
An Underestimated Timesaver for Sketch
Today we, digital designers, have a terrific opportunity to use real data — or generated — on our daily work. We can test and iterate our design solutions faster and in a better way for everyone. The days of Lorem Ipsum are long gone, thank God.
You can save hours of your time, provide better solutions faster and save the company’s money by using such functionality. In addition, even the most boring mockups come to life in seconds. Those of you who have used Sketch Data or Framer’s database “integration” knows what I’m talking about. However, both these features are useless if there are no proper datasets available.
I decided to fix that, and have created 320 various datasets, sorted and structured for ease of use with Sketch,
without destroying your workflow with buggy 3rd-party plugins. So if you’re designing a social, travel, tech, nature, urban, fin, or any other project, this article and datasets I’m providing will be really helpful!
Make sure to check out the videos below before diving into the details. So you will understand the beauty of Sketch Data feature on a few examples.
Let’s go 👇
—
It’s nice to have a date & time generator like Craft, for instance. However, for different cases, you need to use different formats of date representation like:
• 06 May 2019
• 06/05/2019
• 06/05/2019 18:00
• 06/05/2019 6:00 PM
• May 6, 2019
• Mon, 6th of May
• 2 hours ago
• Last week, etc.
For instance, if you’re designing a messenger app, more likely than not, you need to use relative time (e.g. 15 min ago) and a shortened but still readable date format (e.g. May 4, 11:35) instead of 06/05/2019 6:01:33, right?
It’s actually quite the opposite, if you’re working on a travelling project, you should be really specific in date & time and use 06 May 2019, 3:15 PM. Or for a huge database, the format like 2019/05/06 might be the case.
Step 1.
To generate date & time datasets at various formats I used the following formulas and Google Sheet.
Cell A1: =DATE(2018,10,30)
Cell A2: =A1+1
Obviously, this one is aimed at generating a date starting from the 30th of October 2018 with one day step for each next cell. To get a valid date starting from today, change A1 to =CurrentDate.
=TIME(RandBetween(8,24), MROUND(RandBetween(1,59),5),0)
This one is for a random time between working hours (8–21 hours) with minutes multiples of 5, just to make it a little bit prettier.

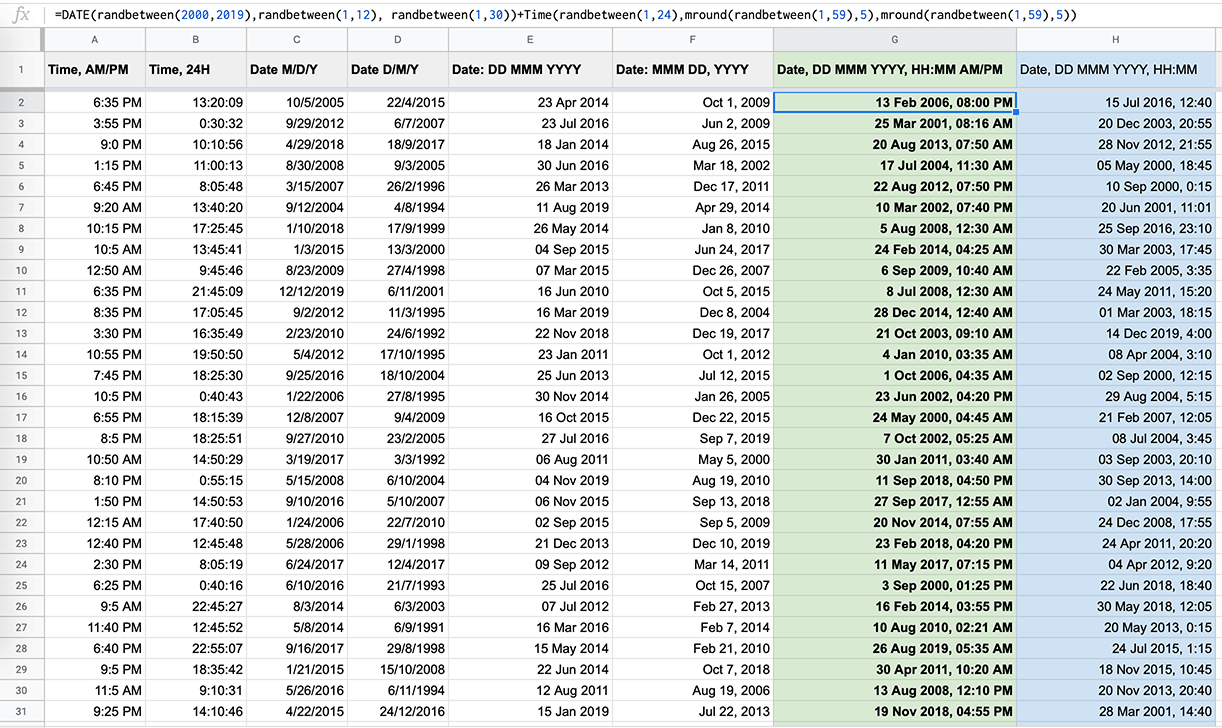
=DATE(randbetween(2018,2019), randbetween(1,12), randbetween(1,30))+TIME(randbetween(1,24), mround(randbetween(1,59),5), mround(randbetween(1,59),5))
This one is a bit more complex and generates a random date and time in a format 2019.04.04 18:40:10 where minutes and seconds are multiple of 5. Now it can be easily changed to any other format (e.g. 4 Apr 2019, 2:35 PM).
Step 2.
When I’ve all the needed formats/styles ready, I duplicate them to 100 rows to get a big enough list of randomly generated dates & times. Then all I need to do is to copy and paste them to the appropriate .txt files and save.
Here is a quick tutorial of how to create, save and connect a dataset:
This one is more interesting. To generate the full names, I’ve prepared 4 columns:
Column B: 1000 Male first names
Column D: 200 Male last names
Column F: 1000 Female first names
Column G: 200 Female last names

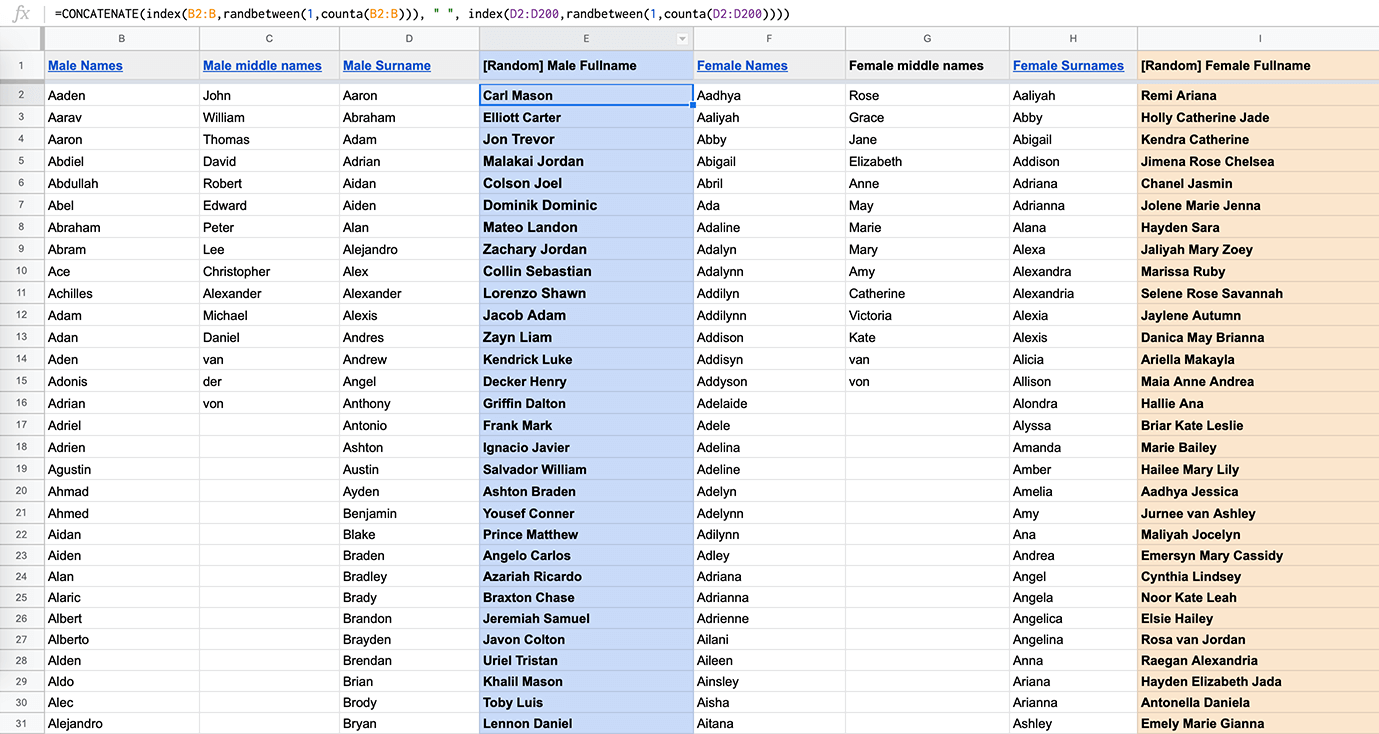
With the formula below, I generate a full name (both male and female) by randomly taking the values from the appropriate columns and combining them into one string value divided by space.

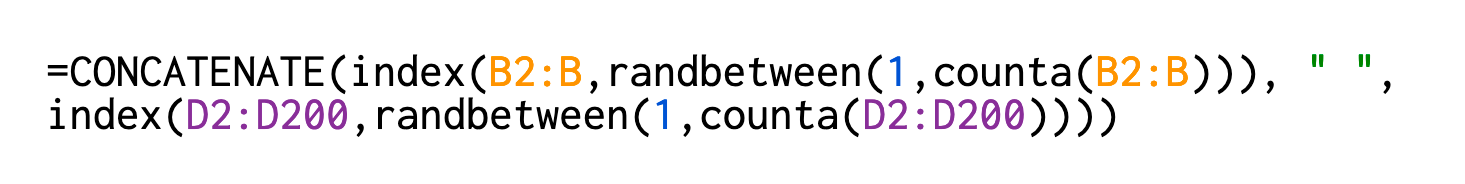
Okay. So now you have 2 separate lists. But what if you need a mix of both male and female full names? Easy. With the following formula, I’m just expanding the range from where to take the first and last names. Now generative full names for my dataset are ready.


Now the trickiest one. So, how can one generate emails properly by ensuring any coincidences (at least to minimize them as much as possible) with the real/taken emails in terms of privacy and GDPR? Sounds tough, huh?
To do so, I’ve added 3 more columns (up to 4 previously mentioned with names) with the following values:
Column K: 100 Randomly generated numbers (1–100 range)
Column L: English Alphabet is written in sounds (e.g. ei, bi, ci…)
Column M: 160 popular email service providers

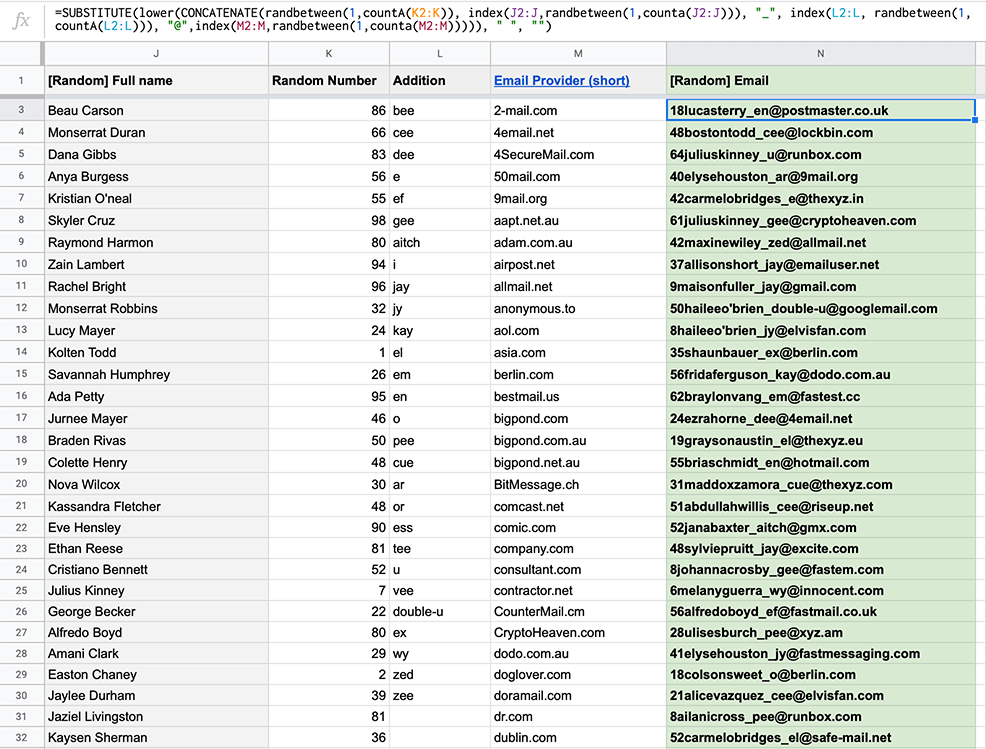
Now, with the formula below, I’m combining everything into a randomly generated emails like 32bengamindelee_ach@fastimap.com.

Here is the breakdown:
- substitute — removes spaces from the full names (column J)
- lower — makes each letter lowercase
- concatenate — combines the values into a single string
- index+counta — takes string values from needed columns
- randbetween — randomly takes the values among the mentioned columns
I’ve divided texts into 6 topics: design, motivation, nature, sport, tech, and travel. The difficulty here was about copyrights so far as someone’s materials couldn’t be used for any commercial purposes, unless they are from free-for-use resources. And because of the topics, I had to find a way to generate meaningful texts on my own. However, I have found another solution.
https://talktotransformer.com/ — this is a neural network that generates quite good texts based on a short message of some topic. Let’s say you need a few paragraphs of text about motivation. You can start with “Teach yourself to be a mentor. Your team still respects you enough to hear you and to keep moving in one direction but with fun and no bias.” And you will get the following:

So, I’ve grabbed some sentences from my own articles, fed them to this neural network and got the needed amount of texts for my dataset. The copyrights are not violated and no one has been injured 🙃
When datasets are ready, they needs to be connected to Sketch. It’s really easy to do.
1. Go to Settings ⇢ Data ⇢ Add Data tab.
2. Choose needed datasets or folders. Done.
I advice you to connect a root folder or at least the nested folders. In that way, it will be easier to update them and keep the structure clear. If you’ll add, let’s say, one more date format to your folder, it will automatically appear in Sketch Data list. But do not connect the datasets (.txt files) one-by-one. It ain’t Cool.
You can spend some time to create/generate such datasets on your own. Or 👉grab mine, already prepared, sorted, and structured for your convenience. Here is the list of datasets you will get:
1. Names
• Male full, first and last names
• Female full, first and last names
• Full Names — mix
2. Date & Time
• Date in various formats (e.g. 20/05/2019, 20 May 2019)
• Time in various formats (e.g. 12:32:34, 11:17 AM)
• Time relative (e.g. Last month, 2h ago)
• Time Zones (e.g. EET+2, GMT+1, UTC-3)
• Duration (e.g. 45h 30, 37 min)
3. Devices
• Device type
• Apple devices (iPhones, iPads, MacBooks)
• Samsung phones
• Display models, resolutions, refresh rate, matrix type, etc.
• Mix of mobile devices
• iOS and Android OS versions
4. Cities & countries
• Countries worldwide
• Countries AMER, APAC, EMEA regions
• Countries capitals
• Countries 2-, 3-letter and numeric codes
• US States, their capitals and cities
• Cities of 8 countries (China, France, Germany, Italy, Japan, Spain, Ukraine)
• All names localized to 8 languages (DE, EN, ES, FR, IT, JA, UK, ZH) 🤩
5. Tech: File sizes
• Random 10–500 KB
• Random 10–800 MB
• Random 1–500 GB
• Random 1–20 TB
6. Random Numbers
• 1–10
• 10–100
• 10–300
• 10–999
• 100–9999
7. Phone Numbers
• Random Phone numbers
• Country codes
8. Currencies & Prices
• Currencies codes, symbols and names
• Worldwide currencies sorted by code, name, country
• Prices (e.g. $16, 403 €, £800)
9. Languages
• Languages 2- and 3-letter codes (e.g. ES, ENG)
• Languages native names
• All names localized to 8 languages (DE, EN, ES, IT, JA, UK, ZH) 🤗
10. Messages & Texts
• Random short messages with 8 localizations!
• Generated paragraphs of texts on various topics
11. Airports
• Airports (most popular and worldwide) IATA codes
• Airports sorted by names, cities, and countries
• US popular airports sorted by IATA codes, names, and cities.
—
Here is the list of some functions that might be useful:
• Randbetween (A,B) — randomly gets a value between A and B.
• Mround (A, B) — rounds the value A to value B.
• CountA (a, b) — allows to count the number of certain values within a specific data range. Use it to count string values.
• Concatenate (A1, “:”, B1) — combines values from A1 and B1 cells and puts a colon between them.
• SUBSTITUTE — search to needed text among needed values.
• (A:A) — values from the entire A column.
• (A:C) — values from the entire A, B and C columns.
• ({A10:A100, D:D, F2:F}) — the multiple ranges of values from column A cells 10–100 AND the whole column D AND the whole column F excluding cell F1.
To summarize: using Sketch Data with the meaningful dataset is a smart and fast way to fulfill your designs with the proper data in seconds. No more hassle with the manual filling repeated text blocks for you and your team!
In addition, I’ll be adding more specific datasets and formats in the future. It will be available for Framer as well. So consider following me on Gumroad for valuable updates.
From the cons, I would mention only one. You could not save a specific or alphabetical order of values. Sketch taking values randomly. However, I’m pretty sure, the Sketch team will fix all that soon, right? 🙂
Please, encourage free knowledge sharing by 👏 !
from Medium https://medium.com/@justd/sketch-data-4d22f823253c