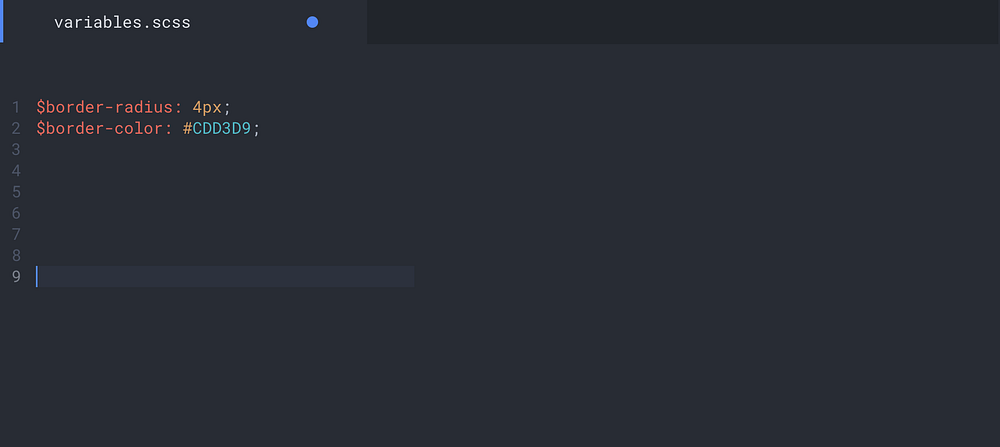
Exploring rendering differences between Sketch and iOS
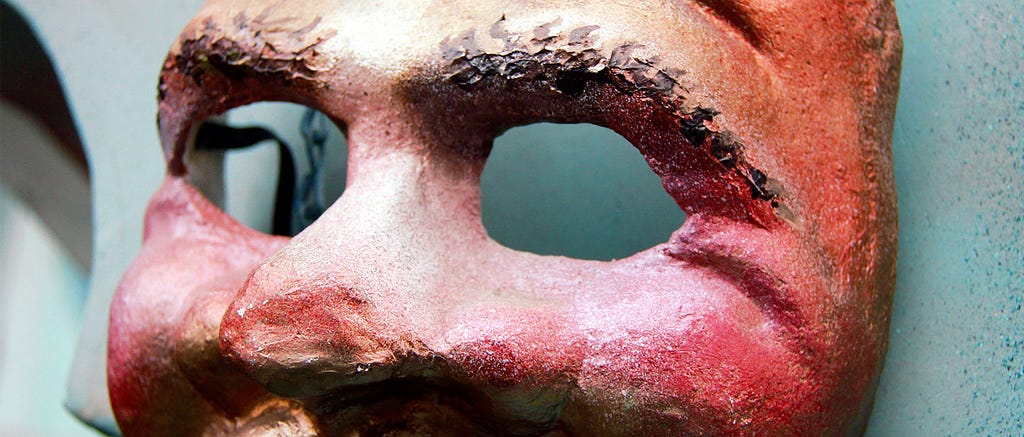
Can you spot the differences between these two images?
If you look hard enough, you might notice a few subtle differences:
The image on the right:
- Has a larger shadow.
- Has a darker gradient.
- Has the word “in” on the top line of the paragraph.
The image on the left is a screenshot from Sketch, and the image on the right is a reproduction on iOS. These differences arise when the graphics are rendered. They have the exact same font, line spacing, shadow radius, colors, and gradient attributes — all of the constants are identical.


As you can see, some aspects of the original design can be lost during the conversion from the design file to real code. We’re going to explore some of these details so you can know what to watch for and how to fix them.
Design is critical to a successful mobile app. Especially on iOS, users are accustomed to apps that work well and look good.
If you’re a mobile app designer or developer, you know how important small details are to the end user experience. High-quality software can only come from people who care deeply about their craft.
There are many reasons why apps might not look as good as their original designs. We’re going to investigate one of the more subtle reasons — differences in rendering between Sketch and iOS.
Certain types of user interface elements have noticeable differences between Sketch and iOS. We are going to explore the following elements:
- Typography
- Shadows
- Gradients
Typography can be implemented in various ways, but for this test I am going to use labels (“Text” element in Sketch, UILabel in iOS).
Let’s look at some of the differences:
The biggest difference in the example above is the location of line breaks. The third grouping of text starting with “This text is SF Semibold” breaks after the word “25” in the design, but after the word “points” in the app. This same problem occurs with the paragraph of text—the line breaks are inconsistent.
Another smaller difference is that the leading (line spacing) and tracking (character spacing) are slightly larger in Sketch.
It’s easier to see these differences when they are directly overlaid:


What about other typefaces? Replacing San Francisco with Lato (a widely used free font), we get the following results:


Much better!
There are still some differences in leading and tracking, but these are generally small. Be careful though—if the text needs to align with other elements like background images, these small offsets can be noticeable.
How To Fix
Some of these issues are related to the default iOS font: San Francisco. When iOS renders the system font, it automatically includes tracking based on the point size. This automatically-applied tracking table is available on Apple’s website. There is a Sketch plugin called “SF Font Fixer” which reflects these values in Sketch. I highly recommend it if your design uses San Francisco.
(Side Note: Always remember to make the text box wrap tightly around text in Sketch. This can be done by selecting the text and toggling between “Fixed” and “Auto” alignment, then resetting the width of the text box. If there is any extra spacing, this can easily lead to incorrect values being entered into the layout.)
Unlike typography which has universal layout rules, shadows are less well-defined.
As we can see in the image above, shadows in iOS are larger by default. In the examples above, this makes the most difference on the top edges of the rectangles.
Shadows are tricky because the parameters between Sketch and iOS are not the same. The biggest difference is that there is no concept of “spread” on a CALayer, although this can be overcome by increasing the size of the layer that contains the shadow.
Shadows can vary wildly in their difference between Sketch and iOS. I’ve seen some shadows with the exact same parameters look great in Sketch but be nearly invisible when running on a real device.

How To Fix
Shadows are tricky and require manual adjustment to match the original design. Oftentimes, the shadow radius will need to be lower and the opacity will need to be higher.
// old
layer.shadowColor = UIColor.black.cgColor
layer.shadowOpacity = 0.2
layer.shadowOffset = CGSize(width: 0, height: 4)
layer.shadowRadius = 10
// new
layer.shadowColor = UIColor.black.cgColor
layer.shadowOpacity = 0.3
layer.shadowOffset = CGSize(width: 0, height: 6)
layer.shadowRadius = 7
The required changes vary based on size, color, and shape — here, we only need a few minor adjustments.
Gradients prove to be troublesome as well.
Of the three gradients, only the “orange” (top) and “blue” (bottom right) differ.
The orange gradient looks more horizontal in Sketch, but more vertical in iOS. As a result, the overall color of the gradient is darker in the final app than the design.
The difference is more noticeable in the blue gradient—the angle is more vertical in iOS. This gradient is defined by three colors: light blue in the bottom left corner, dark blue in the middle, and pink in the top right corner.

How To Fix
The start and ending points may need to be adjusted if the gradient is angled. Try offsetting the startPoint and endPoint of your CAGradientLayer slightly to account for these differences.
// old
layer.startPoint = CGPoint(x: 0, y: 1)
layer.endPoint = CGPoint(x: 1, y: 0)
// new
layer.startPoint = CGPoint(x: 0.2, y: 1)
layer.endPoint = CGPoint(x: 0.8, y: 0)
There’s no magic formula here*—the values need to be adjusted and iterated until the results visually match.
*Jirka Třečák posted an excellent response with links explaining how the gradient rendering works. Check it out if you want to dive deep into more code!
I built a demo app to easily see these differences on a real device. It includes the examples above, along with source code and original Sketch file so you can tweak the constants to your heart’s content.
This is a great way to increase awareness within your team—just hand them your phone and they can see for themselves. Simply touch anywhere on the screen to toggle bewteen the images (similar to the gifs above).
Get the open-source demo app here: https://github.com/nathangitter/sketch-vs-ios
Don’t assume that equal values imply equal results. Even if the numbers match, the visual appearance may not.
At the end of the day, there needs to be iteration after any design is implemented. Good collaboration between design and engineering is crucial for a high-quality end product.
Enjoyed the story? Leave some claps 👏👏👏 here on Medium and share it with your iOS design/dev friends. Want to stay up-to-date on the latest in mobile app design/dev? Follow me on Twitter here: https://twitter.com/nathangitter
Thanks to Rick Messer and David Okun for revising drafts of this post.
from Medium https://medium.com/@nathangitter/why-your-app-looks-better-in-sketch-3a01b22c43d7