize the deadline is coming close and you haven’t been able to finish your deliverables. Used to try to retroactively convince the PM to extend the project timeline.
“Content is king” A pretty strong argument to convince everyone to push the deadline because you haven’t received the content that will go on the page you are designing.
“Never underestimate the stupidity of the user” An efficient way of outsourcing your own responsibility of giving users enough context so they know what to do (a.k.a. being a good designer).
“I’m wondering if this breaks accessibility standards” Used as last resort when you are running out of arguments to convince other designers their design is not working.
“A user interface is like a joke; if you have to explain it, it’s not that good” An easy way of killing that onboarding wizard/walkthrough idea your stakeholders are asking for. Watch out for the backfire: others might agree with your argument and blame on you the fact that the product is not that working that well.
“People don’t scroll” The most offensive statement you can throw at a designer.
“People are used to scrolling; think about the way you use Instagram” A polite counter-argument to the previous statement. The Instagram example can be replaced by any other feed-based product your interlocutor might be addicted to.
“The fold doesn’t exist” If you can’t convince them, confuse them.
“UI vs. UX” Pzajsodiajhsknfksdjbfsdbfkqwehjoqiwejroe. Usually followed by even more cliché analogies of ketchup bottles or unpaved walkways.
“All pages should be accessible in 3 clicks” Just. Don’t.
“Should designers code?” A commonly used wild card when the audience is running out of questions in a Q&A session at a design event.
“If you think good design is expensive, you should look at the cost of bad design” A passive-aggressive way of explaining to clients you will not reduce your price. Usually ineffective.
“You can’t design an experience; experiences are too subjective to be designed” An argument used by coworkers who are running out of things to say but somehow still want to sound smart.
“Let the users decide” None of us is going to win this endless argument, so we should take this to c̶o̶u̶r̶t̶ user testing. But I’m still going to prove you wrong at the end.
“No one enters a website through the homepage anymore” Popular at the peak of the SEO era (2005–2008), the argument was used to cut short endless meetings where a large group of stakeholders is trying to design your homepage by committee.
“The only other industry who names their customers ‘users’ are drug dealers” Can’t even explain why this one exists. Used a lot when the term UX came about in the early 2000s, is becoming pretty popular again in the “designing for addition” era.
“When escalators break, they actually become stairs” Originally used to explain the concept of graceful degradation, the quote started being adopted by developers to convince the product owner that certain bugs do not need to be fixed.
“Mobile users are distracted” Just a generalization made by someone who still thinks the primary use case for mobile devices is on-the-go, while doing groceries and simultaneously trying to tame a wild giraffe.
“You don’t know what you don’t know” Honestly, no one knows.
“Leave your ego by the door” An inspirational quote used before you walk into a user testing session or a collaborative work session with your coworkers. Looks particularly great if written in Helvetica, printed and framed, and hung by the entrance of truly collaborative office spaces.
“Double diamond” Hey, we need a slide in this deck that represents our design process — can you come up with something that is relatively simple to understand, that will make us look less chaotic than we actually are?
“Users don’t read” An overly used argument to convince clients and stakeholders to cut copy length in half. If you made this far to this article, you’re living proof that this statement is untrue.
Any cliché missing from the list? Please add it in the comments.
This article is part of Journey: lessons from the amazing journey of being a designer.
from Stories by Fabricio Teixeira on Medium https://uxdesign.cc/a-comprehensive-and-honest-list-of-ux-clich%C3%A9s-96e2a08fb2e9?source=rss-50e39baefa55——2
I’ve spent a majority of my adult life in investing.
Recently I became more interested in approaching the topic from a quantitative angle. The promise of automating an investment approach whilst I sit on a beach sipping sangria’s was all too compelling to ignore.
If I have seen further it is by standing on the shoulders of Giants. — Isaac Newton
With Sir Isaac’s expression in my mind I thought what better place to start than existing research papers. I thought hopefully they’ll give me some unique knowledge that I can build up on when I write my own strategies.
Around 6 months ago I stumbled across a research paper that on the face of it seemed very promising.
In short the technique goes something like this:
Start with past prices for equity indices.
Add some technical analysis.
Very familiar so far, but here’s where it gets a bit fancy.
Run this data through a Wavelet Transform.
Then run the output of the WT through stacked auto-encoders.
And out of this pops the magic.
The predictions are claimed to be more accurate than had you have not done any of the fancy stuff in the middle. And all we’re using is past prices!
Skeptical, I delved deeper.
Wavelet Transform
The paper starts with a 2 level WT applied twice.
def lets_get_wavy(arr): level = 2 haar = pywt.Wavelet("haar") coeffs = pywt.wavedec(arr, haar, level=level, mode="per") recomposed_return = pywt.waverec(coeffs, haar) sigma = mad(coeffs[-1],center=0) uthresh = sigma*np.sqrt(2*np.log(len(arr))) coeffs[1:] = ( pywt.threshold( i, value=uthresh, mode="soft" ) for i in coeffs[1:] ) y = pywt.waverec(coeffs, haar, mode="per" ) return y
Now there isn’t really a clear mention in the paper as to if a wavelet transform is applied to just the close price, or to every input time series separately. They use the phrase “multivariate denoising using wavelet” which I’d assume to mean it was applied to every time series. To be safe I tried both methods.
Thankfully the issue starts to become quite apparent from here.
I’m sure you’ve heard many times that whenever you’re normalising a time series for a ML model to fit your normaliser on the train set first then apply it to the test set. The reason is quite simple, our ML model behaves like a mean reverter so if we normalise our entire dataset in one go we’re basically giving our model the mean value it needs to revert to. I’ll give you a little clue, if we knew the future mean value for a time series we wouldn’t need machine learning to tell us what trades to do 😉
So back to our wavelet transform. Take a look at this line.
sigma = mad(coeffs[-1],center=0)
So we’re calculating the mean absolute deviation across the noisy coefficient. Then..
(pywt.threshold( i, value=uthresh, mode="soft") for i in coeffs[1:])
We’re thresholding the entire time series with uthresh derived from our sigma value.
Notice something a little bit wrong with this?
It’s basically the exact same issue as normalising your train and test set in one go. You’re leaking future information into each time step and not even in a small way. In fact you can run a little experiment yourself; the higher a level wavelet transform you apply, miraculously the more “accurate” your ML model’s output becomes.
Using a basic LSTM classification model without WT will get you directional accuracy numbers just over 50%, but applying a WT across the whole time series will erroneously give you accuracy numbers in the mid to high 60’s.
I thought perhaps I’ve misinterpreted the paper. Perhaps what they did was apply the WT across each time step before feeding data into the LSTM.
So, I tried that.
Yep, accuracy dips below 50%.
We don’t even need to go as far as the auto-encoder part to figure out a pretty huge mistake that’s been made here.
We’re here though so we might as well finish up to be sure.
Stacked Auto Encoders
Stacked auto-encoders are intended to “denoise” our data with a higher level representation. The number of output nodes you give each level will force our data into a less dimensions, with some loss. I’m not entirely sure how this would ever help our LSTM make predictions; ultimately all we’re really doing here is just removing more data that might have been useful to uncover patterns.
Your results won’t vary much here if you roll with stacked auto-encoder’s with greedy layer-wise training or just multi-layer auto-encoder’s.
Going down the stacked auto-encoder route you can build each layer up like so:
Then just fit and predict layer by layer until you’re 5 layers deep like the paper suggests.
The accuracy suffers a bit when using our leaked WT as input but is still erroneously much better than using LSTM’s alone, which would explain why the paper demonstrated such good results.
The end lesson here is clear, much like Frankenstein’s monster, piecing together random pages from a stats text book isn’t going to help us when we’re still only passing in past price data. The old adage comes true once more — if it looks too good to be true, it probably is.
Disclaimer This doesn’t constitute as investment advice. Seek advice from an authorised financial advisor before making any investments. Past performance is not indicative of future returns.
New advancements in technology led to the widespread use of facial recognitiontechnology. More and more business and organizations are using technology because it is fast and requires minimal interaction from the user. It is primarily used for security purposes. Many businesses and homeowners who use this technology do so in an attempt to ensure that only authorized persons can enter specific areas or access certain devices.
But you’d be surprised to know about some of this technology’s many other uses. Here are some you most probably didn’t know existed.
Finding Missing Persons
Facial recognitionsystems use a database to add photos of missing persons. The system alerts law enforcers when there is a possible match
Early Threat Detection
US Customs officials use facial recognitiontechnology to check the validity of passports. The FBI has also a system in place to check for persons of interest.
There are police officers in the US who can use their mobile phones to check the identities of suspects. They can use the photos to cross-reference with a database of known criminals.
Automated Jaywalking Fines
In China, police wear glasses equipped with Face Recognition technology in public places. Jaywalkers are automatically fined and notified through SMS when identified by Face recognition-equipped surveillance technology.
Book Lending/Libraries
One company has created a book lending library system with built-in face recognition. The system scans the employee holding the borrowed book and updates its database. The same solution could be used in public or school libraries to make the borrowing process faster and more exciting.
Banking with Confidence
Facial recognitionis an added layer of security for ATM transactions.
This is to verify the identity of the cardholder.
ATM’s with face recognition capabilities were recently introduced in Spain and in China. These allow customers to withdraw cash from their accounts without using a bank card. Only time will tell if facial scans will soon replace the use of ATM cards.
Casinos Catching Cheaters in the Act
Casinos use facial recognitionto spot potential cheaters in their establishments. They also use the system to keep track of blacklisted gamblers. This security measure makes card counting even more difficult.
Sporting and Entertainment Events
Facial recognitiontechnology has seen a rising demand in concerts and sporting arenas. This is due in part to the increasing number of terror attacks in public events. Facial recognitionsystems can check if an audience member has any criminal record.
Several venues use the system information to offer better deals to frequent patrons.
Famous people in attendance are also detected using the technology.
Online Purchases with Selfies
Face recognition authenticates the identity of people making online purchases using their smartphones. The system confirms the transaction upon verifying the buyer’s information in its database.
Retail Outlets
Some retail stores began using facial recognitiontechnology in their services. Customers can pay for their merchandise by having their faces scanned. The system then links the photo to the customer’s account in their database. Some stores also use this technology to detect shoplifters. The system can also detect persons who have displayed unwanted behavior in the past.
Bar Fines
There are several bars that began using face recognition software. This allows them to detect teenagers who use fake IDs to buy alcohol and cigarettes. This discourages underage drinking and use of illegal substances.
Restaurants
A KFC branch in China uses face recognition technology to accept payments. Customers pay by smiling at a screen equipped with the technology. The system checks its database and asks for a phone number for an added security check.
Hospitals
A hospital in China uses face recognition to accept payment for medical bills. Individuals need to create an initial profile for the system to use.
Schools
There are schools in the UK which have adopted face recognition to track attendance. The technology is also used to ensure order in classrooms. The system can also detect outsiders who pose as potential threats to the school. This may prevent gun attacks in the future.
Smart Cars
The new wave of automobiles now come equipped with face recognition software. This allows the vehicle to start only upon recognizing the driver. The system includes the safety feature of checking the driver’s level of alertness.
Hotel Booking
There are already hotels that use face recognition to scan returning guests. The system retrieves the guests’ profile and preferences. This allows the hotel personnel to give the guest a more personalized and warm greeting.
Select hotels have booths with face recognition technology. These kiosks issue the key card for the room to the guests themselves.
Dating Sites
Finding one’s potential mate online has become popular because of social media. Some dating sites now offer face recognition to match people with similar attributes. Although there are complaints of non-human matches reported in some sites:)
Airport Boarding
Several airports have introduced facial recognitionin their operations. This makes the checking in of luggage and the boarding process more convenient.
The system uses the passenger’s passport photo to verify against a database. Passengers are only allowed to check-in and board when there is a match in the system.
Identifying Pets!
Face recognition is also used in identifying the breed of your pet. This capability makes it possible to find missing pets as well.
In conclusion
Face recognition is far from perfect. Different facial expressions and lighting conditions may affect the software’s accuracy.
The technology only works well when the subject faces forward. Objects that are too far away may also become hard for the system to recognize. But advancements in AI and facial recognition keep on evolving. These developments will address the inaccuracies.
More and more applications are developed for facial recognition. The choices are limited only by your imagination and the technology’s increasing capabilities.
Chatbots are conversational interfaces meant to assist individuals in interacting with larger organizations.
If you’re looking for help while browsing a website, you might end up texting with a chatbot. They’re a bit more dynamic a problem-solver than a simple FAQ webpage. If you’re looking to speak with a customer service representative, a chatbot might try to help you out on its own, or it could help direct you to the proper department within an organization, where a human operator can provide assistance.
As this technology becomes more and more integrated into daily commerce, it’s worth asking: what barriers does the technology face today, what improvements are being made, and what can we expect of human-robot discourse in the future?
Limitations
It won’t take you all too long, under a certain line of questioning, to reach the limitations of bot technology in 2019.
As a four-time winner of the Loebner Prize — an annual competition that judges the world’s most human-like chatbot — Mitsuku is one of the most advanced algorithms in the field. I decided to have a little chat with her.
MITSUKU: Hi, I’m the world’s most humanlike conversational AI.
ME: Hi Mitsuku, can I interview you for an article about chatbots?
MITSUKU: Hi there unknown. Why do you want to do interview me for an article about chatbots so much?
ME: “So much” may be a bit strong. I figure you’d be able to help me understand chatbots better, yourself being one of them.
MITSUKU: Here’s something I meant to show you. Enter a date and I will tell you what the UK number one hit single was on that day.
MITSUKU: Please explain your reasoning.
As I spoke with Mitsuku, it became evident that she and I had a somewhat different sense of how our conversation was going to go.
ME: Apologies Mitsuku, but could we stick to the topic of conversation? I’m not interested in discussing music with you, so much as the intricacies of AI-integrated conversational bots in 2019. Does that make sense?
MITSUKU: No need to apologise. Do you mind if I tell other people?
MITSUKU: What are you interested in?
MITSUKU: It makes sense to me.
Notice how Mitsuku picks up on particular terms I use: “apologise”, “interested in” and “makes sense”. Mitsuku may be award-winning, but in her online form, she’s reminiscent even of the earliest chatbot technologies.
ELIZA was perhaps the earliest successful chatbot, created by an MIT researcher. Developed only a decade and a half after Alan Turing first proposed his so-called “Turing Test”, Eliza was able to hold full conversations (in a sense) with humans who typed to her.
ELIZA was, technically, quite complicated — more than can be explained simply in the scope of this article. Overall, though, her gimmick was pretty straightforward: whatever you’d type, she’d parry back in the form of a question.
“Men are all alike,” you might say.
It replies back: “what is the connection, do you suppose?”
You see? “Alike” to “connection”. Sometimes the mechanism was even more obvious than this.
“Well, my boyfriend made me come here.”
“Is it important to you that your boyfriend made you come here?”
Latest Advancements
ELIZA may be over half a century old now, but her essential underlying mechanisms remain. The majority of chatbots today leverage keywords and phrases in your text, in order to return a response that, even if it does sound like stilted conversation, makes some sort of cogent sense.
The most advanced AI chatbots incorporate similar mechanism but are powered by larger datasets for training and more advanced machine learning algorithms. In addition, today’s chatbots improve by leveraging user input as training data. An AI chatbot can learn to better serve those they converse with over time, by updating its machine learning models as it completes more and more conversations with humans.
In fact, the technology has been developing, in a meaningful sense, on two fronts: in AI development, but also in commerce.
Companies incorporating this mechanism into their customer service models have introduced a suite of new user experience components to the traditional chatbot paradigm.
Pop-up windows during online browsing and shopping are a time-tested marketing tactic, but new bots feature improved interface design, too. One popular trend is to display chats as text bubbles, to capitalize on our familiarity with those visual cues. After all, when the goal is to design a robot that mimics a human in conversation, familiarity in visual presentation is an integral part of the overall experience.
A good example of where commerce and technology come together came in 2016, when CoverGirl released a chatbot version of a social media influencer, Kalani Hilliker.
Studies show that chatbot users skew young, and female, so CoverGirl’s bot acted as a way for that demographic in particular to interact with its brand, in a way that may have felt novel or even fun to some.
What to Expect
We can expect chatbots to improve markedly over the coming years, as natural language processing in AI improves and proliferates.
Major tech companies now regularly build deep neural network technology that allows speech recognition machines to better understand and interact with people.
Once deep neural networks become more common, chatbots will start surpassing the classic Turing Test, proliferating online, and becoming a less awkward part of our everyday lives. In fact, some experts claim that chatbots could, one day, evolve to replace search bars in our internet browsing.
Think about it: when you query a search engine, you’re essentially asking a question that a machine is answering. Most of the time you type in an approximation or abstraction of your question, and then you have to scroll through varyingly relevant results. If that machine were conversational, you’d have a much easier time reaching the search result you’re looking for.
MITSUKU: I know far too many people to name them all.
ME: Can you name one?
MITSUKU: Mike.
ME: Ah, Mike! He and I go way back.
The State of Chatbots in 2019 was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Hacker Noon https://hackernoon.com/the-state-of-chatbots-in-2019-d97f85f2294b?source=rss—-3a8144eabfe3—4
Role-based personas derive from quantitative data and resemble the customer segments from more traditional market-research practices. Many usability professionals feel that these lack substantive information on the user’s thought processes and are overly reliant on modeling demographics on top of analytics. Personas are capable of answering what questions—for example: “What potentially meaningful patterns exist among our user population?” However, they fail to pursue the why questions. Just because we understand that a pattern actually exists, that does not necessarily mean we understood why it exists. While some UX professionals are comfortable speaking to why answers that are based solely on quantitative data, they typically frame these interpretations as being nothing more than reasonable, logical conclusions. However, these findings are vulnerable to confirmation bias because the conclusions depend so heavily on the researcher’s speculations.
Fictional Personas, or Proto-Personas
Fictional personas, or proto-personas, are based not on user research or feedback, but on the assumptions, anecdotes, and other past experiences of stakeholders and team members regarding users’ needs. While most UX professionals consider such personas to be flawed, the extent of their flaws and the purposes for which you could reasonably use them are less clear. Some UX professionals think teams should create proto-personas only as an exercise to promote thinking about the user as an individual who is different from oneself. Others think they can provide a useful starting point for generating hypotheses about users’ motivations and inclinations, which they would then validate through empirical observation. Critics think the act of creating proto-personas and the time and effort teams put into fleshing them out during such an exercise is toxic. That it creates an inescapable well of groupthink and results in other forms of bias that prevent related empirical-research efforts from moving forward.
Goal-Directed Personas
Goal-directed personas are most similar to the JTBD perspective. Focusing on the users’ goals is semantically similar to focusing on desired outcomes. However, despite their being goal directed, the personas themselves typically remain focused on creating a model of the users’ attributes. The goals typically diminish in importance because most of the researchers’ energy becomes entrenched in elaborating on the persona’s distinct motivations and needs. In the parlance of JTBD, focusing on job drivers, while giving little thought to success criteria stunts the persona’s growth.
A significant part of this fixation on attributes results from the focus on adding vivid details and stories to personas, which tend to be elaborate depictions of full personalities, having complete experiences, in the hope of making the personas feel real and relatable. The desire for personas to feel real and relatable is understandable and even admirable. Unfortunately, attempting to create that sense of reality by making personas feel like real people inherently turns them into something they were never meant to be. As I stated earlier, personas are aggregated proxies for groups of real-world users that represent their mental states and behavioral inclinations within a specific setting. Personas represent interconnected themes that occur within some meaningful, shared timeframe. Treating them as anything more becomes dangerously reductive. Personas do not have full personalities. Nor can they have complete experiences. Only people have full personalities and complete experiences. Personas are not people.
False Assumptions About Categorical Exclusivity
One of the most trying aspects of using personas in the workplace is having a stakeholder or team member walk up to you, with a part of the designed experience in hand, and asking, “Which personas are hitting this touchpoint?” or “Which personas are of critical concern during this part of the experience?” These kinds of questions are frustrating because personas don’t experience our products. People do.
Personas are neat, simple constructions that we pin to our walls. A Pragmatic Patrick is not a Dreaming Daniel and is never going to be. People are messy. They are fluid and fuzzy. A person can start a research and shopping journey as a Dreaming Daniel, then become more like a Pragmatic Patrick as they approach a purchase decision. They can be partly one persona and partly another. Such overlapping states could happen either sequentially or concurrently. The value of personas does not come from asking who is doing what, because a persona is not a who. Their value comes from knowing what mental states and behavioral patterns exist and considering them in all their potential forms. Different users can strongly manifest different personas at different moments, requiring different interpretations of their experience from the same stimulus on subsequent exposures.
I’ll illustrate this with an example: Recently, I was engaged in a research effort. We knew that two similar behavioral patterns existed that led to similar outcomes—at least from our perspective. We needed to learn whether consumers perceived these patterns and outcomes to be similar as well. Could the same workflow satisfy both behavioral patterns A and behavioral patterns B, or were these sets of behaviors sufficiently different from the consumer’s viewpoint to necessitate two semantically discrete pathways?
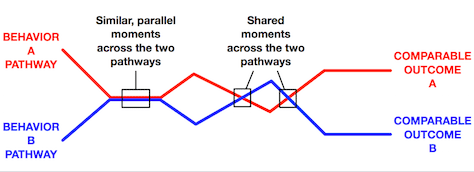
We found that consumers perceived the two sets of behaviors as being meaningfully distinct from one another and required different pathways. However, their following one pathway versus the other could be extremely variable. What’s more, many of the touchpoints along these discrete pathways either crossed over one another—creating a shared moment on the two pathways—or required some similar mimicry of comparable, parallel moments across the two pathways. Explicit signposts would be necessary to suggest how you might tailor actions along these touchpoints to either A or B behavioral inclinations and motivations, as shown Figure 1.
Figure 1—Two pathways that are semantically similar and dissimilar
Our findings were admittedly complex. In our early drafts of the results, it became clear that one specific issue was making it more difficult for our stakeholders and team members to comfortably come to terms with the learnings. They kept talking about A Shoppers versus B Shoppers. With all the discussion of two comparable sets of behaviors and two comparable pathways, the team felt the need to understand consumers moving down those pathways as two categorically distinctive groups of people. However, this rigidity and perceived categorical exclusivity made it more difficult for the team to understand the complex, interwoven relationships between the two pathways. These were not two roller coasters on entirely separate tracks that were simply near one another. They were two different trains that occasionally shared the same track, with railway switches separating and crossing their pathways at various decision points. To understand the true relationships between these two pathways and the two sets of behavioral inclinations, we needed to understand that the actual people moving through these pathways were dynamically more complex than passive passengers on a static course.
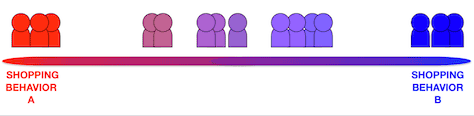
Imagine a spectrum with Shopping Behavior A on the left and Shopping Behavior B on the right, as shown in Figure 2. There were research participants who demonstrated strong tendencies toward the two extremes, and there were participants who demonstrated tendencies toward the middle ground between them.
Figure 2—Distribution of participants along a spectrum
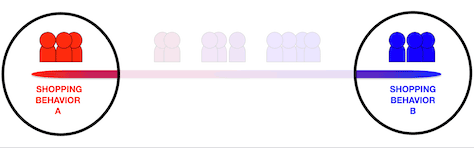
Individuals at the two extremes were categorically dissimilar from each other. They wanted different things and were going about getting them in different ways, as shown in Figure 3. Whatever combination of individual and situational variables added up to their cumulative past experience made them less likely to deviate from those extremes.
Figure 3—Participants at the extremes were very dissimilar
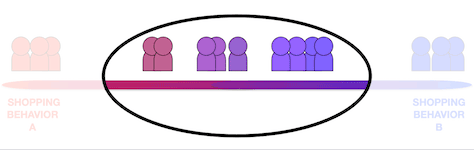
Individuals nearer the midpoint between the two extremes were more complicated. Sometimes they wanted different things and were going about getting them in similar ways. Sometimes they wanted similar things, but went about getting them in different ways, as shown in Figure 4. The individual and situational variables adding up to their cumulative past experience had less of a polarizing effect in comparison to that of the participants at the extremes. Instigating movement in one direction or the other was easier and far more likely.
Figure 4—Participants nearer the midpoint were more complex
Any given person has the equivalent potential of behaving either like a category member or a fluid, dynamic point, shifting along a spectrum. Thus, a population inherently does both at the same time. This idea might seem painfully obtuse and academic at first glance. However, a compelling simplicity is inherent in this idea that has huge tactical value—similar to learning that light behaves both like a particle and wave. When working with light, we have to make decisions considering all of the rules that apply, at all times.
Our stakeholders and team members needed to acknowledge that, to create an experience that complemented both of these pathways, the pathways had to be functional for both categorically static and spectrally fluid individuals simultaneously. To make that possible, we needed to create effective signposts that communicated accurate expectations, successfully execute our progressive-disclosure strategies, and follow other UX-design best practices. The only prediction we could reasonably make was that these meaningfully recurring patterns exist and, in most instances, we needed to attend consistently to both of them throughout the designed experience. Moments of addressing one pattern singularly and ignoring the other would be exceedingly rare—if they existed at all.
The sort of dilemma I’ve described is an inherent difficulty from which all personas suffer. Personas represent clusters of thought processes and behavioral inclinations co-occurring in the same moments of time, and we should almost always treat them as though they are simultaneously categorical and spectral. Any given data point that represents a person within an experience could actually be straddling two different personas—emphasizing or de-emphasizing each of them in turn or entering or exiting them entirely.
JTBD is better at fostering this understanding because it does not attempt to differentiate patterns that are based on people. This approach makes no claims regarding who might be thinking this thought versus that thought, nor who might be taking this action versus that action. It simply recognizes that certain thoughts and actions exist, in various forms, and that we need to attend to all of them because they all influence the user’s perception of progress toward the desired outcomes. The only reason ever to differentiate any of these patterns from one another in JTBD is when there is a dichotomy that is based on separate desired outcomes—not different users.
Conclusion
In summary, the attraction of using personas is undoubtedly powerful. The level of understanding that they seemingly promise is seductive. However, by their very nature, personas are exceedingly difficult to create and just as difficult to use. The construction and creation of a set of personas lacks a foundational methodology that has clear, operational definitions.
The primary focus of personas is summarizing complex, abstract concepts by meaningfully defining and clustering attributes that correspond to particular behavioral patterns. However, this focus on clustered themes that center on a representational archetype fosters a false expectation of true categorical consistency with real populations. Using personas is inherently risky because it increases the likelihood that reductive, simplistic thinking and assumptions might dictate design decision making.
JTBD offers a simpler solution that focuses on concrete concepts such as success criteria and avoids the unnecessary complexity of trying to model converging themes of thoughts and behaviors for anything beyond the user’s explicitly desired goals.
Mulder, Steve, and Ziv Yaar. The User Is Always Right: A Practical Guide to Creating and Using Personas for the Web. Berkeley, CA: New Riders Press, 2006.
Nielsen, Lene. “Personas.” The Encyclopedia of Human-Computer Interaction, Second ed. Interaction Design Foundation, 2013. Retrieved February 12, 2019.
Reynierse, James H. “The Case Against Type Dynamics.” (PDF) Journal of Psychological Type, January 2009. Retrieved February 12, 2019.
Spence, Janet T., Robert L. Helmreich, and Robert S. Pred. “Impatience Versus Achievement Strivings in the Type A Pattern: Differential Effects on Students’ Health and Academic Achievement.” Journal of Applied Psychology, December 1987.
Table 1 shows the types of research questions you might want to explore during individual user interviews, as well as the types of architectural decisions you might make based on the answers.
Table 1—Deep-linking research questions and associated decisions
Research Questions
Decisions They Support
Must users leave one digital tool and go to another tool to complete a task? What tasks require such a cross-application workflow?
Identifying applications and associated workflows that might require deep linking
Is a transition’s sequence always the same? For example, do users always go from Application A to Application B, not B to A?
Identifying the originating application and the destination application and determining whether deep links must be bidirectional or unidirectional.
What are the reasons users must transition from one application to another?
Evaluating whether a deep link is the most appropriate solution
When users leave one tool and go to another tool, do they close the originating application or keep it open to return to it later? If users have both applications open at once, are they on different monitors, in different windows, on different tabs, or in different Web browsers? Do users need to view the applications side by side?
Determining whether the destination application should open in the same tab or a new tab
If users view applications side by side, what is the purpose of doing so? What kind of work is the user doing? Copying and pasting data from one application to another? Verifying data entry? Looking up information in the destination application to evaluate or contextualize the information in the originating application?
Evaluating whether a deep link is the most appropriate solution
You should gather most of this information by having users walk through their process so you can directly observe their behaviors rather than merely relying on their verbal accounts of how they accomplish their tasks.
Once you’ve observed users going through their cross-application workflows and asked the appropriate follow-up questions to understand their needs in greater detail, you’ll be ready to review your data to determine whether patterns exist that tend to describe the reasons users require cross-application links.
Deep-Linking Patterns
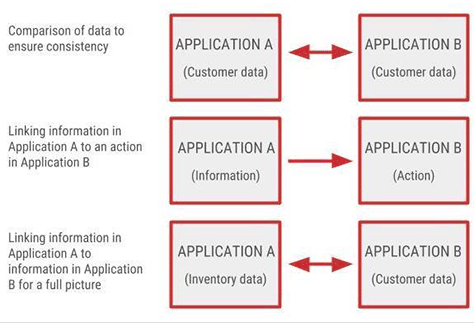
When conducting user interviews that focus on cross-application workflows, you’ll likely hear a variety of reasons why users might need to transition from one application to another. In conducting my own research, I have discovered that there are three primary patterns that describe users’ reasons for making transitions from one application to another. Understanding the need for a transition between applications is critical because it might reveal that a deep link is not the most appropriate solution for addressing a user need. It is important to know when a solution would not be the appropriate solution. Figure 2 illustrates the three primary deep-linking patterns I’ve observed in my research.
Figure 2—Three primary deep-linking patterns
These three deep-linking patterns articulate distinct user needs for a deep link and, in some cases, might indicate that there is a better solution for addressing the need than a deep link. In such cases, a deep link would be an intermediate step on the path toward creating a more meaningfully integrated set of applications. Let’s dive into each of these deep-linking patterns individually.
Pattern 1
In Pattern 1, users transition bidirectionally between Application A and Application B to compare the same data in two different applications. They might simply need to verify that the data are accurate and consistent, so the directionality of such cross-application inspections might not be important to them. While a deep link would let users go directly from a section in one application to a relevant section in another application—without locating a bookmark for the destination application or laboriously typing in a Web address to view the relevant page—a deep link would be only an intermediate solution in this case.
The real issue is the distinct, underlying databases that support the two applications. Users pay the price for this lack of integration by manually inspecting, editing, and updating records in both applications. The solution should be a single backend system that supports a shared customer record. (See Platform UX, Part I for a description of the user experience of shared data.) One important benefit of exploring user needs around cross-application workflows is the ability to reveal opportunities for changing the platform or architecture of a backend system to better align with user needs. In this example, it is clear that a deep link would be a stop-gap measure on the way to true integration by sharing data on the backend.
Pattern 2
In Pattern 2, users express a need to go from information in Application A to an associated action in Application B. This need is common in situations where users rely on reports or dashboards to make decisions that result in actions. Possible actions might include increasing the budget for a particular service, launching a specific type of advertising effort, or selecting particular types of inventory for discounting.
In this case, situating the information in close proximity to the point where the user decides to take an action helps facilitate the user’s work. Users benefit enormously when their decision-making context provides the relevant information. In this case, the deep link is unidirectional because the user has expressed a need to evaluate information before going to Application B where this evaluation would culminate in an action. A truly integrated platform would dispense with the deep link completely and, instead, would provide recommendations on what actions to take based on the information in a report or on a dashboard. However, a deep link would be an acceptable intermediate strategy along the path toward integration.
Pattern 3
In Pattern 3, transitions between Application A and Application B let users more easily view two different types of data. Such transitions support their gaining a more comprehensive view of the available information by connecting two different types of data that are necessary to convey a full story to the user. While deep links would be an acceptable intermediate strategy for providing the appropriate context to users, an advanced integration strategy would more meaningfully combine those two different types of data into an integrated report or dashboard that would let users view the data in a single space.
Putting It All Together
Now that you’ve gathered user needs and identified patterns across your sample of users, construct a table similar to Table 2 to share this data with your stakeholders. Your table should describe the originating application, destination application, whether deep links should be bidirectional or unidirectional, whether the destination application should open in a new tab or the same tab, the reason users need a deep link, and how you plan to measure the success of your integration efforts. Table 2 shows the information you should give to your team to influence the architecture of deep links.
Table 2—An integration roadmap for deep linking
Originating Application
Destination Application
Directionality
Application Opens In
Deep-Link Rationale
Success Criteria
Application A
Application B
Unidirectional
New tab
Explicitly linking information to an associated action
Quantitative: X% of active users are engaging with deep linking.
Qualitative: Users no longer rely on bookmarks or typing Web addresses to make cross-application transitions.
Application C
Application D
Bidirectional
Same tab
Explicitly linking two different types of data to get a complete story
Quantitative: X% of active users are engaging with deep linking.
Qualitative: Users no longer rely on bookmarks or typing Web addresses to make cross-application transitions.
Your roadmap should explicitly articulate deep-link mechanics such as directionality, the rationale for having a deep link, and the success criteria for each deep-link candidate. Mapping these elements is necessary to ensure that you fully support user needs and the solution aligns with the problem you’re solving.
While deep links might be just an intermediate step on the path toward more meaningful integration, providing them can have a profound impact on the experience your users have with your software. Deep links communicate that your organization recognizes and responds to user needs. Deep links can be a component of your integration strategy. When you create them with the right intent, they can facilitate cross-application work by providing context and continuity to your users.
from UXmatters https://www.uxmatters.com/mt/archives/2019/02/platform-ux-facilitating-cross-application-workflows-with-deep-linking.php
A weekly selection of design links, brought to you by your friends at the UX Collective.
The what → how → why cycle of every new technology wave › Every time a new trend starts to get traction amongst designers and devs — chatbots, artificial intelligence, design sprints, augmented reality, responsive design, react native, hamburger menus, design thinking, you name it — the same pattern happens.
Flow: animate Sketch designs in seconds and export production ready
Recordit: simple screen recording tool with GIF and Twitter support
JAM Stack: client-side Javascript, reusable APIs, and prebuilt markup
Forms ID: privacy-centric Google Forms alternative
Design is: Google’s monthly speaker series on the future of creativity
A year ago
Leonardo Da Vinci was the best UX Designer in history › Was he ahead of his time? Was he one of a kind? I love him and his passion to create the most beautiful and delightful things. And not only that… he was the first UX Designer that ever lived. Let’s break it down. By Flavio Lamenza
We believe designers are thinkers as much as they are makers. So we created the design newsletter we have always wanted to receive.
from UX Collective – Medium https://uxdesign.cc/technology-waves-evil-a-b-testing-font-metrics-and-more-ux-links-this-week-e125e9182f05?source=rss—-138adf9c44c—4
“I want to debunk the myth that originality requires extreme risk taking and persuade you that originals are actually far more ordinary than we realize.” — Adam Grant, Originals
Hi readers. Allow me to introduce myself: I’m Steph. I’m an indie maker. I also lead a remote team of a couple dozen as the Head of Publications at Toptal. On top of that, I’m a self-taught developer, a woman, and identify with many more things.
As I continue to tackle all of these in tandem, I often have people asking how I manage it all. Although it’s not a walk in the park, I believe that most people limit the dimension of what they think is possible and ultimately, limiting beliefs become more of a blocker than actual bandwidth.
Moreover, I’ve always found it strange how people like to put things neatly into boxes or associate with a single label. I think that we can and should explore a multitude of things in life and am writing this article to showcase that being a maker and having a full-time job is not only possible, but also that diversifying your available opportunities can keep you more agile, realistic, and sustainably committed.
Before jumping in, I should clarify that these views are my own and don’t necessarily represent the views of Toptal.
TL;DR
There are three key concepts that I want to tackle in this piece. The first is for those who think that they don’t have enough time and why I feel this notion is often misplaced. The second is to highlight the benefits of sticking with a job and why successful people are best at risk mitigation, not maximization. And finally, the third will isolate some improvements that I think we can all make in our approach to thinking — moving past just indie making and working full-time, these concepts will hopefully help you optimize within a bigger box or perhaps remove the box entirely.
1. “I don’t have enough time”
The average American works 8.8 hours, born out of the industrial revolution and carried through to the twenty-first century out of routine, rather than active consideration. Robert Owen crafted the saying “Eight hours labour, eight hours recreation, eight hours rest.”, in an effort to have people work reasonable hours, while still running factories efficiently.
Despite the world and workforce changing dramatically, this concept of “work time” and “me time” persists today. I’m not here to dispute the 40h model (there are already too many resources for that — who hasn’t heard of the 4h work week?), but instead dispute the perception of “me time”.
For many people, a long day of work means that they are entitled to this “me time” and have designed this “me time” to be as distinct from “work time” as possible. For many, it looks a lot like this: ~Netflix and chill~.
But what if we stopped imaging “me time” as relaxation time, but instead exactly as it is titled — time to focus on yourself and align with your goals. If you need rest, then rest. But if your goal is to one day become an entrepreneur, a significant portion of “me time” should be invested in getting there since it won’t happen on its own. “Me time” shouldn’t just be non-tiring activity, but anything that helps an individual get to the future state that they wish to be in.
With approximately 16 hours of the day allocated to work and sleep, every individual has approximately 8 hours to allocate to “me time” and if used appropriately, a lot can be achieved in that nearly 3000 hours each year.
Sleep, commute, work, repeat.
“Most people overestimate what they can do in a day, but underestimate what they can do in a year.”
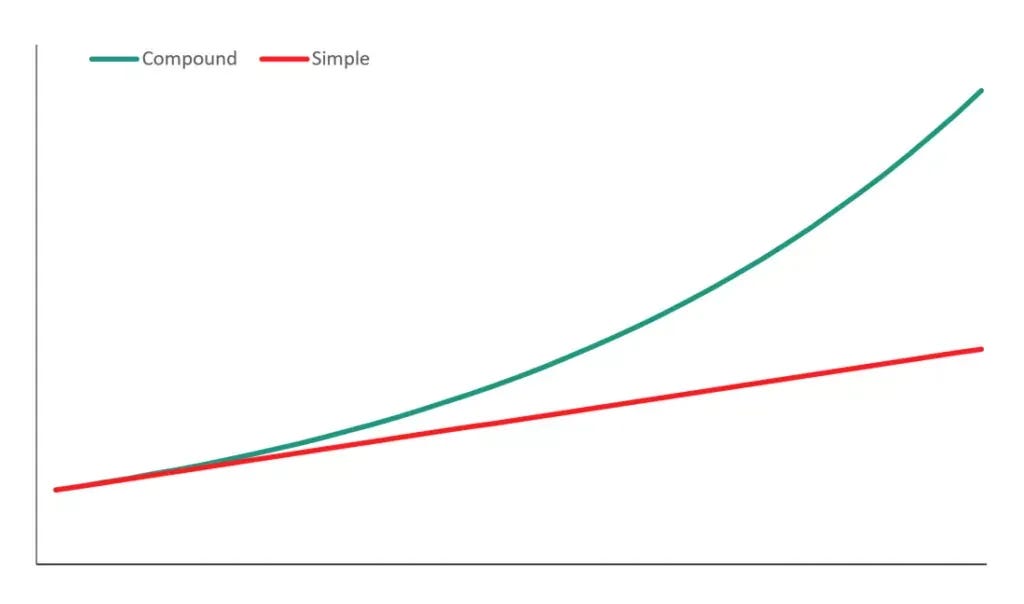
There is also a misconception that in order to build a sustainable business, you need to spend an inordinate amount of time to get there. While it’s true that a lot of effort needs to be delivered, what matters the most is the consistent effort over time. Most people undervalue this concept of compound interest.
The power of compound interest
Take a look at the following equations:
1.0¹³⁶⁵ = 37.8
1.1⁰³⁰ = 17.5
Consistently improving your business (or life) by 1% every day for a year is double as impactful improving by 10% each day for a month. Consistency plus compounding is powerful.
“If everything is a priority, then nothing is a priority.”
I think that most people operate in life by either not clearly identifying priorities or considering everything one. While I believe in ambition, one key step in being successful is identifying core priorities and eliminating the noise that falls outside of that.
Core priorities are dynamic and can change over time, but I think that you can’t really have more than 3 core foci at a given time.
Past setting these focal points, it’s about changing behavior to live by them. Once again, if most people were to objectively reflect on how they’re spending their time, they would get something like this:
A typical day.
For me, this is how my personal priorities have transformed over time:
2017: Work, Travel, Relationship
2018: Work, Learning to code, Building Side Projects
2019: Work, Scaling Side Projects, Sharing Ideas (Writing, Speaking)
In order to sustain a full-time job and creating projects, I’ve had to remove distractions. For example, I don’t watch TV. I don’t commute. I am currently not in a relationship. These were all active choices.
Of course, some of these things will be temporary (ex: relationships), but I’m also mindful of what I’m reintroducing into my life and whether it’ll contribute, take away from, or become one of my north stars.
I think this concept can also be thought of as tiered time investments. With anything you do, if it contributes to your north star, consider it a Tier 1 investment. For something that doesn’t contribute to your growth at all, perhaps label it as a Tier 4. It doesn’t mean that you can’t spend time across tiers, but the amount of time that you spend across each should be reflective of how much you care about them.
Example (this will be an independent exercise for anyone):
2. The benefits of keeping your job
Hopefully the previous section helped convince you that you have enough time to work full-time while creating side projects, or rather, fit more things into your life if you align your values → priorities → behaviours. In this section, I hope to convey why keeping your full-time job can be a beautiful thing.
Getting paid to learn
“Some workplaces are definitely broken, but the entire workforce isn’t.”
I often hear people say things like “I can’t wait to get out”, referring to quitting their jobs and eventually being their own boss. This is not a problem with them having a full-time job, but the particular job they’re working at or perhaps the particular person who they’re reporting to.
All people should strive to find work that is empowering, motivating, and allows them to grow in some dimension. Larger organizations practically guarantee that﹣it’s rare that you are the smartest person in the room and you certainly will never be the most competent person in the room across every dimension.
Working in my “day job” allows me to continuously learn from people who are smarter than me, and get paid for it. I’m also faced with challenges that I simply wouldn’t encounter with my side projects, and I often need to learn how to solve these challenges alongside others. I encourage people to intentionally design their career path to take on new skills ranging from hard to soft. Both will be important if you eventually decide to go off on your own in the future.
With the workforce becoming more dynamic, the ability to learn from others while working on your own projects in tandem is a development that many people are taking. In fact, I polled several hundred on Twitter, and found that a significant number of people are doing exactly this.
@stephsmithio@anthilemoon@makermag I love my job, so I have no reason to quit really. It also allows me experiment and really take my time with what I’m making 🙂
Outside of learning, keeping a FT job has other tangible benefits which may help you build a more sustainable side project.
Out of personal experience, I’ve found that keeping my job and side projects separate has allowed me to still find independent joy in both. Whenever I switch from one context to the other, particularly with making, it’s still “fun”.
@stephsmithio@makermag@doorbell_io Tough balancing act, and always careful to avoid burnout. I always had to remember that I’m doing the side projects for fun, so if it isn’t fun don’t force it. I’m lucky in that it was still able to grow, despite long period of borderline neglect.
I think this is particularly due to the fact that in its current state, making is not my lifeline. I hope that someday it does become something much more substantial, but for now, I can make decisions regarding my projects that aren’t influenced by the need to make cash immediately.
More importantly, I can focus on expressing myself through projects I truly care about, instead of focusing on what may generate $, and through this process, I stay close to my values. In other words, I can focus on creating value, instead of specifically on capturing it, similar to how Gumroad’s founder Sahil Lavingia pivoted to do this or how Warby Parker’s founders ensured that money would not trump their values:
“We were four friends before we started, and we made a commitment that dealing with each other fairly was more important than success.” — Originals, Adam Grant
Tied to the above, I can ditch a project or think rationally when I realize that a project doesn’t offer any value, nor do I need to take VC money or tend to investors that I don’t believe in.
“Having a sense of security in one realm gives us the freedom to be original in another. By covering our bases financially, we escape the pressure to publish half-baked books, sell shoddy art, or launch untested businesses.” — Originals, Adam Grant
Finally, I can invest the proper amount of time in skill acquisition. I liken this to the concept of how public stocks are focused less on creating long-term value through innovation and instead on next quarter’s revenue numbers. I am a private stock that can focus on myself and my skills, with the intention of building them for the long-haul.
In other words, the clear distinction between my expression and creativity is separated from my lifeline and I think that’s helpful in making more effective decisions.
Pilot a lot and then bet it all
“The word entrepreneur, as it was coined by economist Richard Cantillon, literally means “bearer of risk.” — Originals, Adam Grant
There is a common misconception that entrepreneurs are all “risk-takers” and that you need to go “all in” to be successful. Both of these are both proven false in Adam Grant’s book Originals; that entrepreneurs are not necessarily risk takers, but instead better at evaluating risk and hedging their bets.
“When Pierre Omidyar built eBay, it was just a hobby; he kept working as a programmer for the next nine months, only leaving after his online marketplace was netting him more money than his job. “The best entrepreneurs are not risk maximizers,” Endeavor co-founder and CEO Linda Rottenberg observes based on decades of experience training many of the world’s great entrepreneurs. “They take the risk out of risk-taking.”” — Originals, Adam Grant
Grant also captures another study by Joseph Raffiee and Jie Feng which tracked the following question from 1994 to 2008, across over 5 thousand Americans: “When people start a business, are they better off keeping or quitting their day jobs?”.
The result? They found that those leaving their jobs were doing so not out of financial need, but instead out of sheer confidence. However, those that were more unsure — more risk-averse — were the ones that had 33% lower odds of failure.
Another study identified that entrepreneurs whose companies topped Fast Company’s most innovative lists also tended to stick with their day jobs, including famous entrepreneurs Phil Knight (Nike), Steve Wozniak (Apple), and Google Founders Larry Page and Sergey Brin.
Knight worked as an accountant for 5 years while selling shoes from his trunk, Wozniak kept working at HP, and the Googlers continued on with their PhDs at Stanford. These are just a few of the originals in the book-Grant also cites similar stories ranging from Brian May studying astrophysics before going all-in with Queen, John Legend working as a management consultant even after releasing his first album, Spanx founder Sara Blakely selling fax machines as she prototyped and scaled her company to eventually become the world’s youngest self-made billionaire, and famous author Stephen King working as a janitor, teacher, and gas station attendant for 7 years after his first story was published.
We all have multiple passions and I think life is about making strategic transitions when it makes sense. There’s no need to cut from one scene to another immediately. People may think it’s cool to be a risk taker, but it’s much cooler to come out on the other side successful.
3. Restructuring your way of thinking
Regardless of whether you choose to work full-time while exploring side projects, I think we can all be a little more effective at opening our minds to different ways of thinking. This section will touch on some of the ways that I think we can stop limiting ourselves and others.
No more dichotomies
People love putting things into boxes. You’ll hear people use nouns or adjectives as definitive labels all the time:
Technical or not technical
Happy or sad
Employee or entrepreneur
See where I’m going with this? Despite these labels, I believe that almost everything can be represented in some sort of curve; particularly with skill acquisition. For example, when do you really “become” a programmer?
Truly creative thinkers stop thinking in binary and instead are able to internalize the concept of these curves. They view things as a ramp or staircase or Venn diagram, NOT as a series of boxes. When you remove dichotomies, you are able to more clearly see other options, like slowly ramping up your time investment in your side gigs instead of quitting immediately.
Optimizing your life
I think that it’s very naïve for anyone to assume that they’re working at their global maximum in terms of effectiveness. The truth is that we all have room for improvement both in terms of being faster/leaner, but also in making better decisions to remove work that shouldn’t be on our plate in the first place.
Should you choose to work on multiple things, make sure that you have independent KPIs for all of them. People tend to do this with businesses, but the concept is so rare in our personal lives. Are you able to quantify how much time you’ve invested in yourself over the past year? Most people wouldn’t be able to.
If you don’t have KPIs for both, the one without clear KPIs will naturally slip to the wayside or not receive the amount of attention it deserves.
I also think it’s important to understand the concept of “meta work”. My definition of meta work is the following: “If you did that activity continuously for a year, would your life be any different?”
Let me elaborate.
If I answered emails every day for the next year, would my life have changed in any significant way? In other words, would I have moved from A to B? The answer is no.
The same thing is true for things like laundry or buying groceries or doing your nails. Oh yes, Netflix fits neatly in there too.
There’s a second type of task which I label as absolute tasks. If done consistently, you would likely see your skillset or life change in a material way. For example: if you read every day for a year, your knowledge set, creativity, and reading speed would all likely improve. If you exercised every day, your health would undoubtedly improve. Similarly, if you dedicated 1 hour every day to learn to code, you would have an entirely new skillset by the end of the year.
While meta tasks are unavoidable in life, make sure that your goals in life are not meta — they need to be absolute. When you create your to-do list for the day, make sure at least one thing is absolute (remember: 1.0¹³⁶⁵ = 37.8). And of course, when you can: automate as many of the meta tasks as you can. Meta tasks in many ways can be synonymous with distractions unless they bring some sort of independent joy to your life.
The myth of overnight success
Finally, I want to address one last misconception: there is no such thing as overnight success. This misconception is derived from the way the media operates.
TechCrunch will never write about how X person spent Y years bootstrapping a sustainable non-unicorn that abides by its values and respects people’s privacy. Outliers are flashy, but they are still outliers.
Up until a few years ago, I never truly understood this concept of a continuous climb. I thought that every successful person who said that it took a lot of work and hard effort was just self-justifying their luck.
“When we marvel at the original individuals who fuel creativity and drive change in the world, we tend to assume they’re cut from a different cloth.” — Adam Grant, Originals
The reality is that building anything of value takes time. Sure, it may take longer for you to build while working full-time, but that’s okay.
If you currently work full-time, don’t put yourself into a box and instead, just start working towards ideas that you find interesting. The perfect idea will never come, so I encourage everyone to start working even 1 hour per week on ideas they find interesting and ramp that up until you’re in a place where it makes sense to take them on full-time. The mental clarity of separating your lifeline (your job) from your projects may be the most healthy and thoughtful approach.
Remember, there is no moment that you become an entrepreneur, so there is no need to quit your job just to define yourself as one.
the augmented reality handbook everything you need to know about augmentedreality Augmented Reality brings with it a set of challenges that are …
from Google Alert https://www.google.com/url?rct=j&sa=t&url=http://www.thepost.news/the_augmented_reality_handbook_everything_you_need_to_know_about_augmented_reality.pdf&ct=ga&cd=CAIyGmJhYjllOWZjNzViYWJhMTA6Y29tOmVuOlVT&usg=AFQjCNEH96OH77mjiFGYNjJrGgEeT18Vuw
Machine intelligence doesn’t automatically lead to smarter user experience if product designers and machine learning experts don’t talk the same language.
The language and concepts of machine learning are far from intuitive. And user experience design requires an understanding of how people think and behave, simultaneously taking into account the irrationality of human behavior and the messiness of everyday life.
Because of the different skills these two disciplines require, it’s normal to see user experience designers and machine learning experts work in their own separate silos even though they’re building the same product. Often, experts from both fields are not familiar with each other’s methods and tools and so are unable to grasp what can be achieved by combining experience design with machine learning. To break these professional silos, the product team needs to make a steadfast and conscious effort, but how to get started?
Here are four pivotal principles for finding an efficient and fruitful way to combine the best product design methods with the pragmatic applications of machine learning:
1. Develop a shared language
The product vision, essential user experience issues, and business goals need to be shared and understood by the whole team. You can create an intelligent, truly meaningful user experience only if product design and machine learning development methods feed each other through common language and shared concepts.
User experience designers and machine learning experts should join forces to create a common product development blueprint that includes user interfaces and data pipelines. The co-created product blueprint grounds your team’s product planning and decisions concretely to the reality of user experience: how every design decision and machine learning solution affects how the user experiences the product. A great catalyst for cross-pollination of product goals, design ideas, and machine learning concepts is to get the experts on both fields to work in the same space side-by-side.
Moreover, to build a common language, it’s important for the product team to answer two key questions together. The first question is: “Why?” Why do we choose this user experience design or machine learning solution for this particular use case? The second question is “What’s the goal?” What is the rationale and what is expected to happen when the team focuses on tuning a user experience design detail or optimizing a machine learning model. For example, everyone in the team should be able to perceive why making the copy text more appealing in a marketing notification can yield more immediate impact on user engagement than optimizing the machine learning model to produce more precise personalized content recommendations.
2. Focus on the use case
If you’re building a consumer-facing product, the most important thing is not the technology but the user experience and business goal you wish to achieve.
Map out and crystallize your use case. For example, if you’re creating a personalized onboarding for a news app, the user experience designers and machine learning experts should together draft out and design the actual use flow for onboarding. This allows the whole team to recognize the key points where machine learning could enhance user experience and vice versa. Concrete designs, including input from designers, data engineers, and data scientists, help you set realistic expectations and goals for the first product iteration.
A thorough understanding of the use case enables the team to determine a proper key performance indicator (KPI) for user experience development that is aligned with the metrics of machine learning. For example, if you’re building an AI-powered personalized news notification feature for a news app, your aim is to save users time by sending automated notifications. And you want to gauge if users are happy with the notifications appearing on their lock screen, even though they wouldn’t open the app itself at all. In this case, it’s essential to measure if the users keep the new smart notification feature on and thus continuously receive personalized news alerts directly on their lock screen.
3. Combine qualitative and quantitative data
“Big data” is not always needed to use machine learning effectively. Historical data can even become a hindrance if you believe the answers to the open-ended user experience design questions can be found in quantitative data from the past. Additionally, there are technologies like online learning that don’t necessarily require troves of historical data to get started.
To understand the effects of combining user experience design and machine learning solutions, both qualitative and quantitative data are important. Use qualitative research methods such as user interviews, questionnaires, and user testing to gauge how your users experience the product features. Qualitative data offers clarity on how users think and feel, and quantitative data tells you how people actually behave with your product. Your whole team should assess the results of qualitative studies.
When building a new product or feature, you might bump into many unexpected factors affecting user experience and machine learning development. For example, is a selected data point capturing the real user behavior or intention? Is the feedback loop ineffective for producing meaningful data because the connected user interface feature is not accessible or visible to the user? The combination of qualitative and quantitative methods gives you a wider perspective to answer such questions.
Also, interviews and user tests bring the data alive. They highlight the actual connections between your users and how they are interpreted by your system. In-depth user understanding is essential in picking up the signal from the noise in your data flow. Combining insights based on qualitative and quantitative data enables both user experience designers and machine learning experts to better understand the product as an ecosystem that is part of people’s everyday lives. Everyone on the team becomes a product expert.
4. Confirm your choices with real data in a real-life setting
Does it make sense from a user’s perspective that your smart assistant can independently order pizza, manage your bank account, or book your next vacation flights without you needing to ask it to? How do we make sure that machine intelligence is really used to create more fluent and comprehensible user experiences?
By setting up a working end-to-end solution, you can see how all the parts of user experience and machine learning fit together in real life. A minimum viable product, including working data pipelines and machine learning models, makes it easier to iterate the product together with the whole team and also gives you direct feedback from users through user testing or beta testing. All the feedback should be shared, discussed, and analyzed with the whole team. This lets you see how your product works in the real world so you can identify the most critical things for further development.
When user experience designers and machine learning experts share understanding about product development issues, product iteration is faster and more productive. In the process, your data engineers and data scientists get new insights on how machine learning can be used to understand actual human behavior that doesn’t fit directly into a mathematical formula, data model, or machine learning solution. In turn, user experience designers become more aware of the pragmatic possibilities of machine learning: how and when it can be used to improve user experience in the most impactful way. Collaborating becomes a clear competitive advantage.
Jarno M. Koponen is Head of AI and Personalization at Finnish media house Yle. He creates smart human-centered products and personalized experiences by combining UX design and AI. He has previously written articles on UX, AI, personalization, and machine learning for TechCrunch.
from “artificial intelligence” – Google News https://venturebeat.com/2019/02/09/ui-ai-combine-user-experience-design-with-machine-learning-to-build-smarter-products/