

A paradigm shift is happening that will change the way companies store, compute and transmit data. This shift will give birth to a plethora of new opportunities, including solutions to the most persistent problems faced by big tech companies and users alike. This article will explore one such opportunity — the creation of the first truly decentralized graph database. In addition to being scalable, cost-effective, and secure, this technology will allow users to manipulate and retrieve their data in a trustless, permissionless way.
This is not another story complaining about large technology companies violating data ethics. Rather it seeks to empathize with both users and companies and understand why they act the way they do, from economical, social and technological perspectives.
The Rise and Fall of Data
The rise of ubiquitous computing has been accompanied by an exponential increase in the rate of personal data production. From checking into social media on our phones to interacting with the Echo device sitting in our apartments, even our most mundane activities produce an enormous amount of data.
The question that isn’t being asked enough is — “What happens to that data once it is created?”. The answer varies from company to company, but in many instances our collective data is being misused by the very companies storing it or being hacked by malicious third parties. Facebook is a classic example: the platform has not only suffered major data breaches, affecting millions; but has also sold data to its partners without explicit user consent.

This is obviously a huge problem for both users and companies implicitly charged with protecting said data. Yet, users are not leaving these platforms and the companies are not making any significant changes. Why?
Users: The Illusion of Control & Ownership
There exist plenty of alternatives to Facebook on the Internet. So why is it that most of its users feel compelled to stay after the latest series of scandals?
I, and many others, believe it is mostly due to the “walled gardens” problem: after spending the last X years on *insert large tech company name here* users have uploaded and amassed huge amounts of data, such as friends, photos, memories, that cannot be easily transferred to a different platform. Users deleting their account means losing access to data that they thought belonged to them, because while they might own the content they post, they don’t own the “relationships” it creates on the platform.
Furthermore, most users are not concerned enough about their privacy, with respect to large corporations, to take action. It’s a trade off; for users’ lack of privacy is rewarded with free services, personalized products and ads. Most users don’t really feel like they have anything important to hide, so they willingly upload their data under the illusion that they “control” it.
The companies that create the products that generate and receive our data for free take a “carrot and stick” approach to data collection. You get additional features if you provide them with your data (hyper-personalization of services), and if you do not click “I Agree” to a 50 page document of Legalese, this may render your already-paid-for device or service useless. If the 21st century startup world has taught us anything, it’s that user experience reigns supreme.
Lastly, let’s face it, there is no guarantee that a newer, smaller, alternative startup with the same services will suffer from fewer data breaches than companies who dedicate millions of dollars every year to security.
Companies: The Advent of Cloud Computing
You would think that companies, on the other hand, would’ve taken significant steps to ensure data security after the last series of high profile data breaches. Yet, here we are, hearing about new hacks every other week.
The advent of cloud computing has led companies to store data in highly centralized data centers. Cloud computing saved companies billions of dollars; however, it came at the cost of having a single point of failure. This also meant that hackers now knew exactly where find users’ data. In the end, knowing that users wouldn’t be able to leave their platform, the decision to trade a little bad publicity for billions of dollars was an easy one.
Tech companies have also gotten into the habit of selling user data to their partners without requesting explicit user consent. Is this a problem users can even avoid? Users pay companies for their free services with their attention and time, by watching ads, and with their data. Some great projects like Solid, spearheaded by the inventor of the World Wide Web, Sir Tim Berners-Lee, are looking to solve this problem and are pushing for true control over our data.
However, Amazon, Google, Facebook and Apple — the “Big 4” of tech — have a monopoly over our data and have no intention of relinquishing this measure of control. Big tech companies are disincentivized to grant users total ownership and control of their data, as doing so would not only bring down those “walled gardens” but would sever another important, if not dominant, revenue stream: the ability to sell your data and the insights generated from it at no additional costs.
In the end, all of the decisions that have and are being taken are rooted purely in economic reasoning, as they often are with public companies.
A Paradigm Shift: Speed, Security & Cost
A paradigm shift is happening in the tech world that will change how companies store their data. Google and other tech companies are starting to hit a bandwidth wall within their own data centers. Simply put, they are reaching their maximum capacity when it comes to processing and transporting data.
On the other hand, every year, the personal computing devices surrounding us are becoming more and more powerful; many of these devices sitting idle most of the time. When connected in a coordinated way they can, and will, outperform any current data center in terms of speed, security and most importantly, cost.
Harnessing effectively the unused computing power of these devices wouldn’t spell the immediate end of the Cloud Computing era but would rather complement it, especially for latency sensitive tasks. It would also, however, announce the birth of the “Fog Computing” era (coined by Cisco in January 2014).
Fortunately, because Fog Computing relies on decentralized networks, it is also theoretically much harder to hack, thereby solving the security problem.
Fog Computing versus Cloud Computing
At a high level Fog Computing will initially work exactly like Cloud Computing for Big Tech companies: users will create, read, update and delete their data by submitting a request to the company who will in turn pass it on to the decentralized network of devices. This is the way things were done when Cloud Computing was king and there is no immediate apparent reason to do otherwise.
However, as we saw before, one of the main reasons people are staying on their current platforms is because no viable alternatives exist that would guarantee a better outcome. Fog Computing makes that assumption obsolete. Your data is now stored on thousands of devices across the world; and therefore, rather than passing through an intermediary such as a Big Tech company for your data, you can directly make request to the network of devices. A permissionless, trustless way to access your data.
This also means that by corresponding directly with a decentralized network, you can decide with much more granularity who has access and the rights to use your data: the Holy Grail of data ownership.
Why would the Big Tech companies want to allow you to communicate with the decentralized network then? Well, long story short, they don’t. However, this technology is being built and will readily be available to the public. Competition that offers this type of data control at scale will emerge, and since Big Tech companies’ data centers will not provide them with the same competitive advantages they do today, their entire business model will be in danger of being disrupted.
They will be forced to offer their users granular data control in order to stay competitive. This means giving users the option to either monetize their data, give it away for free or refuse entirely to have it used for any other purpose than the core services offered. This sacrifice’s cost pales in comparison to losing users entirely to competitors in the same market.
Blockchains Revisited
Blockchains have recently entered the spotlight as the first technology making use of decentralized networks of devices. Promising users full ownership and monetization of their data, blockchains are ostensibly compelling alternatives to legacy third party data farms. So why aren’t we all using blockchain technology? I believe this is simply because we misunderstand what blockchains are supposed to help us with.
Blockchains have been lauded as secure, immutable and transparent databases. Yet a blockchain can only hold very small amounts of data without having the computers hosting it run out of memory, and becoming centralized. Furthermore, blockchains are extremely hard to query; this is partly because data is stored in blocks with varying time stamps, but also because there exist no “easy” innate querying languages. Simply put, it is neither efficient nor easy to search blockchains for information.
Imagine a medical company needs to access blockchain data as fast as possible, it would likely first move the data to an efficient third party database, then execute its queries; thereby completely destroying the concept of decentralization. Blockchains are best suited to payment or purely transaction-based systems.
Indeed, that is what they were initially invented for: Bitcoin, a payment system with a relatively small digital footprint. While blockchains make use of the growing movement of increasingly powerful personal devices, they have a relatively narrow use case and do not make use of the paradigm shift’s full potential.
This is not to say that all blockchains are useless in the quest for more control over our data. A much broader use case emerged for blockchains when Ethereum was born.

As you can see on the left, the prices for storing data on it are still outrageous. However, it introduced a revolutionary new concept: smart contracts, which, as we will see later on, are extremely handy when used in conjunction with decentralized storage solutions.
A Decentralized Graph Database
In order to accelerate the transition to the future described above, where each user is granted new levels of data ownership and control, we also need the associated technology: a decentralized network of devices that users can communicate with directly. Amongst its other features it should be private (for user data when needed), scalable (in terms of storage and computing power) and trustless (you don’t have to trust a central authority to access your data or to maintain its security). It would serve as the backend for products that could rival the user experience provided by Big Tech companies.
I had been thinking for a while for a solution to this conundrum, and, while working for Graphen, I produced a whitepaper (with the help of Columbia University Master students Peiqi Jin and Yang Yang) for a decentralized database.
This decentralized database functions exactly like a cloud database from the developer’s perspective; however, it is hosted on a completely peer to peer network. It is not a blockchain, but leverages some of the same cryptographic algorithms, such as Patricia-Merkle trees. I won’t expound on the technical details, the whitepaper is there for that, but it essentially consists of three parts:
- The workers, who rent out storage space and computational power to host fragments of the database and compute queries. They are called masternodes and receive monetary rewards such as US dollars or cryptocurrencies in exchange for their hardware’s time. They are also incentivized to periodically check each other’s data and query results in order to guarantee the correctness of the overall system.
- The users, who are usually developers or scientists, that create the databases. They are the ones that usually pay the fees to the masternodes.
- The users that contribute data to a given database, through an app or directly, via requests to the masternodes. They can be the same as the previous users. They are also provided with a private key that allows them to retain full ownership of their information (the ability to request, delete or update their data with a request to the network without the permission of a third party).
I believe that graph databases are the future. With each passing day our world is becoming more interconnected, and so is the data we produce. Graph databases’ speciality lie in accommodating these relationships. Furthermore, all other “types” of data fit in graph databases: unstructured and structured data, while more efficiently manipulated in non relational and relational databases, respectively, can be stored in graph databases too (the converse is not true, eg. graph data cannot be stored in a non relational database).
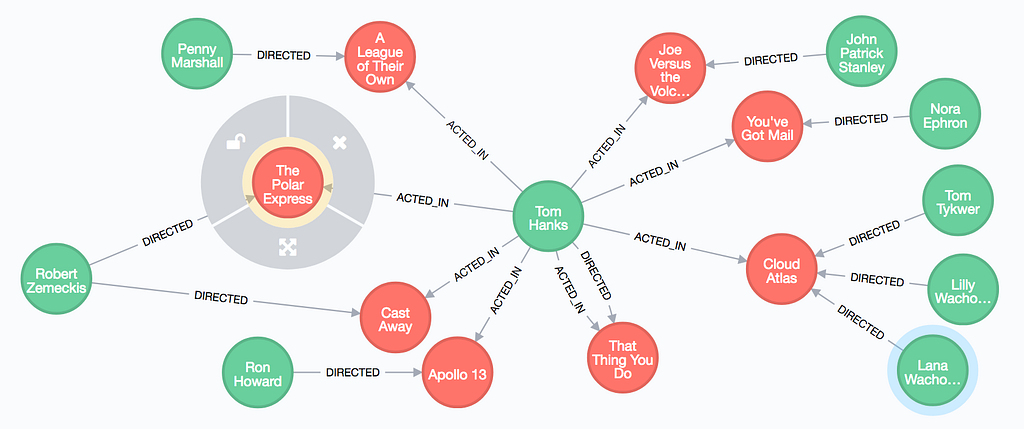
The applications of graph databases have been increasing significantly over the past few years. For example, graph databases are already being used by Facebook for their social media platform, by Stripe for fraudulent transactions, by Amazon for product recommendation and by companies all over the world for big data analytics in various domains and problems.
Graph databases are extremely fast, scalable and can generate incredible insights from the data they contain; which is why I chose them first to be implemented as decentralized, distributed databases.
This decentralized graph database fulfills all of our aforementioned necessary features: scalability, trustlessness and privacy (by using a specific type of homomorphic encryption).
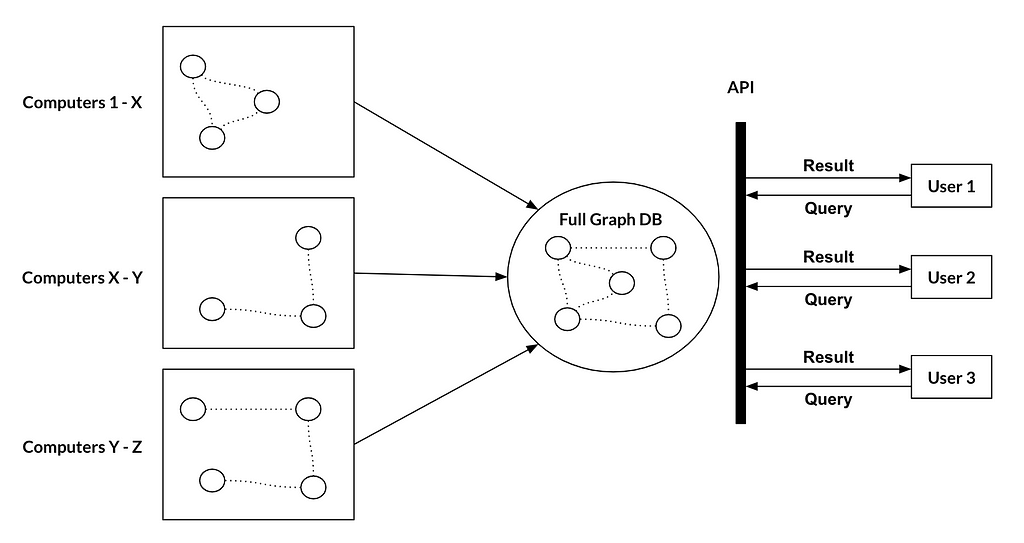
This is a very high level overview of what the data flow looks like:
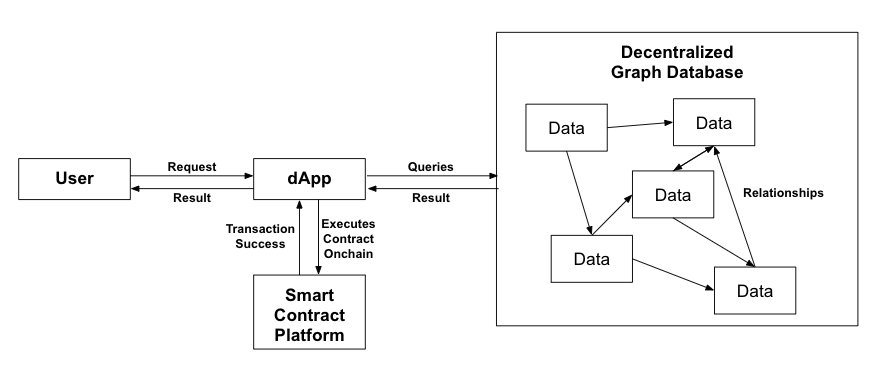
A Truly Decentralized Internet
If we look at current Web 2.0 applications, we have a frontend, a backend and a database. While it doesn’t make much sense to decentralize the frontend, the backend logic can and should be decentralized. This is where smart contract platforms come in. Turing complete (theoretically able to solve any computation problem) smart contract platforms such as Ethereum, EOS or Cardano have the capability to support this logic with their native programming language. They can even correspond with the graph database to retrieve relevant data in a truly decentralized manner.
Ultimately, if this technology matures as intended, it could even become the very basis for the new semantic Internet Tim Berners Lee, the inventor of the Internet, describes in his Ted Talk.
“So, linked data — it’s huge. I’ve only told you a very small number of things.
There are data in every aspect of our lives, every aspect of work and pleasure, and it’s not just about the number of places where data comes, it’s about connecting it together.
And when you connect data together, you get power in a way that doesn’t happen just with the web, with documents.”
Thanks for taking the time to read this article! The whitepaper is available at www.graphenprotocol.com. Please don’t hesitate to contact me at mgavaudan@graphen.ai with any feedback or questions you might have.
We are in the process of raising money for a Graphen subsidiary that will specialize in this technology, so if you are an investor please email me for our pitch deck.
I’d also like to thank Dr. Jie Lu, Dr. Ching-Yung Lin, and all my other friends (Matteo, Kai, Haley, Kevin, Srikar, Eric, Lizzie…) for their help and feedback throughout this process.
The Future of Data: A Decentralized Graph Database was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Hacker Noon https://hackernoon.com/the-future-of-data-a-decentralized-graph-database-bbb668715bd1?source=rss—-3a8144eabfe3—4