Artificial intelligence offers us an opportunity to amplify service and the integration of technology in everyday lives many times over. But until very recently, there remained a significant barrier in how sophisticated the technology could be. Without a complete understanding of emotion in voice and how AI can capture and measure it, inanimate assistants (voice assistants, smart cars, robots and all AI with speech recognition capabilities) would continue to lack key components of a personality. This barrier makes it difficult for an AI assistant to fully understand and engage with a human operator the same way a human assistant would.
This is starting to change. Rapid advances in technology are enabling engineers to program these voice assistants with a better understanding of the emotions in someone’s voice and the behaviors associated with those emotions. The better we understand these nuances, the more agile and emotionally intelligent our AI systems will become.
A vast array of signals
Humans are more than just “happy”, “sad” or “angry”. We are a culmination of dozens of emotions across a spectrum represented by words, actions, and tones. It’s at times difficult for a human to pick up on all of these cues in conversation, let alone a machine.
But with the right approach and a clear map of how emotions are experienced, it is possible to start teaching these machines how torecognize such signals. The different shades of human emotion can be visualized according to the following graphic:
Parrott, W. (2001), Emotions in Social Psychology, Psychology Press, Philadelphia
The result is more than 50 individual emotionscategorized under love, joy, surprise, anger, sadness, and fear. Many of these emotions imply specific behaviors and are highly situational – meaning it is very difficult to differentiate. That’s why it’s so important for emotion AI to recognize both sets of patterns when assigning an emotional state to a human operator.
Recognizing emotions in voice
Regardless of how advanced technology has become, it is still in the early stages. Chatbots, voice assistants, and automated service interfaces frequently lack the ability to recognize when you are angry or upset, and that gap has kept AI from filling a more substantial role in things like customer service and sales.
The problem is that words—the part of the conversation that AI can quantify and evaluate—aren’t enough. It’s less about what we say and more about how we say it. Studies have been conducted showing that the tone or intonation of your voice is far more indicative of your mood and mental state than the words you say.
Emotional prosody, or the tone of voice in speech, can be conveyed in a number of ways: the volume, speed, timbre, pitch, or the pauses used in the speech. Consider how you can recognize when someone is being sarcastic. It’s not the words—it’s the elongation of certain words and the general tone of the statement. Even further are the different ways in which prosody impacts speech: the words, phrases, and clauses implemented, and even the non-linguistic sounds that accompany speech.
To better understand the data in speech that isn’t related to linguistic or semantic information, there isbehavior signal processing, a new field of technology that is designed to detect information encoded in human voice. Combining the best of AI engineering technology and behavioral science, this new field aims to fully interpret human interactions and the baselines of communication in voice.
It works by gathering a range of behavior signals – some overt and others less so. It draws on emotions, behaviors and perceived thoughts, ideas and beliefs drawn from data in speech, text, and metadata about the user to identify emotional states. Humans are not 0’s and 1’s. Their emotions are encoded from dozens of diverse sources. This requires a system that can observe, communicate and evaluate data from several sources simultaneously and respond in kind.
Designing better interfaces between machines and humans
Already, businesses are leveraging the insights provided by this new technology to better evaluate and utilize unstructured data in their organizations. Call recordings, chat histories, and support tickets are now providing a foundation upon which large organizations can better understand what their customers are feeling when they reach out and how those emotions ultimately influenced their decisions.
This opens a new avenue to understand the context of customer interactions. Historically, customers and prospects are evaluated through the prism of a human agent. Whether customer service or sales, the individual would interact with them and then make notes on how they are feeling or responding. This would need to be written in a structured format so it could be further evaluated in the future.
Today’s AI systems are making it possible to reference primary data – the actual responses given by customers and prospects to better understand what they need and why they need it. This level of insight is exponentially more powerful than it has been in the past and continues to evolve.
As a result of this, the future is bright for AI assistants. Not only will businesses be better able to understand and respond to consumer needs; so too will the machines already implemented in homes and offices around the globe. Smartphone and personal voice assistant devices will develop a more nuanced understanding of the context and behavior driving the response of the human operator.
The shades of emotion in the human voice are being decoded and mapped in a way that has never been done before, and it’s providing the foundation for the next generation of emotionally intelligent AI. This is the future of human and machine interaction and it is developing faster than ever before.
This story by Alex Potamianos is republished fromTechTalks, the blog that explores how technology is solving problems… and creating new ones. Like them onFacebookhere and follow them on Twitter.
TNW Conference 2019 is coming! Check out our glorious new location, inspiring line-up of speakers and activities, and how to be a part of this annual tech extravaganza byclicking here.
from The Next Web https://thenextweb.com/syndication/2019/04/17/emotionally-intelligent-ai-will-respond-to-how-you-feel/
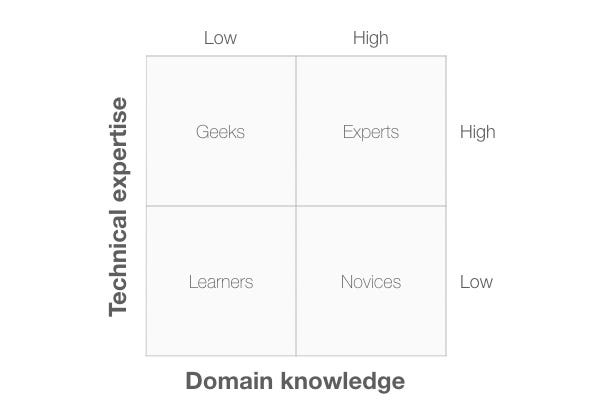
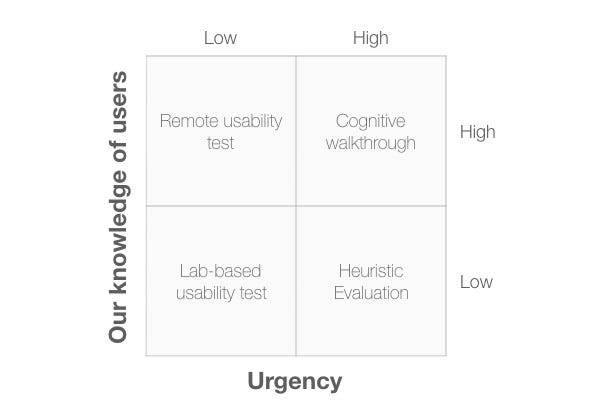
Watching how people interact with an interface tells you a lot about what works and what needs improvement.
And while observing behavior is essential for understanding the user experience, it’s not enough.
Just because a product does what it should, is priced right, and is reliable, doesn’t mean it provides a good user experience.
Users can think the experience is too complicated or difficult. For example, a lot of B2B software products, like expense reporting apps, meet the organization’s needs and are reliable but have a lot of steps and confusing jargon that make them quite unpleasant.
To have a good UX means understanding and measuring actions AND attitudes.
It’s about function, but also about feeling. Attitude not only describes how people feel while using an interface or interacting with a product, but it may also be the explanation for WHY people will or won’t use a product or app in the future.
If you want to understand and predict user behavior, you need to understand attitudes. But what is an attitude?
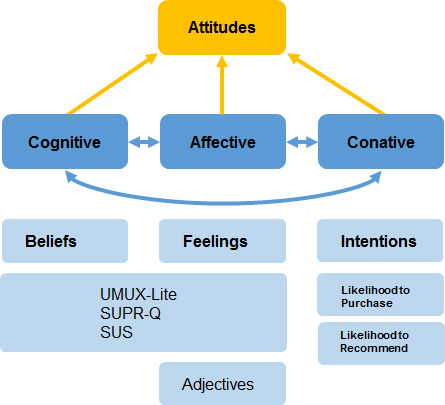
Three Parts to Attitude
An attitude is a disposition to respond favorably or unfavorably to a person, product, organization, or experience. People have positive and negative feelings and ideas about companies, websites, and experiences.
But similar to the concepts of UX and usability, attitude can be thought of as a multidimensional construct with related components. For decades, researchers in the social sciences have been modeling and measuring attitudes. While there is debate on how to best decompose attitude, one influential model is the tripartite model of attitude, also called the ABC model. Under this model, attitude is composed of three parts: cognitive, affective, and conative. It’s also referred to as affect, behavior, and cognition (hence ABC).
We can illustrate this concept using three things people are familiar with and likely have favorable and unfavorable attitudes toward: snakes and two brands (Apple and Facebook).
Cognitive: Beliefs people have about a brand, interface, or experience.
Snakes control the rodent population.
Apple makes innovative products.
Apple’s products are very expensive.
Facebook connects me with friends and family.
Facebook presents ads based on my profile.
Affective: Feelings toward a brand, product, interface, or experience.
Being around snakes make me feel tense.
Apple products make the world a better place.
Apple wants to squeeze as much money from me as possible.
Facebook makes me feel closer to my family.
Facebook is unfairly using my data.
Conative (Behavior): What people intend to do. Sometimes this is called behavior; I think that confuses it with actual behavior, but it does help with the ABC acronym.
I will pick up a snake.
I’m going to recommend my mom get the new iPhone.
I’m not going to purchase another MacBook.
I will post photos of our vacation on Facebook tonight.
I’m going to boycott Facebook this month.
Under this tripartite model, attitudes can be thought of as beliefs, feelings, and intentions (see Figure 1). Each of these aspects of attitude typically correlates with the others. Positive beliefs about an experience or product tend to go along with positive attitudes and favorable intentions. But the correlation isn’t always high, so it can be helpful to separate them and understand how each of these components may lead to different behaviors.
For example, people can believe that Apple’s products are expensive (negative belief), think Apple cares about them (positive feeling), and intend to purchase and recommend its products (positive intention).
Measuring Attitudes
We can’t directly observe attitudes. Instead, we have to infer attitudes from what we can measure. While there are ways to measure nonverbal behavior (such as heart rate when in the presence of snakes), it’s usually a lot easier (and often as effective) to use self-reported measures. Rating scales from standardized questionnaires are the most common method. For the user experience, this can be the items on the SUS, SUPR-Q, UMUX-Lite, Net Promoter Score, and adjective lists (such as those in the Microsoft Desirability Toolkit). Here are ways to think about measuring each of the aspects of attitude.
Cognitive: Assess what users’ beliefs are using agree and disagree statements (such as 5-point Likert scales).
Apple’s products are expensive.
iTunes is easy to use. (Part of the SUS and UMUX-Lite)
It is easy to navigate within the Facebook website. (Part of the SUPR-Q)
Overall, the process of purchasing on Facebook Marketplace was very easy–very difficult. (Part of the SEQ)
Affective: Use adjective scales and agree/disagree scales to assess affect (SUPR-Q, SUS, satisfaction, Desirability Toolkit).
The information on Facebook is trustworthy. (SUPR-Q)
You’ll notice the considerable overlap between the use of scales for the cognitive and affective components of attitude—reinforcing their correlated nature.
Conative: Ask about future intent.
How likely are you to recommend Apple to a friend or colleague? (NPS)
I am likely to visit the Facebook website in the future. (SUPR-Q)
Figure 1 shows how to think about these aspects of attitude and how to measure them.
Figure 1: Three components of attitude and how to measure them.
Using Attitude to Predict Behavior
Decomposing attitude into these three parts helps describe the user experience but also may predict behavior. In our earlier analyses, we’ve found that attitudes toward the website user experience (accounting for both beliefs and feelings) predicted future purchasing behavior. There’s evidence that high satisfaction leads to greater levels of loyalty, buying intention, and ultimately buying.
We’ve also found that both beliefs and feelings (SUS) predicted intentions (NPS) (hence the arrows connecting these sub components in Figure 1). The Net Promoter Score (behavior intention) predicted growth in the software industry and correlated with future growth in 11 of 14 industries.
If you want to change behavior you need to understand and measure attitudes. If users find an experience difficult and/or a product expensive or lacking functions (cognitive), it will eventually lead to negative feelings (affect) and reduced intention to use and recommend (conative), and ultimately people will stop purchasing or using (behavior). We’ll explore this connection in a future article.
The actual change in behavior can take time and is affected by factors such as the presence of better alternatives and switching cost. But the story of Quark software may offer a good example of how cognition, affect, and intention combined with new competition led to behavioral change—and the fall of a once dominant product and company.
Summary and Takeaways
In this article, we considered the role of attitude in the user experience:
UX is both actions and attitudes. To understand a user experience, you need to account for both actions and attitudes. You can’t say a user experience is delightful or dreadful from observation alone. You need to understand how people think and feel.
There are three parts to attitude. An influential model of attitude decomposes it into three parts: cognitive, affective, and conative. It’s also called the ABC model (affective, behavioral, and cognitive) and means that attitude is comprised of what people believe (cognitive), how people feel (affective), and what they intend to do (conative/behavioral).
Measure attitude to understand UX. You can use common standardized questionnaires such as the SUS, UMUX-Lite, and SUPR-Q to measure the cognitive and affective components of attitude. Ask about future intent, likelihood to purchase, use, and recommend (Net Promoter Score) to assess the conative/behavioral component of attitude.
Attitude can explain and predict behavior. Understanding what people think and feel can help explain why people act and predict future behavior (such as purchase behavior), continued usage, and growth of products across industries.
from MeasuringU https://measuringu.com/ux-attitudes/
Decentralised Autonomous Organisations (DAOs) are one of the most anticipated applications of blockchain technology. After all, this is the first time in history we homo sapiens had the means to coordinate in a trustless and anonymous way to make collective decisions for a certain cause.
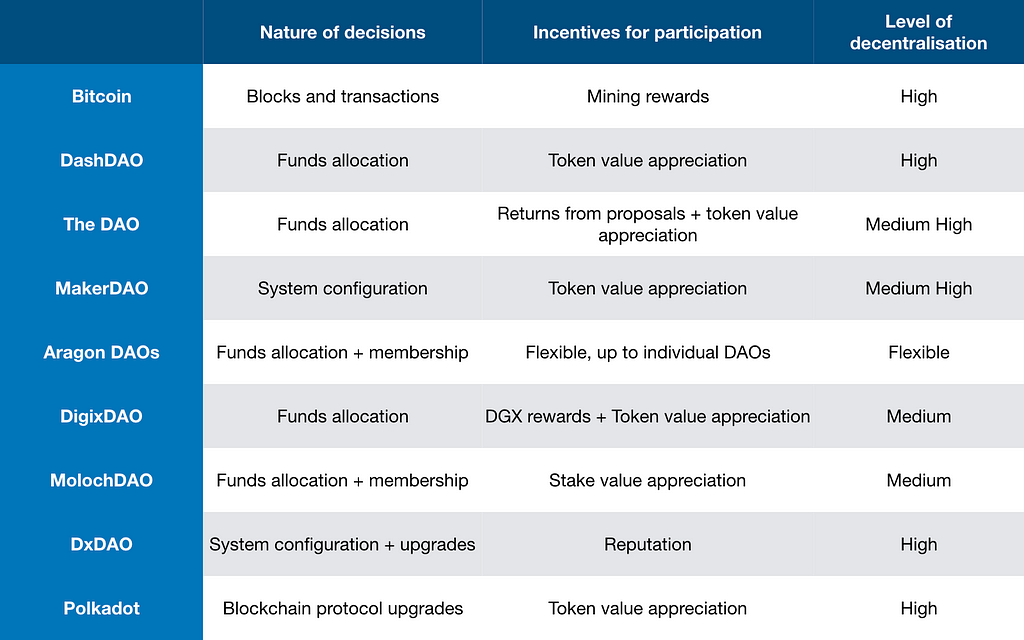
In this article, I will attempt to take you on a walk (be prepared, it’s going to be a long walk) through the most notable DAOs that have ever existed, are already running and are going to launch in the near future. While discussing DAOs, I will categorise them in terms of 3 main properties:
Nature of the decisions to be made
Incentives for participation
Level of decentralisation
Along the way, I will also discuss my opinions about the DAOs, as well as any concerns I have for any of the mechanisms.
Before going on further, it’s necessary to state my definition of a DAO first: to me, a DAO is an organization that is run by people coordinating with each other via a trustless protocol, to make collective decisions for a certain cause.
With that, let’s jump straight into what I believe to be the first DAO ever:
Bitcoin — The Original DAO
Yes, that’s right. Bitcoin was the first DAO ever, at least in my definition. Essentially, its an organisation run by miners and full nodes, coordinating with each other via the Bitcoin protocol, to make collective decisions on what transactions are included and what their order is in the main chain of the Bitcoin blockchain. The cause for this organisation is simple: to secure the Bitcoin network and facilitate transactions on it.
The decisions to be made by the “Bitcoin DAO” are on the relatively low level of the blockchain infrastructure, on the blocks and transactions of the blockchain itself. We could then say that most other blockchains, like Ethereum or Zcash, are essentially DAOs as well. In this article, however, I will mostly talk about DAOs that exist on top of a blockchain, which have more defined purposes. I will call them “meaningful DAOs”. These “meaningful DAOs” inherit the decentralised and trustless properties of their underlying blockchain protocol, and build additional logic on top to serve more “meaningful” purposes.
The incentives for participating in the “Bitcoin DAO”, are mainly the mining rewards. If a miner behaves correctly and diligently produces valid blocks, it gets mining rewards for participating and contributing to the “Bitcoin DAO”. In my opinion, the incentives for participating in a DAO is key to its success. Rationally, participants would only actively contribute to a DAO if they are adequately incentivised to do so. Bitcoin has demonstrated how this simple concept has worked out so well. It’s worth to note that the incentives for contributing to the “Bitcoin DAO” are immediate. No delay, instant gratification.
Bitcoin has a high level of decentralisation. The protocol itself is fully decentralised. It can operate as long as there are participants in the network. In practice, however, we can’t say that it’s fully decentralised. At the time of writing, the top 4 mining pools have more than 50% of the hash rate, which means they could collude and perform a 51% attack to stop specific transactions or reverse their own transactions to double spend. There is also centralisation in the way new upgrades to the Bitcoin protocol are controlled by a few parties.
It might already be obvious to some, but it’s hard to achieve a 100% decentralisation level in practice. Even if the power to create blocks is somehow made highly decentralised, or if protocol upgrades are done via a highly decentralised voting mechanism, security vulnerabilities in the major clients/operating systems, among other things, could still seriously harm the network. As with all other things, reality can never be as perfect as in theory, since assumptions don’t hold. Taking a step back, should we even strive for full decentralisation? That is another whole discussion which I will talk more about in a later section.
Regardless, Bitcoin is still one of the most beautiful things that have happened to humankind. Since the days we all lived in tribes coordinating based on familial trust, humankind has come up with so many concepts and built so many complex systems to try to coordinate among ourselves. However, Bitcoin has given birth to an entirely new way of coordinating among ourselves, where the rules are written and enforced by immutable logic. Bitcoin was the father/mother of all DAOs.
DashDAO — The First “Meaningful” DAO
Originally a fork of Bitcoin, Dash (which was initially called Xcoin and then Darkcoin) went on to introduce an additional DAO element on top of its core blockchain protocol in August 2015: 10% of the block rewards go into a pool to fund proposals to grow the Dash network/ecosystem.
In this DashDAO, anyone can pay 5 Dash to create a proposal to ask for funding. Dash Masternodes (who need to lock at least 1000 Dash as collateral) vote to decide which proposals should or should not get the funding.
The decisions to be made in DashDAO are about how to allocate a pool of funding to real life proposals, to ultimately promote Dash adoption.
The incentive for Dash Masternodes to participate in DashDAO’s voting is the long term appreciation in value of their Dash stash, due to them voting for effective proposals and blocking lousy proposals (hence, save fundings for better proposals).
DashDAO has a high level of decentralisation. Anyone can join or leave as Dash Masternodes, and anyone can get their proposal passed as long as there are Dash Masternodes voting for it.
Being the first DAO that had explicit decision making on top of the blockchain consensus layer, DashDAO has been one of the most, if not the most, active and successful DAO. To date, hundreds of proposals have been passed in DashDAO, ranging from funding development efforts to marketing and community awareness efforts. At the time of writing, there are 31 active proposals up for voting for the next funding release of 5735.52 Dash for May 2019 (You can check them here). Powered by DashDAO, Dash has built a great ecosystem with active communities in multiple countries and payment support in multiple types of services like VPN, mobile top-ups, or even for buying fried chickens!
The DAO — The Infamous DAO
The DAO was one of the most exciting projects in blockchain so far. Started in May 2016, it attempted to create a totally new decentralised business model, where the organisation — The DAO — was collectively run on smart contracts by its token holders who contributed to its token sale. The token holders vote to give funding to proposals that were supposed to generate rewards back to The DAO. The DAO managed to gather a staggering amount of 12.7M Ethers, almost 14% of the Ether supply at the time.
The decisions to be made in The DAO were similar to DashDAO: how to allocate a pool of funding to real life proposals that would eventually give back returns to The DAO.
The incentive for The DAO participants to participate in its voting was the rewards from successful projects as well as the appreciation of their tokens’ value due to the tokens’ potential to generate more rewards. Admittedly, there were a few problems to The DAO’s incentive structure. Firstly, there were no guarantees how the projects funded by The DAO could eventually give rewards back to the token holders. Secondly, the funded projects would need to sell the Ethers for cash, which would temporarily lower the value of the Ethers that are backing The DAO’s token value. This second problem is shared with any DAOs where funds are given to proposals in terms of the tokens backing the financial interests of the DAO’s participants. There were also other problems with The DAO’s structure but that is outside the scope of this article.
The DAO was fairly decentralised. There were Curators who were to check the identity of the people submitting proposals and making sure that the proposals were legal before whitelisting their addresses. This process, as well as how the initial set of Curators was selected, was not entirely decentralised. However, people could be voted in and out of their Curator positions, and anyone who was not happy with the way The DAO was run can just split off from The DAO while retaining their share of the funds and rewards.
All in all, The DAO was an interesting and novel concept that should have been a cool experiment to witness, no matter how it ended. Unfortunately, it ended rather early and un-cooly, without us having witnessed much. There was a vulnerability in The DAO’s code leading to an infamous hack that most readers of this article should have been familiar with.
MakerDAO — The Administrative DAO
Launched on the Ethereum Mainnet on 17th Dec 2017, MakerDAO was created as a DAO to administer the running of its stable coin, Dai, whose value is stable relative to the US Dollar. Dais are generated by locking in some Ethers (or other assets in the future) into Collateralised Debt Positions (CDPs). More details about how Dai works can be read here. In short, the stability of Dai is maintained by a number of feedback mechanisms, implemented as a system of smart contracts on the blockchain.
The decisions to be made in MakerDAO are basically to adjust the configurations of the whole system and to trigger emergency shutdowns when necessary. The configurations to be decided on include parameters of the CDP types, what CDP types to add, as well as the set of Oracles for the Collateral Types’ price feeds, among others. The aforementioned emergency shutdown is a global settlement of the whole system, which should be triggered when there is a black swan event that threatens the proper functioning of the whole system.
The main incentive for the participants in MakerDAO — the MKR token holders — to participate in its governance process is the appreciation in value of the MKR token when the Dai Stablecoin System functions well and grows over time. In the Dai Stablecoin System, the CDP creators will have to pay a Stability Fees (or Dai Savings Rate when Multi-Collateral Dai is out) in MKR, which would be burned, indirectly increasing the value of MKR. Admittedly, this incentive mechanism is more of a long term process, which does not incentivise participation as much as how Bitcoin’s instant gratification does. Furthermore, there is a free-riding problem, whereby the lazy MKR token holders can still enjoy the full benefits of the appreciation in MKR value without having to spend any time or efforts in the governance process. This problem is prevalent in most DAOs.
On the flip side, there is a case for not having to incentivise voting that much. After all, having fewer informed and caring voters might be better than having more but less informed voters. This is another whole debate which is outside the scope of this article.
MakerDAO is fairly decentralised. In theory, all decisions in MakerDAO are done purely via MKR voting. However, MKR’s distribution is not the most decentralised. Moreover, it is hard to configure such a complex system purely via decentralised decision making. Many of the configuration changes, like the Stability Fees adjustments, need to be researched on and proposed by the Maker Foundation. It might be too crazy if everyone can freely choose all config values and the result would be the weighted averages.
That brings us to an opinion that has been raised by Vitalik, among others: fully decentralised, tightly coupled on-chain governance is overrated. The current human coordination mechanisms have evolved, via our cultures, through hundreds of thousands of years. Compared to that, the new way for decentralised human coordination via blockchain technology and DAOs is not even a new-born. Even though DAOs and decentralised voting are exciting breakthroughs, I think it might be too early to just rely on them 100% right away. A combination of on-chain voting, informal off-chain consensus and the core development team’s inputs might be more ideal, at least for now.
Properties of the different DAOs — Teaser
Aragon DAOs — The Plug-And-Play DAOs
Aragon: we heard DAOs are cool, so we made a framework for everyone to create their own DAOs in a few clicks.
Thanks to Aragon, you can now create a simple DAO easily in just a few steps. In such an Aragon DAO, you can assign stakes to a set of initial members, vote on stakes for new members, vote to release funds from your DAO, or just have a non-binding vote on anything.
For each of those Aragon DAOs, you are free to define the purpose of your own DAO, the types of decisions to be made and the incentives to participate in your DAO. It could be used to run a non-profit organisation, or as a way to manage family spending with your partner, or could just be your own personal DAO. The level of decentralisation is also up to how you set up your Aragon DAO. You can head over to this website to explore all the current Aragon DAOs out there.
*Disclaimer: I am a Digix employee and was majorly involved in the design and implementation of DigixDAO. However, I have tried my best to remain unbiased throughout this article.
The decisions to be made in DigixDAO are similar to DashDAO: how to allocate a pool of funding to real-life projects, to promote DGX adoption.
The incentive for participating in DigixDAO is a little different from other DAOs: DigixDAO participants, who hold DGD tokens, receive rewards every quarter from the DGX fees that come from DGX adoption. These rewards are not only based on how much DGDs you have but also how active you are in contributing to DigixDAO, by either voting or executing projects. As such, there is relatively more immediate gratification for participating, as well as a disincentive to be an inactive DGD holder who does not contribute to the governance process.
DigixDAO is definitely not among the most decentralised DAOs. Proposers would have to pass a Know-Your-Customer (KYC) check by the Digix team. The Digix team can also stop certain projects’ funding due to policy, regulatory or legal reasons. One could say that by operating a blockchain gold product, Digix and DigixDAO have one foot in the real world that needs more centralised processes.
At the time of writing, DigixDAO has just launched on Ethereum Mainnet on 30th March 2019, and there is already 29.1% of the total supply of DGDs that was locked in its contracts to participate in the first quarter. You can find out more about the details in the DigixDAO’s guide, or head over to the DigixDAO Governance Platform to check it out.
MolochDAO — The Incentive Aligning DAO
Launched in Feb 2019, MolochDAO was born as an attempt to tackle the prevalent Moloch problem — which happens when individual incentives are misaligned with globally optimal outcomes. The immediate example that MolochDAO is targeting to solve is the state of Eth 2.0 development nowadays: while some people spend much cost and efforts contributing to Eth 2.0, the benefits of their work are disproportionately shared with all the other projects, who did not have to contribute to the infrastructure development at all. The rational behaviour would then be not to contribute to the infrastructure, which is globally suboptimal.
In MolochDAO, new members need to contribute Ethers into a funding pool to join and receive a proportional amount of stakes. These stakes are used to vote on proposals that are supposed to further MolochDAO’s cause and should increase its value.
There are two types of decisions to be made in MolochDAO: firstly, who to accept into the guild. This is to better align new entrants’ interests with the guild. Secondly, how to allocate new stakes (which essentially dilute the pool of stakes) to proposals that should increase the value of the whole guild.
MolochDAO’s members can liquidate their stakes anytime to get back the proportional amount of funds from the guild. As such, participants are incentivised to either increase the value of the guild by giving fundings to good proposals or to increase their amount of stakes by executing proposals themselves. For example, a proposal asking for 1% of the guild’s value to upgrade the core infrastructure, which people believe would increase Ether’s value by more than 1%, should always receive the funding. Admittedly, the people outside of MolochDAO are still free-riding these infrastructure upgrades. However, a neat thing is that: to the big Ether whales, he/she might do better by contributing his/her idle Ethers to MolochDAO and help to fund the infrastructure upgrades themselves, which might increase their net Ether’s value significantly more. Instead of complaining about the direction and the speed of blockchain development, it might be better to take matters into your own hands, if you want your Ether stash to grow in value. Anyway, that is only in theory. It will be fun to see how MolochDAO will be like in practice.
MolochDAO is not too decentralised in the way it bootstraps the first members and restricts access to new members. At the start, the upgrades are planned to be mostly via “rage-quitting” the old DAO and redeploying new contracts to replace it. These off-chain and centralised mechanisms are features, not flaws, as claimed in the MolochDAO white paper.
DAO Stack And Holographic Consensus This section is about DAO Stack, a framework for creating DAOs, and the concept of holographic consensus introduced by DAO Stack.
The first DAOs built using DAO Stack would include Genesis DAO, created by DAO Stack themselves; DxDAO, created by Gnosis; and PolkaDAO, which is to fund community projects for Polkadot. When launched, all these DAOs would be accessible via Alchemy, a UI framework for DAOs using the DAO Stack.
For the sake of discussion, let’s talk about a SampleDAO that is created using the DAO Stack. There would be two main tokens in the working of SampleDAO: a non-transferable Reputation, and the Predictor Token. Reputation would be used as stakes to vote for proposals in SampleDAO. There can be proposals to upgrade the logic of SampleDAO itself, making it a self-evolving DAO.
Now comes the problem that DaoStack’s holographic consensus is trying to solve: as SampleDAO grows into a big DAO, there would be too many proposals to keep track of. The DAO’s attention should only be spent on the more deserving proposals, not the spammy ones. To summarise DAO Stack’s holographic consensus: people can stake some Predictor Tokens to a certain project A if they think A will likely get passed. If A gets enough Predictor Tokens, it will get boosted into a pool where more people would pay attention to it and the voters’ turnout required for passing will be relaxed. If A really passes, the people who staked Predictor Tokens for A will get back some rewards in terms of Predictor Tokens and Reputation. As such, there is a prediction market that will incentivise people to filter better proposals to be boosted. These boosted proposals would deserve voters’ attention more.
This seems like a neat way to solve the scalability versus resilience problem. Moreover, DAO Stack envisions that the different DAOs that employ its framework will use the same Predictor Tokens GEN, which is created by DAO Stack themselves. This will create a network of “predictors” who will go around the different DAOs and help filter the better proposals.
After reading about DAO Stack, my first concern is that: a person X who staked for a proposal A would just vote Yes for A, regardless if A is good as a proposal or not, since X wants the rewards for predicting correctly.
The second concern is: what kind of incentives could there be for the Reputation holders to vote for the projects that are boosted? If they are not incentivised sufficiently, the only active voters might turn out to be the Stakers themselves, due to the first concern. I will talk about this more in DxDAO.
The third concern is: since “predicting correctly” is defined only by the voting result, predictors might be more concerned about the popular opinions regarding the proposals, more than the actual quality of the proposal. It could be like: “Oh I know proposal B is a bad one, but I also think that it is popular, so nevermind I would just stake for it, and also vote for it since I already stake for it”.
I get that these concerns are not breaking and that having perfect mechanisms are hard, if not impossible. Or perhaps I might have missed out something in my research, in which case I would be happy to hear the answers to these concerns.
DxDAO — The Anarchist DAO
DxDAO, which will be launching in April 2019, is created by Gnosis using DAO Stack, to be a fully decentralised DAO. Gnosis will step back and not retain any kind of control or pre-minted assets in DxDAO after its deployment. All is fair and square.
The initial purpose of DxDAO is to govern the DutchX protocol’s parameters. DutchX is a novel and fully decentralised trading protocol using the Dutch Auction principle. By trading on DutchX, you will get Reputation in DxDAO. Reputation is basically the stake that will be used to vote in DxDAO. You can get Reputation by locking Ethers or other ERC20 tokens traded on DutchX.
Although governing over the DutchX protocol is DxDAO’s initial purpose, DxDAO can literally evolve to anything possible on the Ethereum blockchain, since its participants can vote to upgrade the logic in DxDAO itself.
The incentive for participation in DxDAO is to get more Reputation. However, I have not been able to find a good link between the success of the DutchX protocol and the value of DxDAO’s Reputation. This is basically my second concern in the section about DAO Stack. It is true that the predictors are well incentivised to stake GENs and filter proposals. However, if there is little correlation between the value of Reputation sitting in the voters’ accounts and the success of the DutchX’s protocol, the only ones who are incentivised to vote might just be the predictors themselves, who would just vote for the proposals that they staked. Again, I would be happy to find out that I have not done my research well and missed out something here.
As for the level of decentralisation, DxDAO is clearly highly decentralised on the spectrum. Anyone can participate, and no-one has special power over it.
DutchX would be one of the most, if not the most notable DAO using DAO Stack’s framework, with the holographic consensus mechanism. It is a new concept and it would be interesting to watch how this “anarchist DAO” will turn out to be. As Gnosis has put it:
“The dxDAO will either develop its own life and identity independently of Gnosis — or perish.” — Gnosis
Properties of the different DAOs
Polkadot — The meta-protocol DAO
As with Bitcoin, most blockchains are already DAOs, making decisions on the blocks and transactions level. However, the blockchain protocol mostly stays the same. If the protocol was to be changed, it will be via off-chain and the traditional methods of human coordination (for example, via opinion leaders debating and gaining support from the community).
Polkadot takes it to another level, by moving the protocol upgrade mechanisms on-chain. This means that the stakeholders in Polkadot can decide on hard-forks via on-chain voting, which could smoothly evolve Polkadot to anything possible with a protocol upgrade. Hence, Polkadot could be said to be a meta-protocol — a protocol for changing its own protocol.
Decisions in Polkadot are made via referenda, which could be submitted publicly or by the “council”. The council consists of a number of seats that are continuously added or removed via an election process. The council can propose referenda as well as stopping malicious or dangerous referenda. Ultimately, a referendum must pass a stake-based vote before its proposed changes are executed.
The incentive for the stakeholders to participate in the “Polkadot DAO”, or the governance process of Polkadot, is the appreciation of their stakes (the Dot tokens) due to a successful Polkadot network.
Polkadot clearly has a high level of decentralisation. Well, even the hard-forks are decided by an on-chain vote. Admittedly, the initial selection of the council might not be completely decentralised, which is necessary as many might agree. However, the mechanism of rotating the council’s seats should diffuse these bits of centralisation over time, at least in theory.
Polkadot would be one of the most notable, if not the most notable blockchain that is implementing on-chain governance for protocol upgrades. It would be fun to see what Polkadot would upgrade to. As Gavin has said, he would like to see Polkadot evolve as an entity by itself, which is a powerful concept that might change society and the way humans coordinate in the future.
Final Remarks
With the launch of Polkadot, MolochDAO, DigixDAO, GenesisDAO, DxDAO, WBTC DAO, and PolkaDAO, among others, 2019 could be said to be the year of the DAOs. It’s great to see a variety of different concepts among these newcomers to the world of DAOs. In practice, some of these concepts might work, some might not. Regardless, it will be exciting to witness the early experimentations on the new ways of human coordination through DAOs. Let’s buckle up, it’s gonna be a fun ride. For all you know, we might be catching a glimpse of what human organisations will evolve to in the future.
Do reach out to me via Twitter if you want to discuss further (especially if I wrote something wrong).
Follow me on Twitter if you want to see more content. I did have more to say in certain parts but did not want to make the article too long.
The State Of The DAOs was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Hacker Noon https://hackernoon.com/the-state-of-the-daos-b7cba318460b?source=rss—-3a8144eabfe3—4
This is the second chapter in the story of Branch (we published Deep Linking is Not Enough, covering our rise to become the industry’s leading deep link and user experience platform, two years ago).
Attribution is deceptively difficult. Every mobile marketer considers it critical, and yet many people still feel there is vast opportunity for improvement.
How is this possible? For something that is so important to the modern marketing ecosystem, why are so many of the available options for attribution so disappointing?
The underlying problem is that the mobile attribution platforms we use today are chips off the same old block: technologies that were designed to passively measure a single channel or platform. This is a perfect example of “if your only tool is a hammer, everything looks like a nail.” We need a new toolbox to rebuild attribution in a way that can keep up with our rapidly-changing digital landscape.
The potential of “Attribution 2.0” is enormous. Done well, it is a strategic growth engine that actively helps you grow your business. However, the risks of getting it wrong are just as high: legacy attribution will strangle your growth with broken experiences, misleading data, and inaccurate decisions.
Today, we’re going to explore Branch’s perspective on an ideal Attribution 2.0 solution in five chapters:
This chapter is a tour of marketing attribution up until today, covering offline, digital, and the birth of the mobile attribution provider as a separate service. We will review the basic needs of an attribution solution, the evolution of attribution as channels have fragmented, and specific mobile challenges.
If you check the dictionary entry for “attribution,” you’ll find this:
“The action of regarding something as being caused by a person or thing.”
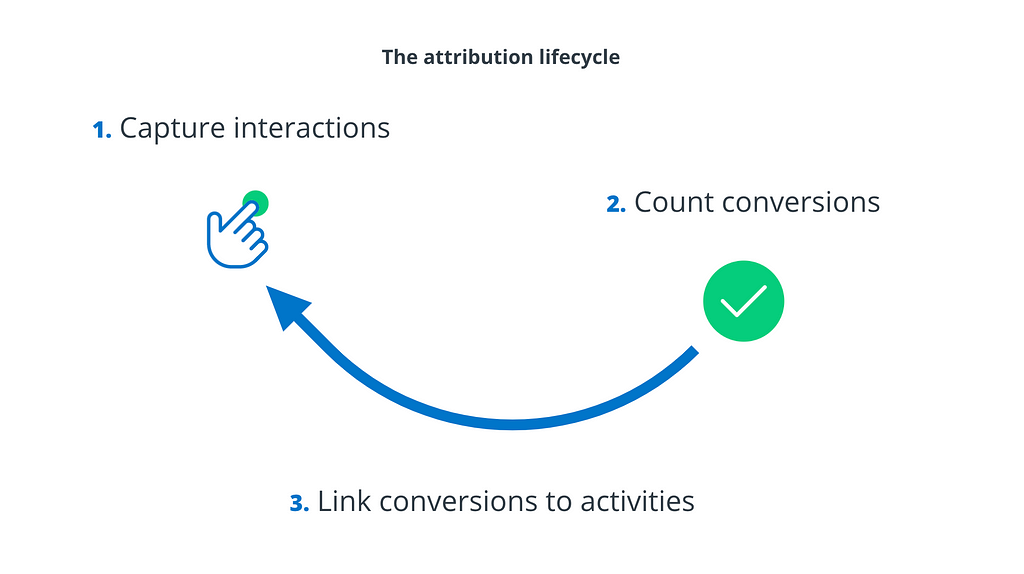
At the most basic level, every marketing attribution system in the world performs three tasks: 1) capture interactions between the user and the brand, 2) count conversions by the user, and 3) link those conversions back to any interactions that — in theory — drove them. When done correctly, this process allows you to figure out if your campaigns are worth the cost.
As we’ll discuss, there’s undeniably now a fourth task: 4) protect against broken user journeys. Attribution is an exercise in futility if anything blocks conversions from actually happening in the first place.
While this sounds straight-forward, it leads to an inherent conflict: tracking every activity and what caused it might sound like paradise to a marketer, but the proliferation of ad blockers, browsers with built-in tracking protections, and new privacy-focused legislation around the world clearly shows that many end users don’t share this perspective.
Attribution has existed for as long as marketing itself, and the techniques involved have changed dramatically over time. As we think about the future of attribution, it’s important to recognize that Attribution 2.0 doesn’t mean “x-ray vision to track everything.” What we need is responsible, secure, privacy-focused measurement that can reliably handle the technical challenges of a complicated digital ecosystem.
Attribution version 0: offline
Billboards, TV commercials, newspapers, and other mass-market campaigns all share one thing in common: everyone who sees them gets the same experience. These campaigns are not individualized, and they are not interactive.
This is a problem for accurate attribution, because it means there is no way to deterministically measure the relative influence of each activity. You could use proxy metrics (e.g., “how many people walked past this billboard last week?”), or try to infer attribution data (e.g., “did sales in a given city increase after my TV commercial?”). You could even try to tease out a few extra insights with workarounds like special discount codes or unique phone numbers for each campaign. But all of these techniques are analog and imprecise.
Attribution version 1: digital
Imagine discovering the electric lightbulb, after a lifetime of candles. That’s what happened to attribution when the digital ecosystem burst to life.
Imagine discovering the electric lightbulb, after a lifetime of candles. That’s what happened to attribution when the digital ecosystem burst to life. New technologies like hyperlinks and cookies made it possible for digital marketers to measure exactly which users encountered a marketing campaign, when and how they interacted with it, and what they did afterwards. Because insights like these are table stakes for attribution today, it’s hard to remember just how big of a breakthrough they were at the time.
In those early days, user journeys were confined to just a single place: the web, on a computer. This was a good thing, because measurement of single-platform customer journeys is a relatively manageable problem. Each marketing channel is responsible for its own attribution: email service providers measure email, ad networks track their ads, and so on. This worked because all channels still led directly back to a website, allowing marketers to string together a conversion funnel that went right down to events representing value (like sign ups or purchases).
The birth of the Mobile Attribution Provider
But then, in 2008, Steve Jobs opened Pandora’s Box by introducing the world to a brand new platform: native mobile apps. In those early days, many mobile marketers (especially in the gaming industry) found that using ads to drive app installs was a sure-fire path to positive ROI. So much so, that other channels and conversions were allowed to fall by the wayside because solving the technical complexity just wasn’t worth the investment.
However, ad install attribution comes with a few significant technical problems of its own: 1) matching, and 2) double attribution.
Matching. The iOS App Store and Android Play Store are attribution black holes. Between the ad click that takes a potential user to download and that user’s first app launch, marketers are completely in the dark. Since the basic definition of attribution is knowing where new users came from, it is critical to find a way around these black holes, in order to connect installs back to clicks that happened earlier.
Double attribution. With so many ad networks all vying for the same eyeballs, users often interact with multiple ads before successfully installing an app. No marketer likes being charged twice for the same thing, but this is exactly what happens when two different networks make claims for driving the same app install.
To solve these problems, a new type of company appeared: the Mobile Attribution Provider. Using a combination of device IDs and a probabilistic technique known as “fingerprinting” (which slurps up device data like model number, IP address, and OS version to create a signature that may or may not actually be unique), these companies provided “matching magic” to figure out which ad a new user had clicked prior to install.
By centralizing all this conversion data in one place, the mobile attribution providers were able to act as independent advocates on behalf of the marketer, ensuring the right ad network got paid (and only paid once).
Chapter 2: How mobile attribution providers became blind
This chapter discusses why mobile attribution providers are losing relevance in our multi-platform world, how this affects the companies that rely on them, and why user experience is now a critical piece of the attribution puzzle.
In the early years of mobile, getting a user to install an app was all that really mattered. Once users had your icon on their home screens, you’d won. And because the ROI of buying app installs with ads was reliably positive, there was no real need to invest in things like cross-channel acquisition or cross-platform re-engagement.
The DNA of these companies is so tied up in apps and ads that the words “app” and “ad” themselves often show up as part of the company name.
All of the traditional mobile attribution providers on the market today were born during this phase of simple and easy paid growth, which means they all suffer from the same foundational problems:
They’re black-and-white TVs in a Technicolor world. The mobile ecosystem has expanded, but the DNA of these companies is so tied up in apps and ads that the words “app” and “ad” themselves often show up as part of the company name (savvy teams recognized this shift years ago and made investments in rebranding).
They’re passive, third-party bean counters. Because these systems grew out of a single-platform, single-channel mindset, they are designed and built on top of an assumption that the only thing they ever needed to do was stand by and observe. They’re like bureaucrats who only care about one outcome (app installs), and only deal in one currency (mobile ads). The rest of the world does not matter. In our new, multi-platform reality, passive observation is no longer enough.
The ironic result of these issues is that legacy systems increasingly fail to deliver the one thing they were built to provide: accurate measurement.
Missed attribution already leads to real costs
Corrupted data and broken customer experiences can do measurable damage to digital businesses. Here’s a realistic possibility:
You want to buy a new pair of shoes.
Scenario 1: how it “should” work. While scrolling through Facebook, you see an app install ad for discounted shoes, download the app, and then proceed to purchase a pair of sneakers. Everything is fine, because this is the basic app install ad working the way it was designed to.
Scenario 2: how things actually happen in real life. While waiting in line at Starbucks, you start by searching the web for shoes. You’re a regular at this Starbucks, so your phone has automatically connected to the wifi. You see an app install ad and click it, but before the download can finish, your order is called and you walk out of the store without opening the app. You remember about the shoes later that evening and complete the purchase at your computer. Meanwhile, another Starbucks customer opens the same app a few hours later to buy a new hat.
Here’s where things get messy: because your ad click happened on the web, a traditional mobile attribution provider would be forced to use fingerprinting to match your install. And because both you and the unknown other customer have the same iPhone model and were using the same Starbucks wifi network, your device fingerprints will be identical. From the attribution provider’s perspective, a single user clicked the ad, opened the app, and purchased the hat. The web conversion, which was actually driven by the ad, gets tracked as a completely separate customer (if it is even captured at all).
While this particular example is an edge case, that’s the whole point: edge cases are no longer the exception to the rule — they are the rule. Businesses that aren’t equipped to handle this are pouring most of their attribution data down the drain without even realizing it.
Attribution and user experience are two sides of the same coin
In order to attribute a conversion, that conversion has to happen in the first place. On the web, single-platform user journeys were robust and relatively unlikely to break, but “The Internet” is no longer a synonym for “websites on computers.”
“The Internet” is no longer a synonym for “websites on computers.”
Today, if you aren’t able to provide the sort of seamless experience your customers want, the cost can be far more than just a lower conversion rate:
I just cancelled my @WSJ subscription after being a reader and subscriber for 39 years. Because they don’t recognize me across my phone or tablet and force me to log in every time. The app works but links from Twitter or elsewhere don’t open the app or deep link. Bye Bye.
The explosion of new channels, platforms, and devices has fractured the digital ecosystem, but users don’t understand (or care) that this fragmentation causes technical headaches for you. They expect seamless experiences that work wherever they interact with your brand.
This means that these days, attribution is not just a marketer’s problem; it impacts every part of the business, and companies that provide attribution as a service need to take a far more active role than simply sitting on the sidelines, counting beans. Legacy systems that haven’t evolved fast enough are already a major business risk because of potentially missing data, and are silently becoming more of a liability over time as they fail to help improve the business metrics they are supposed to measure.
Chapter 3: The future of attribution
This chapter explores the new industry trend toward “people-based attribution” before introducing a truly comprehensive solution: a persona graph.
The digital ecosystem is quickly approaching a breaking point. For example, want to run an email campaign to drive in-app purchases? You’re out of luck with traditional mobile attribution providers; they’re from an older generation that can’t measure email. How about a QR-code campaign in an airport where everyone is sharing public wifi? The ambiguity of fingerprint matching — the only legacy methodology they can use to attribute a user journey like this — will kill you.
The future of mobile attribution isn’t just about apps and ad-driven installs; in fact, it isn’t even just about measurement.
The people-based attribution trend
A number of mobile attribution providers have recently begun jumping on the bandwagon of “people-based attribution.” In plain English, this means expanding scope to consolidate all the interactions and conversions of each user, regardless of where those activities occur.
This is a significant improvement — at least it shows the industry is beginning to acknowledge the problem! — but the devil is in the details: these “people-based” solutions aren’t all created equal, and most of them share the same critical flaws: they still rely on inaccurate matching methods, and they’re only built to provide passive measurement.
In other words, these systems may call themselves “people-based,” but it’s more like lipstick on a pig. The future of mobile attribution isn’t just about apps and ad-driven installs; in fact, it isn’t even just about measurement. Any system built on top of these two assumptions is fundamentally unsuited to the realities of the modern digital world.
The foundation of Attribution 2.0: a persona graph
Fragmentation isn’t a new problem for attribution. Even in the good old days of desktop web, a user might have two different web browsers installed. Or multiple computers. Or they might be using a shared computer at the public library. But this sort of fragmentation was a minor thing that could be filed away with all the other small, discrepancy-causing unmentionables (like incognito browsing mode) that are rarely worth the effort for marketers to address.
Things are different now. Like the frog that doesn’t realize it’s in a pot heating on the stove until it’s too late, fragmentation across channels, platforms, and devices is about to reach the boiling point. This is a data-sucking monster that costs customer loyalty and real money. No serious company can afford to ignore it.
The problem is that traditional attribution methodologies (things like device IDs and web cookies) are siloed inside individual ecosystem fragments. Existing attribution systems see each of these channel/platform/device fragments in isolation, as disconnected and meaningless points.
To fix this problem, what we need now is to zoom way, waaay out. We need a system that lives on top of all this fragmentation, stitching the splintered identity of each actual human customer back together into a cohesive whole, across channels and platforms and devices.
What we need is a Persona Graph. A shared, privacy-focused, public utility that serves the identity needs of everyone in the ecosystem.
This sort of collaboration is hardly a new idea (just think of any service that provides salary comparisons by aggregating the data submitted by individual users), but it has never before been applied as a solution to the challenge of accurate attribution.
Part 2: Building Attribution 2.0
The world of attribution is full of gnarly problems with no single correct solution: things like attribution windows (e.g., “is my ad really responsible for purchases that happened six weeks later?”) and attribution models (e.g., “how do I decide which interactions deserve credit when there are more than one?”) and incrementality (e.g., “did my ad campaign cause the customer to purchase, or would they have done it anyway?”). These lead to difficult questions for any system.
However, before we can even begin to discuss more sophisticated topics like these, the three basics have to be solid: capturing user <> brand interactions, counting user conversions, and linking interactions back to the conversions that drove them. In today’s fragmented digital ecosystem, it’s no longer safe to take that for granted.
In many cases, mobile attribution providers still rely on matching techniques that are essentially semi-educated guessing.
Here’s why traditional mobile attribution solutions fall short in all three areas:
They miss a lot of interactions. Attribution 2.0 needs to catch activity for every kind of campaign (whether owned, earned, or paid), which means reliably covering every inbound channel. Unfortunately, mobile attribution providers are still living in a world where ads are the only channel in town.
They also miss a lot of conversions. Attribution 2.0 needs to catch conversions everywhere businesses have a presence. Users download mobile apps, but they also convert on websites, inside desktop apps, on smart TVs, in stores, and more. Mobile attribution providers still treat all of these other platforms as second-class citizens…if they’re even covered at all.
They’re not very good at linking interactions and conversions. Attribution 2.0 needs to understand the connection between activity (cause) and conversion (effect), otherwise the only result is a mess of isolated event data. In many cases, mobile attribution providers still rely on matching techniques that are essentially semi-educated guessing.
Chapter 4: A review of traditional attribution techniques
This chapter describes the methods used to provide single-channel attribution for websites and apps — the same methods that are now falling short in a multi-platform world.
The ultimate solution to these problems is a persona graph. But before we get into the details of how it works, let’s revisit the world as it exists today; many of these techniques are still important pieces of the persona graph solution, even if they are no longer enough when used alone.
Traditional attribution techniques for the web
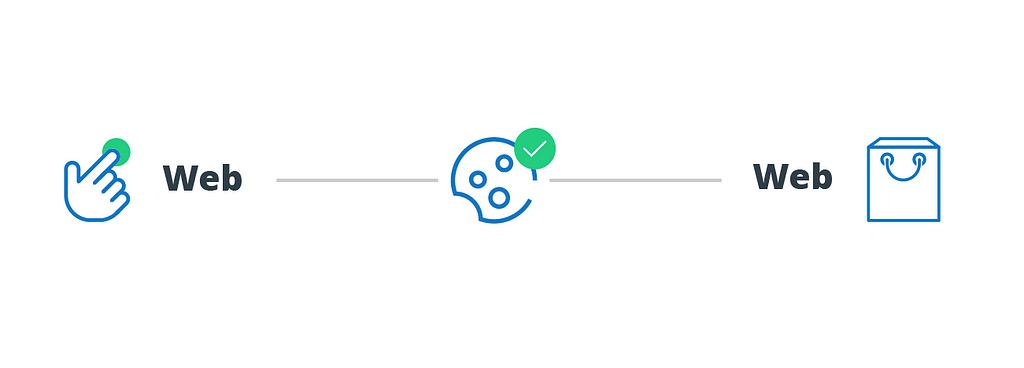
On the web, a variety of techniques make attribution possible, including URL decoration, the HTTP referer (yes, it really is spelled that way in the official specification), and cookies.
URL decoration Everyone who has ever clicked a shortened URL (e.g., https://branch.app.link/jsHNKjzIeU) or wondered why the address of the blog post they’re reading has an alphabet soup of nonsense words at the end (utm_channel, mkt_tok, etc.) is already familiar with this technique.URL decoration is simplistic and often requires manual effort, but it has survived because it just works: encoding attribution data directly into a link the visitor will click anyway is a robust and surefire way to make sure it gets passed along. This is why you’ll often encounter URL decoration in mission-critical attribution situations where durability is key, such as search ads or links in an email campaign.
The HTTP referer When you click a link, your browser often tells the server where you were right before you clicked. This technique has a number of limitations that make it less robust than URL decoration (notably that it can be faked or manipulated by users, and the origin website can intentionally block it), but the biggest advantage for attribution is that it’s automatic. This makes the HTTP referer a popular choice for “nice-to-have” measurement, like tracking which social media sites send you the most traffic.
Cookies for basic identification Techniques like URL decoration and the HTTP referer let you determine how a visitor arrived on your website, but they disappear after that initial pageview. This makes it impossible to rely on either of them alone for attributing conversions back to campaign interactions. Fortunately, there is a solution for this: cookies.
Today, even casual internet users know what cookies are: little pieces of data that browsers remember on behalf of websites. They have many uses, but one of the most common (and the most important for attribution) is storing a unique, anonymized ID. These IDs don’t contain any sensitive info, but the effect is much like sticking a name tag on each visitor: they make it possible to recognize every request by a given browser — including down-funnel conversions like purchases — and attribute them back to the original marketing campaign.
Advanced cookies Pretty much every web-based measurement or analytics tool on the market today uses cookies to some degree, and basic identification was just the beginning — cookies have long been used for other, more sophisticated purposes. One of the most common is cross-site attribution, which works like this:
For obvious security and privacy reasons, browsers restrict how cookies can be set and retrieved. After all, no one would be happy if Coca-Cola had the power to mess with Pepsi’s cookies. To prevent this, cookies are scoped to individual domains, and web browsers only give cookie permissions to domains that are involved in serving the website. This means that unless pepsi.com tries to load a file from coke.com, Pepsi’s cookies are secured against anything devious taking place [attempts to defeat these protections are part of a large infosec topic known as “cross-site scripting attacks,” or XSS for short].
Cookie security is a necessary and good thing, so the web ecosystem has figured out a number of creative ways to perform cross-site attribution within these limitations. For example, if Pepsi wants to run ads on both www.beverage-reviews.net and www.cola-lovers.org, then everyone agrees to allow a neutral third-party domain (in the world of web-only attribution, often owned by an ad network) to place a cookie that is accessible across all three of these websites. The end result is that the third-party ad network can recognize the same user across every site involved, and leverage that data to provide attribution for their ads. To help increase coverage, it’s even become standard industry practice for these third-parties to share their tracking cookies with each other (a process called “cookie syncing”).
However, the tide is starting to turn against cookie-based attribution networks. Due in part to end-user outrage triggered by “creepy ads,” major web browsers have implemented restrictions on cookies: ITP on Safari, ETP on Firefox, and even Chrome is reported to be working on something similar. Third-party ad blockers and privacy extensions pick up where the built-in functionality stops, and new privacy-focused legislation around the world (such as GDPR) continues to restrict what companies can implement.
Traditional attribution techniques for apps
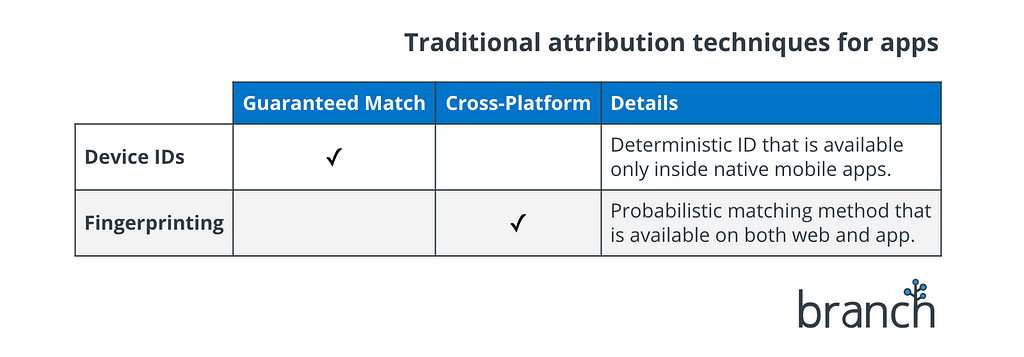
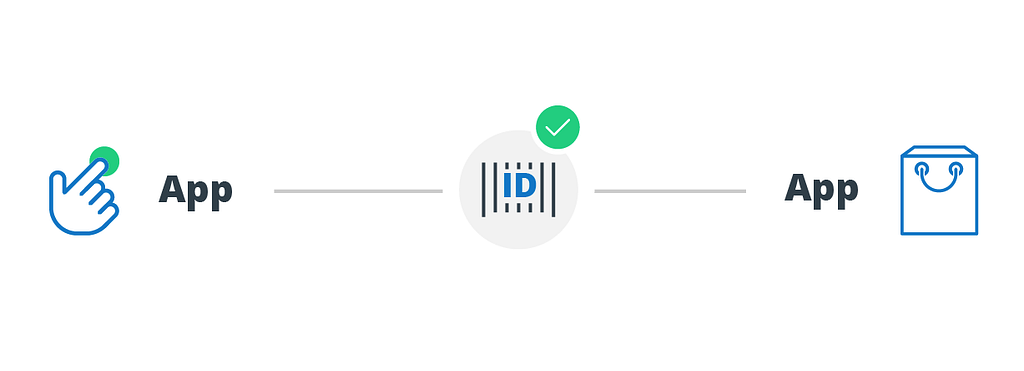
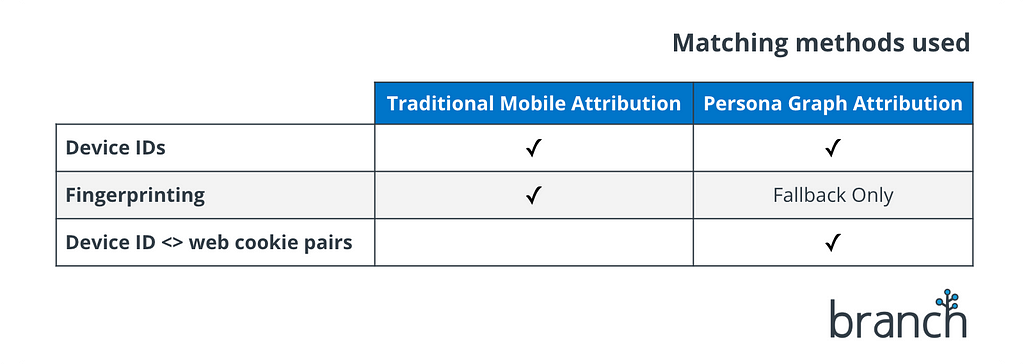
Mobile attribution providers rely on two techniques for matching installs back to ad touchpoints: device IDs, and fingerprinting.
Device IDs Every mobile device has a unique, permanent hardware ID. In the early days, it was common practice for app developers (including, by extension, attribution providers and ad networks) to access these hardware IDs directly, and one of the common use cases was ad attribution.
However, while “unique” is a good thing for attribution accuracy, “permanent” leads to obvious privacy concerns. Apple recognized this in 2012, and closed off developer access to these root-level hardware IDs. As a replacement, app developers got the IDFA (ID For Advertisers) on iOS. Google quickly followed with the GAID (Google Advertising ID) on Android. The IDFA and GAID are still unique to each device, making them a good solution for attribution, but give additional privacy controls to the end-user, such as the ability to limit access to the ID (“Limit Ad Tracking”) or reset the ID at any time, much like clearing cookies on the web.
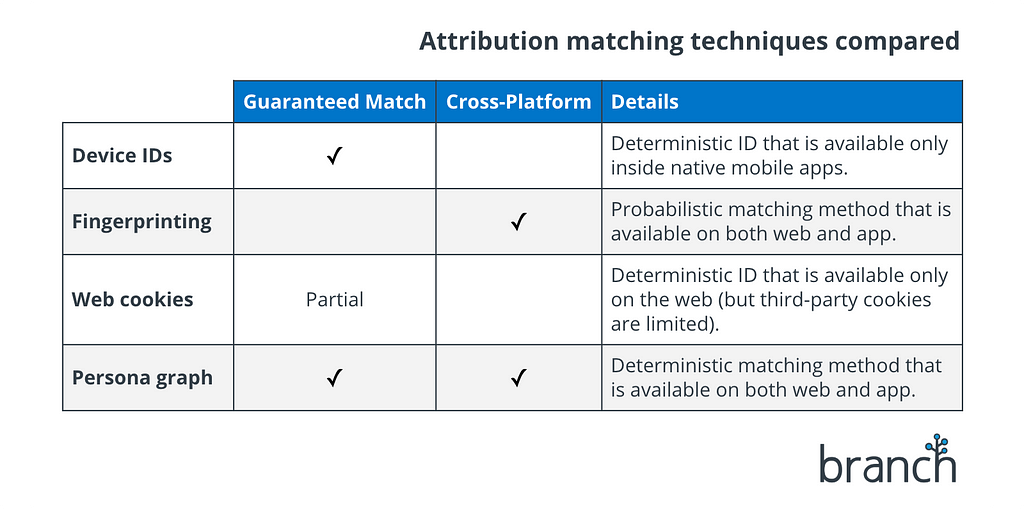
Device IDs are a “deterministic” matching method. This means there is no chance of incorrect matching, because the device ID on the install either matches the device ID on the ad touchpoint…or it doesn’t. No ambiguity. Because of this guaranteed accuracy, device IDs remain the attribution matching technique of choice, whenever they are available.
Unfortunately, device IDs are not always available. This issue crops up in many situations, but here’s the big one: device IDs are off-limits to websites. This makes them a single-platform matching technique — they only work for attribution when the user is coming from an ad that was shown inside another native app.
This left the mobile ecosystem with a problem: since device IDs are siloed inside apps, and cookies are equally limited to just the web, how to bridge the gap and perform attribution when a touchpoint happens on one platform and a conversion happens on the other?
Fingerprinting To solve this problem, the mobile attribution industry turned to a technique known as “fingerprinting”. While fingerprinting had long existed as a niche solution on the web (often used to help fight fraud), app attribution took it mainstream.
By now, most marketers — and even many savvy consumers — are familiar with how fingerprinting works: various pieces of data about the device (model number, OS version, screen resolution, IP address, etc.) are combined into a distinctive digital signature, or “fingerprint.” By collecting the same data on both web (when the ad or link is clicked) and app (after install), the attribution provider is theoretically able to identify an individual user in both places.
While this solves the immediate challenge of tracking a user from one platform to another, there are two important catches:
Fingerprinting is a “probabilistic” matching method. No matter how confident you may be that two fingerprints are from the same user, there’s always a chance that you’re wrong. There’s always an element of guesswork involved.
Fingerprints go stale. Much of the data used to generate fingerprints can change without warning, which means they begin going stale as soon as they’re created. This degradation is exponential, and most mobile attribution providers consider a fingerprint-based match to be worthless after 24 hours.
In the early days of app attribution, most marketers saw the ambiguity inherent in fingerprinting as a manageable risk (and it was certainly better than the alternative, which was no attribution at all). However, this ambiguity has become harder and harder to ignore over time: today, there are simply too many people with the latest iPhone and the most recent version of iOS, all downloading apps via the same AT&T cell phone tower in San Francisco.
Chapter 5: The next generation: a persona graph
This chapter explains how a persona graph works, addresses common concerns around user privacy and data security, and goes in depth on how we built Branch’s persona graph. It ends by comparing the older generation of mobile attribution providers with what is possible with a persona graph.
The problem with traditional attribution techniques is they are either probabilistic (meaning there’s a chance the data is wrong), or siloed inside a single platform (web or app). A persona graph provides the best of both worlds.
Imagine the game of Concentration(for those who haven’t played this in a few years, it’s the one where you flip two random cards over, hoping to find a match). The chances of discovering a pair on your first turn are extremely low, but over time (and time is the critical element here), you learn where everything is. Eventually, assuming you have a good memory, you’re uncovering matches on almost every round.
Now, let’s take the metaphor one step further: instead of you flipping cards to learn where they are, imagine a hypothetical situation where you get to join a game in progress, where every card on the table has already been turned face up by other players before your first turn. It wouldn’t be much of a game, but you’d be guaranteed to find a match every time.
Like a Concentration game where all the cards have already been flipped before your first turn, a persona graph allows you to accurately match users that YOU haven’t seen before, but someone else in the network has.
That’s the concept behind a persona graph: by sharing matches between anonymous data points, everyone wins. Like a Concentration game where all the cards have already been flipped before your first turn, a persona graph allows you to accurately match users that YOU haven’t seen before, but someone else in the network has.
The elephants in the room: privacy, security, and confidentiality.
For a persona graph to survive, there are a couple of critical things that must be guaranteed: 1) privacy and security of user data, and 2) confidentiality.
User privacy and data security. A persona graph makes it possible to recognize a given user in different places, but it does not tell you anything about WHO that user is. If the user wants you to know that information, then you already have it in your own system — the persona graph simply closes the loop by telling you that you’re seeing an existing customer in a new place. And like cookies or device IDs, the user can reset their connection to the persona graph on demand.
In other words, the persona graph must take the same approach to privacy as the postal service. Our letter carriers need to know our physical location in order to deliver mail, but they’re only concerned with the address, not the addressee. We trust that they won’t open our letters and won’t sell information about what we buy to the highest bidder.
At Branch, we feel so strongly about user privacy that we have made a number of public commitments about it. The short version can be expressed as three points in plain English: 1) we proactively limit the data we collect to only what is absolutely necessary to power the service that we deliver to our customers, 2) we will only ever provide our customers with data about end-user activity that happens on their own apps or websites, and 3) we do not rent or sell end-user personal data, period (not as targeting audiences to other Branch customers, not via cookie-syncing side deals with identity companies, not via an “independent” subsidiary — we just don’t do it).
In addition, we rigorously and proactively follow best practices to purge sensitive data and protect our platform against bad actors.
Confidentiality. The only data that is available via a persona graph is knowledge of the connection itself. Not where or how the connection was made, or by which company’s end user. A persona graph must guarantee that it will never allow Pepsi to purchase a list of Coke’s customers.
Said another way, the Swiss have avoided every war in Europe for over 500 years, because everyone recognizes that they are (and always will be) neutral. A persona graph must maintain the same unimpeachable reputation.
A peek inside the Branch persona graph
When we set out to build Branch in 2014, there was already a well-established industry of mobile attribution providers. All of them were competing with each other for the low-hanging fruit of measuring ad-driven app installs. If you work in the mobile industry, you’re likely familiar with their names already (Branch acquired the attribution business of one last year).
Even though the Branch platform might resemble a traditional attribution provider on the surface, the engine underneath is something fundamentally, radically different.
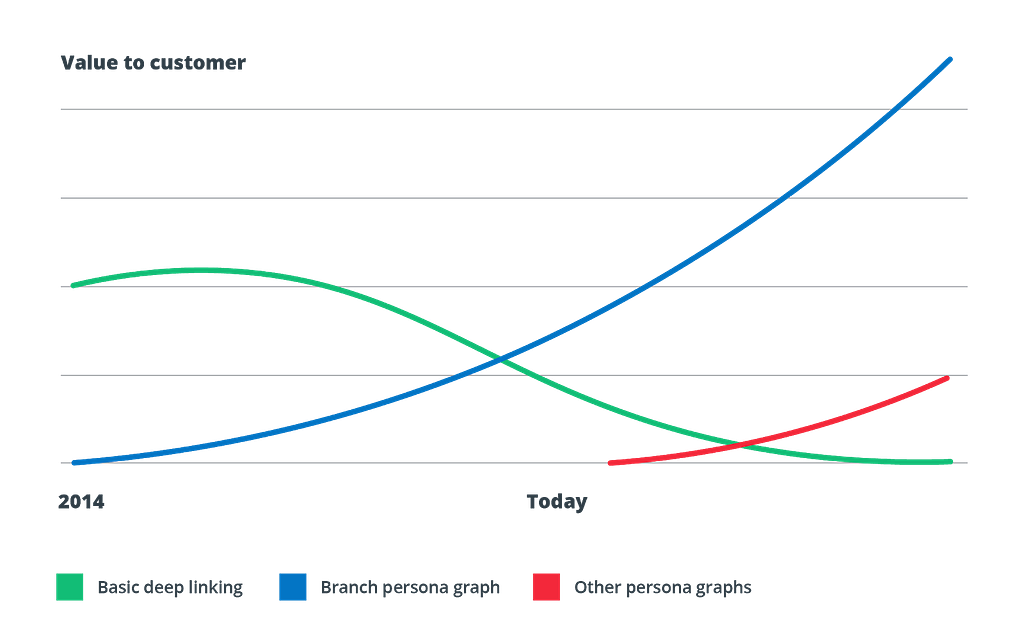
We decided to take a different approach: we realized the app install ad was a bubble that would eventually deflate, and we also knew that seamless user experiences would become increasingly important as marketers began to care about other channels and conversion events again. So we started by solving the more difficult technical problems that everyone else was ignoring (this is the story we told two years ago inDeep Linking is Not Enough).
The result: through solving the cross-platform user experience problem at scale, for many of the best-known brands in the world, we created a persona graph that allows Branch to provide an attribution solution that is both more accurate and more reliable than anything else available.
Here’s how it works today:
Step 1: Collect deterministic IDs
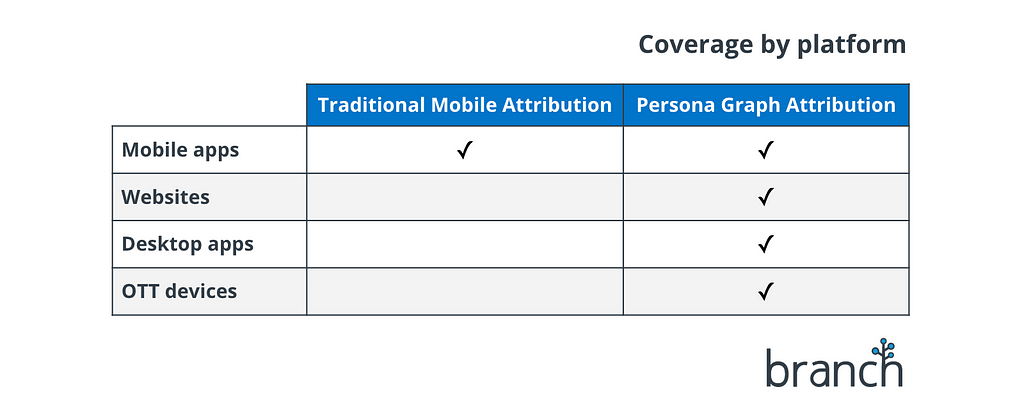
Believe it or not, this is actually the relatively easy part. User activity occurs in fragments across platforms, and the goal is to have a deterministic ID for each of them. Since Branch’s customers invest most of their marketing resources into websites and mobile apps, these are the platforms where we’ve focused the majority of our effort so far. But the same principle applies anywhere.
To create deterministic IDs on the web, we use a javascript SDK to set first-party cookies. Inside apps, we offer native SDKs to leverage device IDs.
We’ve also built SDKs for desktop apps on macOS and Windows, and custom OTT (Over The Top) device integrations. We will continue adding support for new platforms as customers request them.
Step 2: Create persona matches
Once we have an ID for an identity fragment, we use a layered system of cross-platform matching techniques to tie it back to a persona record on the persona graph. Here are a few examples:
Deep links. When a user clicks a link to go from one place to another, that is an ideal time to make a connection. This is our primary method for matching fragments that exist on the same device (e.g., Safari, Facebook browser, native apps), and one of the most reliable because it’s driven by the user’s own activity.
User IDs. When a user logs into an account, they’re providing a unique ID that can then be matched if the same user signs in later in another place. We only use this signal to a limited extent today, because there are a number of tricky problems related to shared devices, but we’re actively working on solutions and see a lot of promise in this method. As a side note, this is the only matching method we’ve seen competitors use when they talk about “people-based attribution.” Given the shared device challenges mentioned above, or the fact that (depending on the vertical) the vast majority of visitors never log in, this is certainly an area to question if you’re currently working with one of them.
Google Play referrer. Google passes a limited amount of data through the Play Store during the first install. Branch uses this one-time connection to create a permanent match back to the persona graph.
Fingerprinting. This is one cross-platform matching method we don’t use to build the persona graph, but it deserves a mention because it is so commonplace in the attribution industry. Branch sometimes has to fall back on fingerprinting when the persona graph can’t provide a stronger pre-existing match, so we’ve invested in an IPv6-based engine that greatly increases accuracy over traditional mobile attribution providers that still rely exclusively on IPv4.
Because of Branch’s massive, worldwide scale, we can also use machine learning to uncover connections between different personas that likely belong to the same user, and just haven’t yet been deterministically merged. We call these “probabilistic matches” because they’re not 100% guaranteed on each end, but they’re still useful and helpful when combined with the high degree of confidence that we get from observing other deterministic patterns.
Here’s how probabilistic matching compares to fingerprinting:
Fingerprinting. Fingerprinting has to happen in real time. In other words, it requires a guess to be made based solely on whatever data is available at the exact moment a user does something. That user might be sitting alone at home (high accuracy situation), or they might be sharing public wifi with several thousand other people while walking around a shopping mall (very low accuracy situation). With fingerprinting, the system has only two choices: 1) it can take a gamble and make the match, or 2) it can throw away the match and say no attribution happened. All of the fancy “dynamic fingerprinting” systems offered by traditional mobile attribution providers are really just trying to decide when to choose option 2.
Probabilistic matching. Because the persona graph is persistent, Branch can afford to be patient. We don’t have to play roulette in real time when the conversion event occurs; instead, we’re able to preemptively store “prob-matches” when the system detects no ambiguity (e.g., when the user is alone at home) to use later (e.g., when the user is inside a crowded shopping mall). For example, the algorithm might create a prob-match if it notices that persona A and persona B have matching fingerprints, were both active on the same IP within 60 seconds of each other, and no other activity occurred from that IP within the last day.
When making these prob-matches between different personas, our system records a “confidence level.” This allows us to move linked personas in and out of consideration depending on the use case. For example, a “match guaranteed” deep link used for auto-login would obviously require a confidence level of 100%, but the industry expects ad installs to be matched with a confidence level usually between 50–85% (the persona graph allows Branch to hit the top end of this range without being forced to accept lower-confidence matches).
Today, Branch dynamically sets the confidence level required for each use case, but this is a configuration we could expose directly to our customers in the future.
Step 3: Scale the network
It’s impossible to just “build a persona graph” because — in the beginning — there is no reason for anyone to sign up.
Why? The value of a persona graph increases for everyone as more companies contribute to it, which means the benefit of joining an existing persona graph is enormous, but there is very little incentive to be one of the best participants in a brand new persona graph — it would be like giving up that already-flipped Concentration game for a new one where you’re playing all by yourself.
Because Branch started out by solving cross-platform user experiences, our persona graph scaled as a natural side-effect of other products that provide independent value at the same time. This approach allowed the Branch persona graph (which now covers over 50,000 companies) to reach critical mass. However, while basic deep linking was a hard problem to solve back in 2014, it is now well on the way to commoditization. Today, it would be almost impossible to get a persona graph off the ground using basic deep links, let alone ever reach a similar level of coverage.
Step 4: Use the match data
What can Branch do with these cross-platform/cross-channel/cross-device personas? Here are a few examples:
Solve attribution ambiguities. This is the obvious one, of course. The persona graph makes it possible to correctly attribute the complicated user journeys we’ve been discussing, such as when you and the other Starbucks customer were both using the same shopping app, and traditional fingerprint-based attribution methods couldn’t tell the difference.
Provide data for true multi-touch reporting. Using multi-touch modeling to better understand user activity is the Promised Land of attribution: every marketer wants it, and everyone has a different idea of what it should be. But there’s one thing everyone should agree on: multi-touch attribution is only as good as the data you feed it, and bad data compounds the problem.
The persona graph allows Branch to consolidate data from across channels and platforms. Legacy mobile attribution providers completely miss this data, which means their “multi-touch attribution” is really just “multi-ad app install attribution.”
Protect user privacy. Fingerprinting has long been a necessary evil for mobile attribution, but inaccurate measurement isn’t the only cost — when fingerprinting matches the wrong user, this also introduces user privacy issues because it means the system believes it is dealing with someone else. The persona graph allows Branch to dramatically reduce the risk of incorrect matching (we even offer a “match guaranteed” flag to enforce it), better protecting the privacy of end users.
Go beyond measurement. Attribution is only possible if the conversion happens in the first place. The persona graph allows Branch to provide the seamless cross-platform user experiences that make this more likely, improving the performance of all your marketing efforts.
For example, if a user lands on your website, even though they already have your app installed, Branch can use the persona graph to detect this and show that user the option to seamlessly switch over to the same content inside your app, where they’re much more likely to complete a purchase.
Comparing persona graph attribution with previous-generation alternatives
To wrap up, let’s revisit the three core tasks of an attribution system, and compare the capabilities of a persona graph-based platform with the traditional alternatives.
1. Capture interactions
Mobile attribution providers started with ads, and have struggled ever since to retrofit their systems in a way that accommodates other channels.
A persona graph is able to support ads, but also support email, web, social, search, offline, and more.
2. Count conversions
Mobile attribution providers are optimized to capture app install events, and aren’t set up to handle non-install conversions that happen on other platforms. Many of them are now rushing to figure out how to perform basic web measurement, a problem that was solved years before apps entered the picture.
A persona graph can attribute app installs, and also captures other down-funnel conversions on websites, desktop apps, OTT devices, and more.
3. Link conversions back to interactions that drove them
As described in part 2, mobile attribution providers have two matching methods available: they default to device IDs, and fall back on fingerprinting.
A persona graph-powered system can also use device IDs for single-platform user journeys (app-to-app), and has device ID <> web cookie pairs for cross-platform (web-to-app) user journeys. It may occasionally have to fall back on fingerprinting when a matched ID pair is not yet available, but this is a far less frequent situation.
What comes next
Fragmentation in the digital ecosystem is a hornet’s nest that can’t be un-kicked, and the challenge of attribution between web and app is just the beginning — it’s going to get worse (just imagine what it will be like when you need to attribute between your toaster and your car!)
Web and app is just the beginning — it’s going to get worse. Just imagine what it will be like when you need to attribute between your toaster and your car.
Attribution based on a persona graph makes it possible to handle this fragmentation, and a persona graph built on user-driven link activity is even more powerful because it leads to a virtuous circle: links are the common thread of digital marketing, which means they’ll always be the natural choice for every channel, platform, and device. These links help build the persona graph, and the result is increased ROI, comprehensive measurement everywhere, and more reliable links.
No other platform-specific attribution solution is even in the same league.
At Branch, we see attribution as one part of a holistic solution that provides far more than app install measurement. Our true mission is to solve the problem of content discovery in the modern digital ecosystem. Deep linking was one critical part of this mission. Fixing attribution is another. But the real win is yet to come…stay tuned!
Appendix: FAQ & Objections
What if device manufacturers try to limit the persona graph?
Device manufacturers have a duty to protect their users. They also need to ensure their ecosystems allow companies to be commercially viable. A privacy-conscious, third-party persona graph is an excellent fit for both of these requirements.
Branch works closely with a number of device manufacturers. They are aware of our platform, and supportive of the solution we’ve built.
Doesn’t a persona graph allow companies to steal their competitors’ proprietary data?
No, it does not, because the only data available via a persona graph is knowledge of the connection itself. Not where or how the connection was made, or by which company’s end user. A healthy persona graph contains thousands of participants, ensuring no single company is disproportionately represented, and to survive, a persona graph must guarantee that it will never allow any company to access data it hasn’t independently earned.
Persona graphs sound problematic for user privacy…
A persona graph makes it possible to recognize a given user in different places, but it does not tell you anything about WHO that user is. And like cookies or device IDs, the connection is resettable on demand.
We limit the data we collect. We practice data minimization, which means that we avoid collecting or storing information that we don’t need to provide our services. The personal data that we collect is limited to data like advertising identifiers, IP address, and information derived from resettable cookies (the full list is below in our privacy policy). We do not collect or store information such as names, email addresses, physical addresses, or SSNs. Nor do we want to. In fact, our Terms & Conditions prohibit our customers from sharing with Branch any kind of sensitive end-user information. We will collect phone numbers if a customer uses our Text-Me-the-App feature — but in that case, we will collect and process end user phone numbers solely to enable the text message, and will delete it within 7 days afterwards.
We will only provide you with data about actual end-user activity on your apps or websites. Our customers can only access “earned” cookies or identifiers. This means that an end user must visit a customer’s site before our customer can see the cookie; and an end user must download a customer’s app in order for Branch to collect the end user’s advertising identifier for that customer. In short, the Branch services benefit customers who already have seen an end user across their platforms and want to understand the relationship between those web visits and app sessions.
We do not rent or sell personal data. No Branch customer can access another Branch customer’s end-user data. And we are not in the business of renting or selling any customer’s end-user data to anyone else. To enable customers to control their end-user personal data, they can request deletion of that data at any time, whether in bulk or for a specific end user. These controls are available to customers worldwide, although we designed them to comply with GDPR requirements as well.
How is a persona graph different from “identity resolution” or “people-based marketing” products?
While these products may have similar-sounding names and seem comparable on the surface, they are very different underneath. Here are three major contrasts:
How they are built. The data for these products is typically purchased in bulk from third-parties, and then aggregated into profiles. The Branch persona graph is built from directly-observed user activity, and does not incorporate any personal data acquired from external sources.
What they contain. The user profiles available via these products typically contain sensitive personal data like name, email address, age, gender, shopping preferences, and so on. The Branch persona graph contains only anonymized, cross-platform identifier matches, and has no use for sensitive personal data — we don’t even accept it from customers.
How they are used. A major use case for these products is selling audiences for retargeting ads. This is a fundamentally different objective than the accurate measurement and seamless user experiences that Branch exists to provide.
What about fraud?
Fraud is a never-ending game of cat-and-mouse: as long as there is value changing hands (the literal definition of an ad), fraud can never be truly solved because savvy fraudsters will always find a way through.
The realistic objective of a mobile attribution provider is to block “stupid fraud,” and make fraud hard enough that fraudsters will go somewhere else. The best way to do this is by weeding out anything that doesn’t reflect a realistic human activity pattern. A persona graph has vastly more sophisticated data to use for this assessment than any single-channel, single-platform system.
What about when the persona graph doesn’t cover a user?
Even with a network size of Branch, there are still situations when the persona graph isn’t available. As just a few examples: the first time seeing a new device, browser cookie resets, ITP in iOS, etc.
In those situations, the system has to fall back on the next-best matching technique available. In Branch’s case, this is still as good as (and usually better than) what is available via legacy attribution providers.
What about cross-device attribution?
Cross-device is a surprisingly complicated problem. In theory, the persona graph can connect data across devices, just like it does across channels and platforms.
Some mobile attribution providers have recently begun leaning on cross-device tracking as their entry into “people-based attribution.” Essentially, they merge activity based on a customer-supplied identifier such as an email address or username — if you sign in with the same ID on two devices, then they consider these to belong to the same person for attribution purposes.
This sounds logical on the surface, and it works for these providers because they’re still approaching measurement from a siloed, one-app-at-a-time perspective. Branch already does similar cross-device conversion merging based on user IDs on an app-by-app basis, in addition to the persona graph.
Here’s where things get complicated for cross-device as part of a persona graph:
It’s fairly rational to assume the majority of activity on a single mobile device is from a single human. Sure, people let their friends make a phone call, or check the status of a flight, and this has the potential to muddy attribution data somewhat, but the impact is pretty limited. However, if a user lets a friend sign into their email account on a laptop to print a flight confirmation, and the attribution provider then uses that as the basis to merge identity fragments across the entire persona graph network, the cascading effects could lead to massive unintended consequences.
Our customers ask us about cross-device attribution regularly, and our research team has made good progress. We feel data integrity is the most valuable thing we can offer, so we haven’t rushed because we want to make sure we get this right.
Why are deep links so important?
Some legacy mobile attribution providers feel that deep links aren’t critical to attribution. And from a certain perspective, they’re right: it’s perfectly possible to be a bean counter without also being a knowledgeable guide. At Branch, we feel this is an extremely shortsighted perspective, because the ongoing fragmentation of our digital ecosystem means that without working links, eventually there will be nothing left to measure.
Let’s illustrate this with an example from the offline world:
Imagine a billboard for your local car dealership. Driving down the highway, on the way home from the grocery store, you see this billboard advertising the newest plug-in hybrid. You don’t really need a new car, but your old one has been leaking oil all over the garage floor for months and the Check Engine light came on last week, so you decide (on the spur of the moment) that you want to stop in for a test drive.
You’re excited. You can almost smell “new car” already, and you’re all set to take the highway exit for the dealership…but the off-ramp is blocked by a big orange sign: “Closed for Construction.” You’d have to go five minutes further up the highway to the next exit, and then spend ten minutes figuring out how to drive back on local roads. And besides, that milk in the back seat is going to spoil if you leave it in the sun. You give up and go home.
A week later, you happen to be driving by the dealership again. The highway exit has reopened, and that new car smell has been following you around everywhere for the last few days. But the billboard is now advertising your local bank, and that ad you saw a week earlier has completely faded from your memory. When the salesperson asks, “What caused you to come by today?”, you say, “Oh, I just happened to be in the neighborhood.”
Now, the dealership has two problems:
You might never have come back after the first broken journey. You might even have gone to another dealership instead, because all new cars smell pretty much the same.
The dealership has no idea that the billboard is the real reason behind your visit.Because you don’t even remember yourself. If you end up buying, the billboard was a worthwhile investment…but they’ll never know this, because the highway construction interrupted your journey and broke the dealership’s attribution loop.
It’s not much of a stretch to replace “car” with “app,” “billboard” with “install ad,” and “highway exit” with “link.”
The reality is that in the digital world today, links are the customer journey. If your links don’t work, then even the best measurement tool in the world can’t help you attribute conversions that never happened.
Bottom line: if you find an attribution system that claims to provide measurement without also solving for links that work in every situation (and proving with verifiable data that their links don’t break), be very, very skeptical. It’s likely you’re dealing with a legacy system that hasn’t adapted to changes that have happened in the ecosystem over the last few years.
What if another company creates a persona graph?
This is always a possibility, but due to the nature of network effect, it would be extremely challenging for any other company to reach the critical mass necessary to compete with the Branch persona graph.
Because Branch started out by solving cross-platform user experiences, our persona graph scaled as a natural side-effect of other products that provide independent value at the same time. This approach allowed the Branch persona graph (which now covers over 50,000 companies) to reach critical mass. However, while basic deep linking was a hard problem to solve back in 2014, it is now well on the way to commoditization. Today, it would be almost impossible to get a persona graph off the ground using basic deep links, let alone ever reach a similar level of coverage.
What about Self-Attributing Networks (SANs)?
SANs like Facebook, Google, Twitter, and so on hook their walled gardens into the ecosystem via the device ID. The difference is that instead of allowing attribution providers to observe all of the user’s interactions, the SAN just responds with a Yes or No when asked the question “hey, this device ID just did something…did you see that user in the last X days?”
The SAN approach has advantages (fraud is an almost non-existent problem) and disadvantages (it’s a black box that provides very little visibility), but it’s a reality of the ad ecosystem.
Since most walled gardens already connect theirs users across platforms through a user ID or email address, there’s no reason why the SAN can’t start reporting activities by that user on other devices/platforms. This sort of connection gets incorporated into the persona graph automatically through the associated device ID.
What about Limit Ad Tracking (LAT) on iOS?
When LAT is enabled, iOS sends the IDFA as a string of zeros. Currently, it appears that around 20% of iOS have this setting enabled. Without an IDFA, Branch is unable to connect that user to the persona graph, but we are still able to perform attribution via fingerprinting or the IDFV (an alternative device ID that is available even with LAT enabled, but scoped to a single app/vendor).
The Death of App Attribution was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Hacker Noon https://hackernoon.com/the-death-of-app-attribution-abb6f370d0c7?source=rss—-3a8144eabfe3—4
Some of the problems we work on as UX researchers are simple and are easily solved by getting users in front of our product. But other problems can be complex and it’s hard to know how to start solving them. In situations like that, a simple 2×2 diagram can cut through the “what ifs”, the “how abouts” and the edge cases and provide a simple way of looking at the problem. Here are 10 examples of 2×2 diagrams to simplify UX research discussions.
Loved by management consultants, a 2×2 diagram is a simple — some might say simplistic — way of looking at a problem. You consider each of the various factors in your problem and choose two that are important and that can be classified into discrete values.
One of my favourite examples comes from Steve Jobs. When Jobs returned to Apple in 1997, he looked at the product line up and thought it a mess. There were 15 product platforms and many variants of each one. He wanted to simplify Apple’s product line, so in 1998 he presented a four-quadrant product grid at the Macworld Expo. One axis on the grid was the platform (Desktop / Portable). The other axis was the market segment (Consumer / Professional). He then re-oriented Apple around creating the best possible product in each quadrant, leading to the iMac and the iBook in the consumer segments and the Power Mac and the PowerBook in the professional segments.
The problems that we deal with in product development are sometimes multi-factorial and complex. In these situations we can get swept up in discussions of technical issues or business rules and forget the importance of users and their goals. If you find that happening in your next meeting, turn to the whiteboard and try using one of these diagrams to simplify the problem and keep user needs in the forefront of the discussion.
How to decide what user groups to research with first
When we think of all the different user types for our product or service, it can sometimes seem overwhelming. It’s not clear where we should start our research. When I find a team in that position, I sketch out Diagram 1. The vertical axis is the amount we will learn (or expect to learn) by visiting a particular user group. Some user groups will teach us a lot about how they work in the product domain and there are others that we may already know much about. The horizontal axis is how easy or difficult it is to get to that user group. Some groups are simple to find (they may be in the same town as us) whereas others may be difficult to access because of factors like their geographical location or work schedule.
Diagram 1: A 2×2 plot with the axes,”Amount we will learn” and “Ease of access”.
The four quadrants are:
Ignore: User groups in this quadrant are hard to get to and will teach us little, so we can ignore them.
Schedule when convenient: User groups in this quadrant are easy to get to but we won’t learn much from them. It makes sense to schedule visits to these groups only if you have some spare time between visiting the other groups of users.
Plan these: We expect to learn a lot from these user groups, but for one reason or another they are hard to get to. We should start planning these visits to ensure we see these groups in the future.
Start here: These user groups are easy to get to and we expect to learn a lot from them. It makes sense to start our research here as we can get going immediately and provide some real value to the development team.
How to create personas
A simple way to identify personas from your research is to identify two dimensions that appear of overriding importance in your research and then to group your research participants in the appropriate quadrant. In Diagram 2, I’ve chosen two dimensions that tend to be of importance on many projects: people’s expertise with technology and their knowledge of the domain of interest.
Diagram 2: A 2×2 plot with the axes,”Technical expertise” and “Domain knowledge”.
The four quadrants are:
Learners: This persona has low technical expertise and little domain knowledge.
Geeks: This persona has high technical expertise and little domain knowledge.
Experts: This persona has high technical expertise and high domain knowledge.
Novices: This persona has low technical expertise and high domain knowledge.
Assuming you have data from field visits, you should be able to create more meaningful dimensions than these. If not, these dimensions often work well to generate assumption personas.
How to identify red routes
A 2×2 plot makes it easy to identify the red routes —the key tasks —that users carry out. In this example, the two dimensions are task frequency (that is, how often users carry out the task) and task importance (that is, how important the task is for users).
Diagram 3: A 2×2 plot with the axes,”Task frequency” and “Task importance”.
The four quadrants are:
Hidden tasks: These are low frequency, low importance tasks. It doesn’t make sense to spend much time researching or optimising these tasks.
Hygiene tasks: These are high frequency, low importance tasks: the mundane tasks (such as authentication) that users have to complete before doing what they actually want to.
One-off tasks: These are low frequency, high importance tasks: an example might be software installation or creating an account.
Red routes: These are high frequency, high importance tasks: we must optimise the usability of these tasks in our system.
How to decide what to fix
On completion of a usability evaluation, the development team needs to prioritise the problems so they know which ones to fix first. Diagram 4 shows a 2×2 diagram that can help here. The two dimensions are “Task frequency” (how often the task is carried out) and “Task difficulty” (how difficult the task is to complete). It makes sense to spend our time focusing on the hard, high frequency tasks.
Diagram 4: A 2×2 plot with the axes,”Task frequency” and “Task difficulty”.
The four quadrants are:
Keep: These are low frequency tasks that are easy to complete. We need to make sure that any changes we make don’t have a negative effect on these tasks.
Promote: These are high frequency tasks that are easy to complete: we should encourage marketing to make more of these when describing our product.
Automate: These are low frequency, difficult tasks. We need to ask if there is a way to automate these tasks so that the system can do them on behalf of the user. If not, a Wizard design pattern might simplify the task for users.
Re-design: These are high frequency, difficult tasks. Tasks in this quadrant are the ones we need to fix first.
How to choose a UX research method
We can also use a 2×2 diagram to decide what kind of research method we should carry out. Diagram 5 shows a 2×2 diagram with “Type of research method” plotted against “Type of data”. With “Type of research method” we can classify research methods into behaviour-based methods, and intention (or opinion) based methods. With “Type of data” we can classify research methods into quantitative (“What is happening?”) and qualitative (“Why is it happening?”).
Diagram 5: A 2×2 plot with the axes,”Type of research method” and “Type of data”.
In this example, I’ve placed specific research methods in each quadrant, but these aren’t the only methods you can use. Consider these as examples only.
How to choose a usability evaluation method
Burrowing down further, here’s how we can use a 2×2 to choose a specific kind of usability evaluation method. One of the axes in Diagram 6 is “Our knowledge of users”. Although not an ideal situation, it’s common for product teams to not have a great deal of knowledge about users yet still have a product that they need to evaluate. In that case their knowledge of users is low. In contrast, another product team may have spent time doing field visits to users and so the team knows a thing or two about its users. The other axis is “Urgency”. Sometimes we need an answer in a day or so and other times we have the luxury of a 2-week sprint to find the answer.
This diagram helps us choose between different types of usability test and usability inspection methods.
Diagram 6: A 2×2 plot with the axes,”Our knowledge of users” and “Urgency”.
The four quadrants are:
Lab-based usability test: If our knowledge of users is low, a lab-based test is a good choice, especially when the test is of low urgency. By having users in the lab, we can expose the design team to users and increase their overall awareness of users and their capabilities.
Remote usability test: When our knowledge of users is high and we have more than a few days to work on the issue, then a remote usability test is a good choice.
Cognitive walkthrough: This inspection method makes sense when we have a good knowledge of users and it’s important to get the results urgently. This is because a cognitive walkthrough can be completed in a few hours but it does require a good knowledge of users and their tasks.
Heuristic evaluation: This inspection method offers value when we need quick answers but don’t know a great deal about our users. Instead, we can use standardised usability principles to provide the team with a quick answer.
How to decide what to prototype
I’ve adapted Diagram 7 from Leah Buley’s book, The UX Team of One. It provides a useful way of deciding where, exactly, you should focus when creating a prototype. This speeds up development because you can now prototype only those aspects of the product that are both critical to get right and complex to do well.
Diagram 7: A 2×2 plot with the axes,”Critical to get right and “Complex to do well”.
The four quadrants are:
Use boilerpate: Functions in this quadrant are simple to do and aren’t critical. We can use boilerplate solutions here and not spend time prototyping them.
Use validated patterns: Functions is this quadrant are simple to do and it’s important to get them right. A good choice here would be to use an existing design pattern that we can use out of the box.
Use best judgement: Functions is this quadrant are complex to do well but aren’t critical. We should use our judgement here of whether the function is actually needed.
Prototype these: items in this quadrant are complex to do well and are critical to get right. It makes sense to create prototypes to explore the way these functions could be implemented and test these out with users.
How to simplify the product backlog
The next 3 diagrams provide a useful way to simplify the product backlog by focusing on the value to users. Each 2×2 diagram has the same horizontal axis (“Value to users”).
In Diagram 8, the vertical axis is “Importance to business”. When combined with the “Value to Users” axis, this creates 4 quadrants.
Diagram 8: A 2×2 plot with the axes,”Importance to business” and “Value to User”.
Ignore: Items in this quadrant plot low on both criteria so can be safely ignored.
Explore: items in this quadrant are of importance to the business but offer low value to the user. We need to explore these items further to see how we can adapt them to provide user value.
Research: items in this quadrant are important to users but of low importance to the business. We need to research these items to find out more about the value they provide.
Do now: items in this quadrant offer value to the user and are important to the business, so it makes sense to focus on these first.
In Diagram 9, the vertical axis is now “Ease of implementation”.
Diagram 9: A 2×2 plot with the axes,”Ease of implementation” and “Value to User”.
The four quadrants are:
Ignore: Items in this quadrant plot low on both criteria so can be safely ignored.
Explore: items in this quadrant offer low value to the user but they are relatively easy to implement. We need to explore these items to see if we can adapt them to provide more user value, otherwise there is little point in working on them.
Research: items in this quadrant are important to users but are hard for us to implement. We need to research these items to find out more about the value they provide to see if we can include some of that value in items that are easier to develop.
Do now: items in this quadrant offer value to the user and are relatively easy to implement, so it makes sense to focus on these first.
In Diagram 10, I’ve changed the vertical axis to “Impact on revenue”. This would be an important dimension for a start up trying to identify which functions to prioritise.
Diagram 10: A 2×2 plot with the axes,”Impact on revenue” and “Value to User”.
The four quadrants are:
Ignore: Items in this quadrant plot low on both criteria so can be safely ignored.
Explore: items in this quadrant offer low value to the user but they have a high impact on revenue. We need to explore these items to see if we can adapt them to provide more user value, otherwise they won’t generate the revenue we’re hoping for.
Research: items in this quadrant are important to users but have a low impact on revenue. We need to research these items to find out more about the value they provide to see if we can generate revenue from them.
Do now: items in this quadrant offer value to the user and have a high impact on revenue, so it makes sense to focus on these first.
Bonus diagram: How to make an ethical design choice
We can also use a 2×2 diagram to help us make ethical design decisions about features and workflow. In Diagram 11, the diagram has two axes, “Type of persuasion” and “Who benefits?”. Here’s how we can use it to check if we are making an ethical design choice or manipulating users.
Diagram 11: A 2×2 plot with the axes,”Type of persuasion” and “Who benefits?”
The four quadrants are:
Dark pattern: These are sneaky methods that attempt to manipulate the user into carrying out some action that would be of benefit to the business. A classic example of this would be a pre-checked checkbox adding someone to a mailing list if they buy a product.
Shove: This would include more explicit methods of manipulation that encourage the user into carrying out some action that would be of benefit to the business. An example of this might be a web site that insists you sign up to their mailing list in order to receive an otherwise free report.
Nudge: The difference between a “nudge” and a “dark pattern” is simply that the user (or society) benefits from the situation, rather than the business. An example of this might be automatic enrolment into an organ donation scheme when you apply for a driving license.
Education: These are methods that describe a situation that is of benefit to the user, but still leave it up to the user to take action. For example, UK mobile network provider giffgaff sends its users a text at the end of each month to let them know if they should switch to another data plan, based on their previous month’s usage.
How to create your own 2x2s
Although simple, 2×2 diagrams are a useful way to simplify a complex problem into a small number of alternative choices. But they become even more powerful when you create specific diagrams based on dimensions that are particular to your users and your industry.
Be sure to keep in mind that the most useful dimensions from a UX research perspective tend to focus on the context of use: your users, your tasks and the environments they work in. Indeed, Steve Jobs’ diagram that transformed Apple did just this: its two dimensions were “users” (consumer / professional) and “environment” (desktop / portable).
from Stories by David Travis on Medium https://medium.com/@userfocus/10-diagrams-to-help-you-think-straight-about-ux-research-aa030f7ca41c?source=rss-934fcb05e8b5——2
2019 is the year of DAOs – Now we urgently need robust Consensus protocols for the People
U.S. president Abraham Lincoln (1809–1865) defined democracy as: “Government of the people, by the people, for the people“ Democracy is by far the most challenging form of government — both for politicians and for the people. DAOs are challenging all forms of governance in dimensions we have not seen before.
1. Introduction
Summer of 2018 marked a disastrous moment for blockchain enthusiasts. Remembered as the Black Friday in the history of blockchain, that was the time of crashed crypto prices, declined ICOs and disruption of the crypto bubble. Since then we have witnessed the brutal implementation of Darwin’s Law. The blockchain market healed itself, refrained from weak (and bogus) projects while projects with substance and a strong technological vision survived. There is also much evidence that these kind of projects solving a sophisticated technical challenge and contributing with a solution to affirm decentralization get the support of the community. Although ICOs have been condemned as “dead” after the market crash, projects with strong deep tech vision received nevertheless a descent amount of fundings from the community. Most notable are the ICOs of Fetch.AI and Ocean Protocol raising 6m and 1.8m USD, respectively. Far away from the craze of the past, these are fair numbers for early-stage ventures to showcase the viability of their technology and to prove a product-to-market fit.
2. The Opportunity — DAOs
After the storm comes the sun. 2019 is full of positive energy and innovation. Much hope is given to projects related to Decentralized Autonomous Organizations (DAOs). They lift the core principles of blockchains — decentralization, incentivization and democratization — to the next level. Instead of machines agreeing on the global state of the network, humans agree through a democratic decision on the next state of the community. This idea disrupts the way organisations, governments or enterprises are operated and executed. Consider, for example, a DAO where
devs working within an open source project vote on the integration of code proposals, this way overcoming the interests of a central project owner that tends to guide the development into a direction believing to do right things but his decision stands in sharp contrast with the interests of the community. The mission pursuits, for example, the ditcraft.io project.
fans of a soccer club vote on the budget spent on new players and coaches, this way realizing the dream of governing “their” club instead of accepting the choices of oligarchs who own the club.
Philosophically and technically DAOs implement the very powerful notion – disruption of centralization – with the slight difference that the central parties are rather human authorities, governments or owners. Against this background decentralized autonomous organisations have all what it takes to become the next killer application on top of a blockchain network.
3. The Challenge – Voting Schemes on the Blockchain
At the protocol layer, blockchain networks and DAOs have also much in common.
What a consensus protocol is for blockchain nodes, a voting protocol is for DAO participants.
In fact, one can call a voting scheme a consensus with the additional property of voter privacy. The additional privacy property is necessary to safeguard that the choices made by each voter are taken independently and anonymously. The latter is a prerequisite of the first property and protects voters against rebounds after the ballot.
Comparison of voting schemes for permissionless blockchain. S denotes #stake and K denotes #knowledge tokens.
There are a handful of voting protocols for permissionless blockchains. Yet some research is required to verify their suitability for DAOs.
3.1. The One-Person-One-Vote (1p1v) protocol
Known as the mother of voting mechanisms, the one-person-one-vote scheme is the preferred method to reach a consensus in matters of governance (eg. presidential elections). The scheme permits each eligible voter to cast a vote. Typically a trusted third party (eg. delegates of the government) manage and orchestrate the election. They safeguard the voting follows a protocol of conduct. Once the voting period ended, they count the votes and announce the result following a majority quorum.
One-person-one-vote (1p1v) protocol.
One might be tempted to adapt 1p1v to the blockchain setting. However there are problems with that. In a permissionlessnetwork wallet addresses serve as the only means to identify a voter. As long as no identity layer is in place to link the addresses with real-world identities, 1p1v falls prey to Sybil attacks. In a Sybil attack a malicious voter simply creates multiple wallet addresses, each permitting him to cast a vote in a ballot. Due to the permissionless nature of the blockchain network, such attacks are unavoidable and hence make 1p1v schemes unsuitable for voting schemes.
1p1v is an unsuitable voting mechanism in permissionless blockchains (as long as no identity layer is in place).
3.2. The One-Stake-One-Vote (1s1v) protocol
One-stake-one-vote schemes are the de-facto standard mechanism for votings in permissionless setting. Inspired by proof-of-stake consensus protocols and the fact that a naive adaption of 1p1v to the blockchain fails in a 1s1v protocol each voter deposits a stake. The number of staked tokens weights his vote. The quorum is defined over the decision with majority stake and the stake of the minority is slashed.
One-Stake-One-Voter (1s1v) protocol.
1s1v must be considered with care, as the protocol can harm the democratic choice in DAOs. Though 1s1v remedies the problem of Sybil attacks in 1p1v schemes (there is simply no need anymore for the creation of multiple addresses as the size of the stake dictates the voting power) a new weakness arises. The protocol gives financial oligarchs, that rich voters able to put forth high stakes, a non-negligible advantage to game the outcome of the ballot. In fact, they can hijack the voting mechanism by overstaking all (minority) voters and collect their shares. Such a “voting bot” can easily be automated and be used not only to contaminate the notion of democracy, but also to harvest the stakes of honest voters. One might be tempted to assume limiting the total amount of stake per voter might solve the vulnerability. By casting a Sybil attack an oligarch still can game the outcome of the ballot and thus hijack the protocol.
Rich-get-Richer Attack against 1s1v protocols. A major stake holder can game the outcome of the decision and collect the slashed stake of the minority voters.
3.2 Quadratic Voting (QV) protocol
A radically new idea was proposed by Steven Lalley and Glen Weyl to mitigate the problem of unfair wealth distribution. The authors put forth the beautiful notion of Quadratic Voting. Their idea is based on buying votes. A bit more precise, each voter can buy as many votes he wishes by paying the tokens in a fund with one caveat. The voter has to pay quadratically in the number of votes. The money is then returned to voters on a per capita basis. Suppose, for example, a voter intends to cast 10 votes. Then he pays 10²=100 tokens to acquire the votes. On a high level, the quadratic pricing function acts like a wealth slow down mechanism. Lalley and Weyl have proven under certain assumptions QV to be a mechanism against a tyranny of majority stake holders.
Quadratic voting (QV) protocol
While their results apply to real-world decision makings, transferring the scheme to the permission-less blockchain setting does not carry over with the expected outcome. The problem with the blockchain world are Sybil attacks. The design of blockchain technologies allows a voter to cast many anonymous identities. Hence, to accumulate 10 votes, the sybil attacker simply creates 10 accounts under different identities. This way, the attacker requires 10 tokens in total to cast 10 votes. However, we would like to stress that QV may satisfy the desired outcome in the case of permission-based settings where the identities of the players are known and fixed in advance throughout the lifetime of the system(For example a proof of authority based system).
QV protocols are susceptible to Sybil attacks.
3.4. Knowledge-extractable Voting (KEV) protocol
Inspired by the radically new and brilliant ideas behind QV, knowledge-extractable voting bases decisions on something which is sparse and better suited for blockchain applications — namely knowledge — to achieve a decision (partially) independent of wealth. As opposed to wealth knowledge is acquired through experience or education by perceiving, discovering, or learning. It can’t be bought on an exchange. It can’t be transferred from a knowledgable to less-knowledgable or wealthy person. Moreover, knowledge is non-fungible, as knowledge relates to a particular field of interest and expertise.
Knowledge-extractable voting (KEV) protocol
Knowledge-extractable voting adds to the mechanics of 1s1v protocols a second token, called the knowledge token. A crucial property of knowledge tokens is that they are non-purchasable and non-transferable. The only way to mint knowledge token is to contribute in votings and comply with the decisions of the quorum. If the voter deviates in a ballot from the quorum decision then not only his stake is slashed but also the voters’ knowledge tokens are drastically burned (to the square root). Hence an increased number of knowledge tokens in a particular field allows to quantify the expertise of the voter. It is this expertise that is taken into account to weight the power of the voter in the ballot.
4. Conclusion
Voting schemes are for the stability of DAOs as vital as consensus protocols are for the blockchain network. Looking at the impact voting schemes have for DAOs, it is of crucial interest to understand the security guarantees they provide for blockchain-based applications. We analyzed the suggested voting protocols and concluded that diligence and care must be taken when choosing the right voting scheme. We compared the de-facto voting protocols and concluded that knowledge-extractable voting is an attractive candidate to overcome richer-get-richer attacks on the blockchain. This implies resistance against Sybil attacks a property other stake-based voting schemes fall prey.
Acknowledgement
This is joint work with Marvin Kruse and all animations are his courtesy.
2019 is the year of DAOs was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Hacker Noon https://hackernoon.com/2019-is-the-year-of-daos-9728618873f5?source=rss—-3a8144eabfe3—4
I fund startups for a living and before that I ran two software startups that I founded. I’ve spent countless hours looking at historical finances, budgets, forecasts and future projections. With a standard tech startup I can tell you in my sleep that your two biggest cost items by a long shot are people (between 60–75% of total costs) and space (10–20% of total costs). The only other significant cost item that I see in some early-stage startups is inventory (for hardware or eCommerce companies).
In the earliest stages of a company a startup will often cram as many people into small rooms as is possible in order to conserve on office costs. When a company raises capital it inevitably begins to look for office space in order to increase worker productivity and happiness. Because it’s hard to predict how much space you’ll need as you expand (or, gulp, downside) startups have increasingly turned to shared spaces like WeWork, which act a bit like cloud hosting in that they allow you scale up or scale down as your business expands or slows down.
Anybody who has spent time around startups can tell you that there are bunch of productivity drains that can come from these environments:
Lack of meeting space for having discussions
Inability to concentrate due to being surrounded by “loud talkers”
Huge lines waiting at shared security check-ins, elevators or lunch lines
Knowing the problems of “managing people around spaces” was one of the primary reasons I backed the company Density, who built a “depth sensor” that hangs above doors and anonymously tracks spaces as seen in the GIF below.
The technology is now deployed across many clients including LinkedIn, NYU, Dropbox, Envoy and many others so we’ve learned a lot about how people use solutions like Density to increase productivity, improve physical security and better match space with people. Below are some great examples of common problems & solutions we’ve seen:
The meeting room camper / the meeting room squatter / phantom
Gartner estimates the average employee spends 27 hours/year looking for available spaces to meet — this is rarely because companies don’t have enough space. Most often, it’s because they don’t have the right mix of small / large / flex working space and as a result people tend to hog space when it is available.
Once organizations scale they inevitably implement systems to make booking shared spaces more streamlined and usually more democratic — the general procedure being that you “book a meeting room” by the hour via a scheduling system. We’ve all experienced the “squatter” who just goes into a meeting room and startups working on takes a 1–1 meeting in a room built for 12 and doesn’t bother booking it. Some people go the opposite route and book hours on end so that they can “camp” in a meeting room to get long periods of quiet work done or take 1–1 meetings at the expense of group needs.
Equally problematic is the “phantom” who books the meeting room for hours on end to block the room, only using it periodically. I saw this kind of behavior even 20 years ago when I worked at Accenture where staff was mostly at client sites but when they returned to the office there was a rush to phantom book the limited meeting rooms.
At Density we worked with clients to integrate into their Outlook system so management could better evaluate when teams booked meeting room space and then compare against the Density sensor data to see when the room was actually used. It can compare hours booked vs. used as well at number of people booked vs. attended with the goal of helping the enterprise better manage its limited space resources.
The lunch conundrum
Another major productivity drain as companies scale (or as shared work spaces fill up) are lunch lines. We have seen the rise in companies using Density to better track the flow of people through the commissaries at breakfast, lunch and dinner. They have integrated this with internal systems on Slack or Facebook Messenger to allow employees to check the wait times in real time and plan their days accordingly. This has also helped management figure out how to staff up restaurant staff in peak hours. We’ve even seen some forward thinking airlines and travel companies use these sensors to better track the staffing levels of lounges throughout the day.
The tailgater
Most offices employ physical security to protect both assets and safety yet we’ve all witnessed the “tailgater” who waits for somebody else to scan his or her card and then walks quickly behind them and gets access. This is much harder to do in high-rise buildings with sufficient security guards but even there after-hour problems persist. As you’ll see in the video below, Dropbox has used Density paired with its access-control system to flag for security whenever there is a tailgater. In the video they show a real-life situation (faces blurred) where a tailgater posing as just another employee looking at his smart phone who then broke in and stole several laptops. This problem is even more pronounced on campuses where buildings have more ingress & egress points. Dropbox was having more than 100 tailgating events / week and while most of these are likely not nefarious, having employees become aware of the problem is the first line of defense.
The wasted space / the oversized meeting rooms
Perhaps the group that most values the ability to know how people use spaces are the facilities management groups responsible for space planning. As businesses expand you naturally find meeting rooms built for 12 but used mostly for 2–4 people at a time that would more effectively be built at 2 meeting rooms. We see companies that do large acquisitions and have to figure out how to consolidate companies and staff. During a customer pilot, a Fortune 1000 company discovered that an 8-person conference room was used by 3 or fewer people for 78% of all business hours; it was used by 8 people (its intended capacity) just 3% of the time. By expanding the study and right-sizing their conference room mix, this company is likely to solve their meeting room problem and save tens of millions of dollars in avoided real estate expansion costs.
The insurance risk
Have you ever noticed when you walk into a bar, concert hall, stadium or similar venue and there is a person with a counter that clicks when you walk through? Almost certainly what they’re doing is manually monitoring crowd sizes for insurance (and ultimately for safety) purposes.
We now have venues using Density to control crowd sizes and ensure they aren’t violating their insurance policies. A bar we work with was getting multiple $1,000 fines from the Fire Dept every month for being over capacity — this despite having staff on hand to count manually. After installing Density, the fire marshal looked at the count on the bar manager’s iPhone and said, “that’s really cool.” He then left them alone because they could prove they were in compliance w/ the code.
Unintended use cases
By now, we’ve seen a lot! From people wanting Density to track that Alzheimer’s patients aren’t moving outside of a pre-agreed space to gig-economy companies wanting to be able to anonymously track whether their workers or whether their customers are initiating unwanted physical contact. People often ask me, “why don’t they just use cameras?” Of course there are some good uses for cameras in fields like surveillance but in the modern world there are many places where we want to track the flow of people (bathroom usage, just one example!) but don’t want to record people. In addition, the ability to interpret the data and deal with the volumes of information is much more cost-effective when you’re dealing with “polygons” (shapes from a laser) than dealing with full video footage.
from Both Sides of the Table https://bothsidesofthetable.com/why-you-cant-get-serious-about-productivity-unless-you-optimize-how-your-people-use-your-space-d07d1d1fb6a2?source=rss—-97f98e5df342—4

 Watching how people interact with an interface tells you a lot about what works and what needs improvement.
Watching how people interact with an interface tells you a lot about what works and what needs improvement.